







文章:https://arxiv.org/abs/1412.7024
0 摘要
乘法器是深度神经网络数字实现中空间和功耗最大的算术运算符。我们在三个基准数据集上训练了一套最先进的神经网络(Maxout网络):MNIST,CIFAR-10和SVHN。它们采用三种不同的格式进行训练:浮点,固定点和动态固定点。对于每个数据集以及每种格式,我们评估乘法的精确度对训练后最终误差的影响。我们发现,非常低的精度不仅适用于运行训练好的网络,也适用于训练它们。例如,可以使用10位乘法训练Maxout网络。
1 简介
深度神经网络的训练通常受到硬件的限制。许多以前的工作解决了通用硬件的最佳利用,通常是CPU集群(Dean等人,2012)和GPU(Coates等人,2009; Krizhevsky等人,2012a)。更快的实施通常会导致最先进的结果(Dean等人,2012; Krizhevsky等人,2012a)。
实际上,这些方法总是包括使算法适应最佳利用现有技术的通用硬件。尽管如此,一些专用的深度学习硬件也出现了。FPGA和ASIC实现声称比通用硬件具有更好的功率效率(Kim等人,2009; Farabet等人,2011; Pham等人,2012; Chen等人,2014a; b)。与通用硬件相比,ASIC和FPGA等专用硬件可以从算法构建硬件。
硬件主要由存储器和算术运算符组成。乘法器是深度神经网络数字实现中空间和功耗最大的算术运算符。本文的目的是评估降低深度学习乘数精度的可能性:
- 我们用低精度乘法器和高精度累加器训练深度神经网络(第2节)。
- 我们使用三种不同的格式进行实验:
- 浮点(第3节)
- 定点(第4节)
- 动态定点,我们认为是浮动点和固定点之间的良好折衷(第5节)
- 我们在更新期间使用比前向和后向传播更高的参数精度(第6节)。
- Maxout网络(Goodfellow等,2013a)是一套最先进的神经网络(第7节)。我们在三个基准数据集:MNIST,CIFAR-10和SVHN(第8节)上训练Maxout网络的容量略低于Goodfellow等人(2013a)。
- 对于三个数据集中的每一个以及三种格式中的每一种,我们评估乘法精度对训练的最终误差的影响。我们发现,非常低精度的乘法不仅足以运行训练好的网络,而且足以训练它们(第9节)。我们提供了代码https://github.com/MatthieuCourbariaux/deep-learning-multipliers。
2 乘法运算
应用深度神经网络(DNN)主要包括卷积和矩阵乘法。因此,DNN的关键算术运算是乘法累加运算。人工神经元基本上是乘法器 - 累加器,计算其输入的加权和。
定点数乘法器的成本随着的精度(其操作数)的平方而变化,而加法器和累加器的成本是精度的线性函数(David et al。,2007)。因此,定点数乘法累加器的成本主要取决于乘法器的精度,如表1所示。在现代FPGA中,乘法也可以用专用的DSP模块/片实现。一个DSP模块/片可以实现单个27×27乘法器,两个18×18乘法器或三个9×9乘法器。因此,降低精度可以使现代FPGA内可用乘法器的数量增加3倍。
在本文中,我们使用低精度乘法器和高精度累加器训练深度神经网络,如算法1所示。

3 浮点数

浮点格式通常用于表示实际值。它们包括符号,指数和尾数,如图1所示。指数给出了浮点格式的宽范围,尾数为它们提供了良好的精度。可以使用以下公式计算单个浮点数的值:
v
a
l
u
e
=
(
−
1
)
s
i
g
n
×
(
1
+
尾
数
2
23
)
×
2
(
指
数
−
127
)
value = (-1)^{sign} \times (1+\frac{尾数}{2^{23}})\times2^{(指数-127)}
value=(−1)sign×(1+223尾数)×2(指数−127)
表2显示了与每个浮点格式相关的指数和尾数宽度。在我们的实验中,我们使用单精度浮点格式作为参考,因为它是深度学习中使用最广泛的格式,尤其是GPU计算。我们证明了半精度浮点格式的使用对神经网络的训练几乎没有影响。在撰写本文时,半精度浮点格式下面没有标准存在。

