







批归一化(Batch Normalization)
Batch Normalization (labml.ai)
Labml.ai是实现论文笔记与代码结合的一个网站,上面有许多的示例可供参考进行论文实现。
(1)理论介绍
Batch Normalization(批归一化)是一种常用的深度学习中的技术,用于加速神经网络的训练并提高模型的性能。它通过在网络中的每个隐藏层对输入进行归一化处理,使得每个神经元的输入分布更稳定,从而有助于网络的收敛和训练效果。
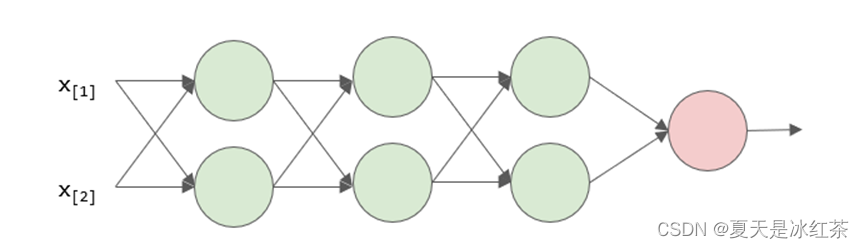
图7 三层神经网络
这是一个三层的神经网络,输入是x1,x2 构成的向量x=[x1,x2]T ,x 也被称为一个训练样本,在训练过程中,假设所有的样本一共有30个,每一次会从训练样本集合中选取五个X={x1,x2,x3,x4,x5} 进行随机梯度下降,那么这五个样本所构成的集合就叫做一个批量(batch),假设输入样本的batch服从这样一个奇怪的分布:

图8 样本分布示意图
在经过层层网络的非线性变换之后,每层学习到的分布都将无法预测,并且在网络学习的过程中,每一层的输出是前一层网络的输入,因此由于参数的更新,每层的输入分布都在发生变化,导致网络的很难收敛,为了让网络可以正常的训练,就需要学习率不能设置的太高、每层网络的参数初始化设定要准确,而且网络层数不能过多。
这种现象的出现是由于每层分布的差异过大,并且无法预测导致的,那么如果让同一个batch中,样本在每一层中都服从类似的分布,就可以解决这个问题吗?是可以的,这就是2015年提出的batch normalization批量归一化方法。
假设在一个batch中包含了x1 到x5 这五个样本,其中任意一个元素xi 通过第一层神经网络线性变换后得到输出,那么由z1 到z5 构成的集合
,就是第二层网络的输入,在进行下一层运算之前,我们首先计算着五个值的中间结果的平均值和标准差。
通过减去均值并处以标准差的方法,将每个样本归一化到均值为0,标准差为1的分布中,为了稳定数值计算,我们需要在分母中加一个小量,以避免分母出现为0的情况,同时,我们也并不希望每层样本的分布都相同,因此在通过一个线性计算进行简单的分布变化,其中伽马和贝塔是可以学习的参数。
随着训练过程的自动调整,这就是batch normalization的运算过程。如果我们在每一层网络中都进行闭n归一化,那么就可以保证每一层输入的分布都是类似的,我们就可以使用较大的学习率,尝试不同的参数初始化方法,并且加速训练过程,这里需要注意两个问题。首先,bn算法中额外的引入了两个需要学习的参数伽马和贝塔,因此需要反向传播更新的参数从两个变为了四个,但是在归一化过程中需要减低所有向量的均值,因此偏执b向量可以不用参与运算,实际需要更新的变量是三个,另外需要注意的一点是这里的神经元不止进行了一个线性变换,它实际包含了三个运算:
线性变换
分布归一化
非线性激活
理论上来讲,后面两个的顺序并不是固定的,以上是对batch normalization在训练阶段运算的讨论,在测试推理阶段,我们仍可以使用训练得到的伽马和贝塔这两个参数,但因为训练集和测试集的样本并不完全一致,并且我们可能仅仅使用一个样本进行测试,无法计算均值和标准差,因此我们需要保存并使用训练过程中的结果来辅助运算。假设我们有30个样本,每五个样本构成一个batch进行训练,完整遍历,一次训练集就需要6个batch,那么对于每一层神经网络来说,我们会得到6个均值的历史数值,接下来通过指数加权的方式,获得这6个均值的平均值。
第t次的均值等于1-m乘以t-1次的均值加上m乘以第t次迭代的历史数值,这里的m可以看作是对历史的保留,非常类似于随机梯度下降中动量的概念。
在torch框架中也将这个变量命名为momentum,默认值是0.1。
(2)nn.BatchNorm2
BatchNorm2d是PyTorch中的一个类,用于在卷积神经网络中进行批量归一化操作。它可以用于二维卷积层的输入数据。
BatchNorm2d的参数如下:
num_features(int):输入特征的数量。对于二维卷积层,这通常是卷积核的通道数。 数学表达为(N、C、H、W)
eps(float,可选):分母中添加的值,用于数值稳定性。默认值为1e-5。
momentum(float,可选):用于计算移动平均的动量。默认值为0.1。
affine(bool,可选):如果设置为True,表示对归一化的结果应用可学习的仿射变换。 默认值为True。
track_running_stats(bool,可选):如果设置为True,表示对训练期间的每个通道计算 并跟踪统计信息(均值和方差)。默认值为True。
注:以上为torch的帮助文档内容
(3)总结及分析
Batch Normalization批量归一化方法可以加速神经网络的收敛,使训练过程中对学习率和参数初始化更加鲁棒,但它也有一些缺陷。
- bn算法仅在batch中包含样本数量足够多的时候才有效。
- 对于循环神经网络(RNN)或序列数据(Sequence)性能较差。
- 分布式运算也有影响。
为了应对bn算法的缺陷,后续又提出了
- Layer Normalization:在每一个样本特征空间内的归一化。
- Instance Normalization:在每一个样本特征空间内逐通道的归一化。
- Group Normalization:LN于BN的结合。
















 4883
4883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











