




 博客围绕深层神经网络展开,指出深层网络中存在内部协变量偏移问题,即之前层参数变化会使当前层输入分布改变。为解决该问题,可对每层进行归一化操作。重点介绍了批量归一化方法,包括原理、操作及注意事项,还提及参考资料《神经网络与深度学习》。
博客围绕深层神经网络展开,指出深层网络中存在内部协变量偏移问题,即之前层参数变化会使当前层输入分布改变。为解决该问题,可对每层进行归一化操作。重点介绍了批量归一化方法,包括原理、操作及注意事项,还提及参考资料《神经网络与深度学习》。
0.概述
- 深层神经网络存在的问题(从当前层的输入的分布来分析):在深层神经网络中,中间层的输入是上一层神经网络的输出。因此,之前的层的神经网络参数的变化会导致当前层输入的分布发生较大的差异。在使用随机梯度下降法来训练神经网络时,每次参数更新都会导致网络中每层的输入分布发生变化。越是深层的神经网络,其输入的分布会改变的越明显。
- 解决方法(归一化操作):从机器学习角度来看,如果某层的输入分布发生了变化,那么其参数需要重新学习,这种现象称为内部协变量偏移。为了解决内部协变量偏移问题,就要使得每一层神经网络输入的分布在训练过程中要保持一致。最简单的方法是对每一层神经网络都进行归一化操作,使其分布保持稳定。
1.批量归一化
- 协变量偏移介绍
- 在传统机器学习中,一个常见的问题是协变量偏移。协变量是一个统计学概念,是可能影响预测结果的统计变量。在机器学习中,协变量可以看作是输入。一般的机器学习算法都要求输入在训练集和测试集上的分布式相似的。如果不满足这个假设,在训练集上学习到的模型在测试集上的表现会比较差,如下图所示:
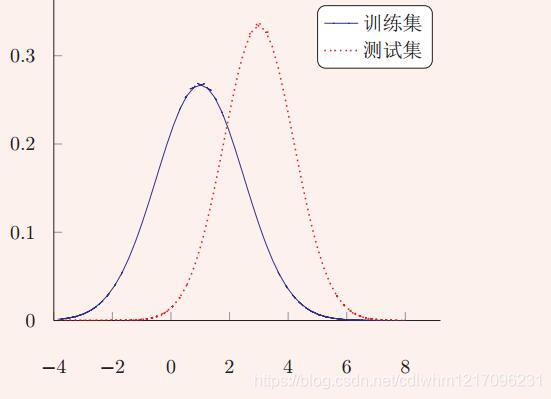
- 在传统机器学习中,一个常见的问题是协变量偏移。协变量是一个统计学概念,是可能影响预测结果的统计变量。在机器学习中,协变量可以看作是输入。一般的机器学习算法都要求输入在训练集和测试集上的分布式相似的。如果不满足这个假设,在训练集上学习到的模型在测试集上的表现会比较差,如下图所示:
- BN原理介绍
- 批量归一化方法是一种有效的逐层归一化的方法,可以对神经网络中任意的中间层进行归一化操作。对一个深层神经网络来说,令第l层的净输入为
z
(
l
)
\mathbf{z}^{(l)}
z(l), 经过激活函数后的输出是
a
(
l
)
\mathbf{a}^{(l)}
a(l),即
a ( l ) = f ( z ( l ) ) = f ( W a ( l − 1 ) + b ) \mathbf{a}^{(l)}=f\left(\mathbf{z}^{(l)}\right)=f\left(W \mathbf{a}^{(l-1)}+\mathbf{b}\right) a(l)=f(z(l))=f(Wa(l−1)+b)
其中, f ( ⋅ ) f(\cdot) f(⋅)是激活函数,W和b是权重和偏置参数。 - 为了减少内部协变量偏移问题,就要使得净输入
z
(
l
)
\mathbf{z}^{(l)}
z(l)的分布一致,比如都归一化到标准正态分布。虽然归一化操作可以应用在输入
a
(
l
−
1
)
\mathbf{a}^{(l-1)}
a(l−1)上,但其分布性质不如
z
(
l
)
\mathbf{z}^{(l)}
z(l)稳定。因此,在实践中归一化操作一般应用在仿射变换之后,在下一次激活函数之前。利用数据预处理方法对
z
(
l
)
\mathbf{z}^{(l)}
z(l)进行归一化,相当于每一层都进行一次数据预处理,从而加速收敛速度。但是,逐层归一化需要在中间层进行操作,要求效率比较高,因此复杂度比较高的白话方法就不太合适。为了提高归一化效率,一般使用标准归一化,将净输入
z
(
l
)
\mathbf{z}^{(l)}
z(l)的每一维都归一到标准正态分布。
z ^ ( l ) = z ( l ) − E [ z ( l ) ] var ( z ( l ) ) + ϵ \hat{\mathbf{z}}^{(l)}=\frac{\mathbf{z}^{(l)}-\mathbb{E}\left[\mathbf{z}^{(l)}\right]}{\sqrt{\operatorname{var}\left(\mathbf{z}^{(l)}\right)+\epsilon}} z^(l)=var(z(l))+ϵz(l)−E[z(l)]
其中, E [ z ( l ) ] \mathbb{E}\left[\mathbf{z}^{(l)}\right] E[z(l)]和 var ( z ( l ) ) \operatorname{var}\left(\mathbf{z}^{(l)}\right) var(z(l))是当前参数下, z ( l ) \mathbf{z}^{(l)} z(l)的每一维度在整个训练集上的期望和方差。因为目前主要的训练方法是基于Mini-Batch的随机梯度下降算法,所以准确地计算 z ( l ) \mathbf{z}^{(l)} z(l)的期望和方差是不可行的。因此, z ( l ) \mathbf{z}^{(l)} z(l)的期望和方差通常用当前小批量Mini-Batch样本集的均值和方差近似估计。 - 给定一个包含K个样本的小批量样本集合,第l层神经元的净输入
z
(
1
,
l
)
\mathbf{z}^{(1,l)}