4 定点数
固定点格式包括有符号尾数和所有固定点变量之间共享的全局比例因子。缩放因子可以看作小数点的位置。它通常是固定的,因此称为“固定点”。缩小比例因子会缩小范围并增加格式的精度。为了计算效率,缩放因子通常是2的幂(缩放乘法用移位代替)。因此,定点格式也可以看作具有唯一共享固定指数的浮点格式,如图1所示。固定点格式通常在没有FPU(浮点单元)的嵌入式系统上找到。它依赖于整数运算。它的硬件方式比浮点计算量小,因为指数是共享和固定的。
5 动态定点数
在训练深度神经网络时,激活值、梯度和参数的变化范围比较大。在训练期间,梯度范围逐渐减小。因此,具有唯一共享固定指数的定点格式不适合深度学习。
动态定点格式(Williamson,1991)是定点格式的变体,其中有几个缩放因子而不是单个全局缩放因子。那些缩放因子不固定。因此,它可以被视为浮点格式( 其中每个标量变量拥有在每个操作期间更新的缩放因子)和定点格式(其中只有一个永远不会更新的全局缩放因子)之间的折衷。对于动态固定点,一些分组变量共享一个比例因子,该比例因子不时更新以反映该组中值的统计数据。
在实践中,我们将每个层的权重,偏差,加权和,输出(非线性变化之后)和相应的梯度向量、矩阵与不同的比例因子相关联。这些缩放因子用全局值初始化。在训练期间也可以使用更高精度的格式找到初始值。在训练期间,我们按照算法2中描述的策略以给定的频率更新缩放因子。

6 更新和传播
我们在更新期间使用比前向fprop和后向传播bprop更高的参数精度。这背后的想法是能够累积参数的小变化(这需要更高的精度),而另一方面,在fprop期间节省了内存带宽。这可以通过在训练期间通过随机梯度下降执行的隐式平均来完成:
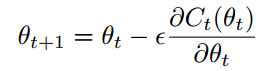
迭代的最后参数是:
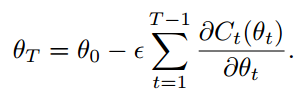
这个和的项不是统计独立的(因为θt的值取决于θt-1的值),但主要的变化来自于小批量中的随机样本(θ移动缓慢),因此需要强大的平均效果,并且总和中的每个贡献相对较小,因此需要足够的精度(当添加大量的小数字时)。
7 Maxout
Maxout网络是一个多层神经网络,在其隐藏层中使用maxout单元。maxout单元输出k个权重向量与输入向量(例如,前一层的输出)之间的一组k个点乘积的最大值:
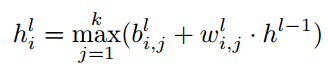
其中h1是层1的激活矢量,权重矢量 w i , j l w_{i,j}^l wi,jl和偏差 b i , j l b_{i,j}^l bi,jl是层 l l l上的单元 i i i的第 j j j个滤波器的参数。
maxout可以看作是relu的泛化:
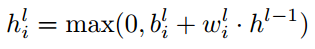
即,设置maxout函数中的k=2且强迫一个滤波器参数为0。结合dropout(一种非常有效的正则化方法(Hinton等,2012)),maxout网络在许多基准测试中取得了最先进的成果。dropout技术提供了模型平均的良好近似,模型集是参数共享的原始无噪声深度网络单元的子集形成的指数级网络。
8&9 实验结果

9.1 浮点数
半精度浮点格式对测试集错误率几乎没有影响,如表4所示。我们推测高精度微调可以恢复错误率的小幅下降。
9.2 定点数



固定点的最佳小数点位置在第五个(或可以说是第六个)最重要的位之后,如图2所示。相应的范围约为[-32,32]。相应的缩放因子取决于我们使用的位宽。固定点传播的最小位宽为19(带符号的20)。低于此位宽,测试设置错误率会急剧上升,如图3所示。固定点中参数更新的最小位宽为19(带符号为20)。低于此位宽,测试集错误率会急剧上升,如图4所示。在MNIST数据集上使用隐藏单元数量加倍的网络也不允许进一步减少位宽。最后,对于传播和参数更新,使用19(带符号的20)位对最终测试错误几乎没有影响,如表4所示。
9.3 动态固定点

我们通过更高精度格式的训练找到初始缩放因子。找到这些缩放因子后,我们重新初始化模型参数。我们每10000个示例更新一次缩放因子。增加最大溢出率允许我们减少传播位宽,但它也显着增加了最终的测试错误率,如图5所示。因此,我们在其余实验中使用0.01%的低最大溢出率。动态固定点中传播的最小位宽为9(符号为10)。低于此位宽,测试集错误率会急剧上升,如图3所示。动态固定点中参数更新的最小位宽为11(加符号为12)。低于此位宽,测试集错误率会急剧上升,如图4所示。将隐藏单元的数量加倍不允许在MNIST上进一步减小位宽。最后,使用9(带符号的10个)位进行传播,使用11个(带符号的12个)位进行参数更新对最终测试错误几乎没有影响,但SVHN数据集除外,如表4所示。这明显优于定点格式,这与我们对第5节的预测一致。
11 结论
我们已经证明:
•极低精度乘数足以训练深度神经网络。
•动态定点似乎非常适合训练深度神经网络。
•在更新期间使用更高的参数精度有帮助。
我们的工作可以用于:
•优化通用硬件上的内存使用(Gray et al。,2015)。
•设计专用于深度学习的高能效硬件。















 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









