










二维卷积的算法原理比较简单,参考任意一本数字信号处理的书籍,而matlab的conv2函数的滤波有个形状参数,用下面的一张图很能说明问题:
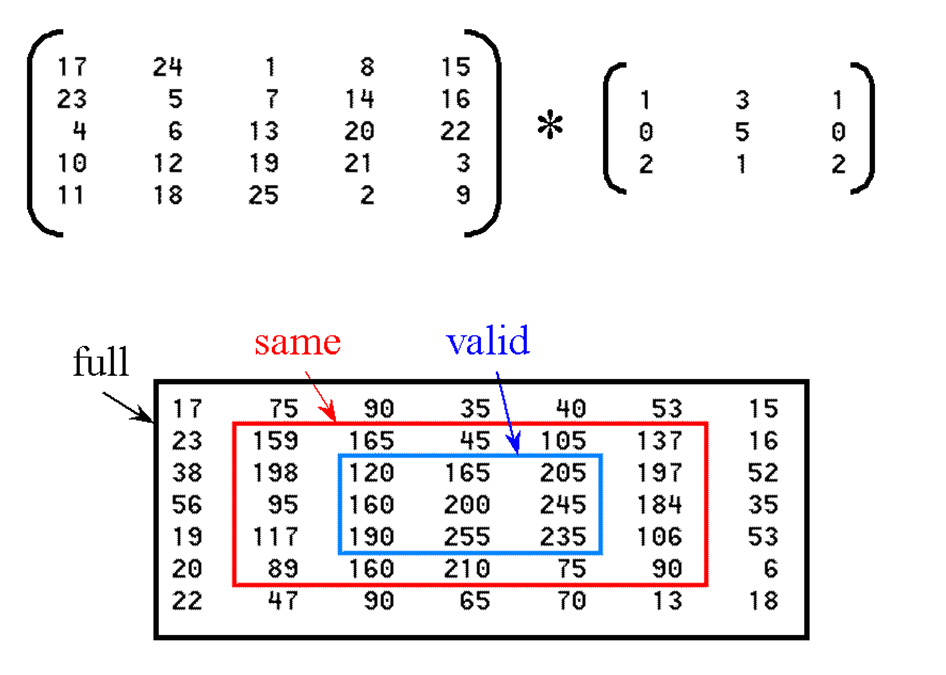
这里给出一种最原始的实现方案。这种实现对于数据矩阵大小为1000x1000,卷积核矩阵大小为20x20,在我的机器上需要大约1秒钟的时间,而matlab采用的MKL库最快只需要将近0.1s的时间。下面的代码用到了自己目前开发的FastIV中的一些函数接口。具体代码如下:
#include "fiv_core.h"
typedef enum{
FIV_CONV2_SHAPE_FULL,
FIV_CONV2_SHAPE_SAME,
FIV_CONV2_SHAPE_VALID
}FIV_CONV_SHAPE;
void fIv_conv2(fIvMat** dst_mat, fIvMat* src_mat, fIvMat* kernel_mat, FIV_CONV_SHAPE shape)
{
int src_row = src_mat->rows;
int src_cols = src_mat->cols;
int kernel_row = kernel_mat->rows;
int kernel_cols = kernel_mat->cols;
int dst_row = 0, dst_cols = 0, edge_row = 0, edge_cols = 0;
int i,j, kernel_i,kernel_j,src_i,src_j;
fIvMat* ptr_dst_mat = NULL;
switch(shape){
case FIV_CONV2_SHAPE_FULL:
dst_row = src_row + kernel_row - 1;
dst_cols = src_cols + kernel_cols - 1;
edge_row = kernel_row - 1;
edge_cols = kernel_cols - 1;
break;
case FIV_CONV2_SHAPE_SAME:
dst_row = src_row;
dst_cols = src_cols;
edge_row = (kernel_row - 1) / 2;
edge_cols = (kernel_cols - 1) / 2;
break;
case FIV_CONV2_SHAPE_VALID:
dst_row = src_row - kernel_row + 1;
dst_cols = src_cols - kernel_cols + 1;
edge_row = edge_cols = 0;
break;
}
ptr_dst_mat = fIv_create_mat(dst_row, dst_cols, FIV_64FC1);
*dst_mat = ptr_dst_mat;
for (i = 0; i < dst_row; i++) {
ivf64* ptr_dst_line_i = (ivf64* )fIv_get_mat_data_at_row(ptr_dst_mat, i);
for (j = 0; j < dst_cols; j++) {
ivf64 sum = 0;
kernel_i = kernel_row - 1 - FIV_MAX(0, edge_row - i);
src_i = FIV_MAX(0, i - edge_row);
for (; kernel_i >= 0 && src_i < src_row; kernel_i--, src_i++) {
ivf64* ptr_src_line_i,*ptr_kernel_line_i;
kernel_j = kernel_cols - 1 - FIV_MAX(0, edge_cols - j);
src_j = FIV_MAX(0, j - edge_cols);
ptr_src_line_i = (ivf64*)fIv_get_mat_data_at_row(src_mat, src_i);
ptr_kernel_line_i = (ivf64*)fIv_get_mat_data_at_row(kernel_mat, kernel_i);
ptr_src_line_i += src_j;
ptr_kernel_line_i += kernel_j;
for (; kernel_j >= 0 && src_j < src_cols; kernel_j--, src_j++){
sum += *ptr_src_line_i++ * *ptr_kernel_line_i--;
}
}
ptr_dst_line_i[j] = sum;
}
}
}
FIV_ALIGNED(16) ivf64 ker_data[4*4] = {0.1,0.2,0.3,0.4,
0.5,0.6,0.7,0.8,
0.9,1.0,1.1,1.2,
1.3,1.4,1.5,1.6};
void test_conv2()
{
fIvMat* src_mat = fIv_create_mat_magic(8, FIV_64FC1); // 8x8 magic matrix
fIvMat* kernel_mat = fIv_create_mat_header(4, 4, FIV_64FC1);
fIvMat* dst_mat = NULL;
fIv_set_mat_data(kernel_mat, ker_data, (sizeof(ivf64)) * 4 * 4);
fIv_conv2(&dst_mat, src_mat, kernel_mat, FIV_CONV2_SHAPE_FULL);
fIv_export_matrix_data_file(dst_mat,"dst_mat_4x4-full.txt", 1);
fIv_release_mat(&src_mat);
fIv_release_mat(&kernel_mat);
fIv_release_mat(&dst_mat);
}
int main()
{
test_conv2();
return 0;
}10月24日更新:
目前FastIV中的实现已经经过优化,最快速度在我的机器上已经超越MATLAB。















 1533
1533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