z(1,l),…,
z
(
K
,
l
)
\mathbf{z}^{(K,l)}
z(K,l)的均值和方差为:
μ B = 1 K ∑ k = 1 N z ( k , l ) σ B 2 = 1 K ∑ k = 1 K ( z ( k , l ) − μ B ) ⊙ ( z ( k , l ) − μ B ) \begin{aligned} \mu_{\mathcal{B}} &=\frac{1}{K} \sum_{k=1}^{\mathrm{N}} \mathbf{z}^{(k, l)} \\ \sigma_{\mathcal{B}}^{2} &=\frac{1}{K} \sum_{k=1}^{K}\left(\mathbf{z}^{(k, l)}-\mu_{\mathcal{B}}\right) \odot\left(\mathbf{z}^{(k, l)}-\mu_{\mathcal{B}}\right) \end{aligned} μBσB2=K1k=1∑Nz(k,l)=K1k=1∑K(z(k,l)−μB)⊙(z(k,l)−μB) - 对净输入
z
(
l
)
\mathbf{z}^{(l)}
z(l)的标准归一化会使得其取值集中到0附近,如果使用sigmoid激活函数时,这个取值区间刚好是接近线性变换区间,从而减弱了神经网络非线性变换的性质。因此,为了使归一化操作不对网络的表示能力造成负面影响,可以通过一个附加的缩放和平移变换改变取值区间。
z ^ ( l ) = z ( l ) − μ B σ B 2 + ϵ ⊙ γ + β ≜ B N γ , β ( z ( l ) ) \begin{aligned} \hat{\mathbf{z}}^{(l)} &=\frac{\mathbf{z}^{(l)}-\mu_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^{2}+\epsilon}} \odot \gamma+\beta \\ & \triangleq \mathrm{B} \mathrm{N}_{\gamma, \beta}\left(\mathbf{z}^{(l)}\right) \end{aligned} z^(l)=σB2+ϵz(l)−μB⊙γ+β≜BNγ,β(z(l))
其中, γ \gamma γ、 β \beta β分别表示缩放和平移的参数向量。从最保守的角度考虑,可以通过标准归一化的逆变换来使得归一化的变量可以被还原为原来的值。即:当 γ = σ B 2 \gamma=\sqrt{\sigma_{\mathcal{B}}^{2}} γ=σB2, β = μ B \beta=\mu_{\mathcal{B}} β=μB时, z ^ ( l ) = z ( l ) \hat{\mathbf{z}}^{(l)}=\mathbf{z}^{(l)} z^(l)=z(l)。 - 批量归一化操作可以看作是一个特殊的神经网络层,该层是加在每一层非线性激活函数之前,即:
a ( l ) = f ( B N γ , β ( z ( l ) ) ) = f ( B N γ , β ( W a ( l − 1 ) ) ) \mathbf{a}^{(l)}=f\left(\mathbf{B} \mathbf{N}_{\gamma, \beta}\left(\mathbf{z}^{(l)}\right)\right)=f\left(\mathbf{B} \mathbf{N}_{\gamma, \beta}\left(W \mathbf{a}^{(l-1)}\right)\right) a(l)=f(BNγ,β(z(l)))=f(BNγ,β(Wa(l−1)))
其中,因为批量归一化本身具有平移变换,因此非线性变换 W a ( l − 1 ) W \mathbf{a}^{(l-1)} Wa(l−1)就不再需要偏置参数b。 - 注意:每次小批量样本的 μ B \mu_{\mathcal{B}} μB和 σ B 2 \sigma_{\mathcal{B}}^{2} σB2是净输入 z ( l ) \mathbf{z}^{(l)} z(l)的函数,而不是常量。因此,在计算参数梯度时,需要考虑 μ B \mu_{\mathcal{B}} μB和 σ B 2 \sigma_{\mathcal{B}}^{2} σB2的影响。当训练完成时,用整个数据集上的均值 μ \mu μ和方差 σ 2 \sigma^{2} σ2来分别替代每次小批量样本的 μ B \mu_{\mathcal{B}} μB和 σ B 2 \sigma_{\mathcal{B}}^{2} σB2。在实际中, μ B \mu_{\mathcal{B}} μB和 σ B 2 \sigma_{\mathcal{B}}^{2} σB2也可以使用移动平均来计算。
- 批量归一化方法是一种有效的逐层归一化的方法,可以对神经网络中任意的中间层进行归一化操作。对一个深层神经网络来说,令第l层的净输入为
z
(
l
)
\mathbf{z}^{(l)}
z(l), 经过激活函数后的输出是
a
(
l
)
\mathbf{a}^{(l)}
a(l),即

















 2039
2039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









