



简介
通义千问系列模型为阿里云研发的大语言模型。千问模型基于 Transformer 架构,在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在预训练模型的基础之上,使用对齐机制打造了模型的 chat 版本。其中千问-1.8B 是 18 亿参数规模的模型,千问-7B 是 70 亿参数规模的模型,千问-14B 是 140 亿参数规模的模型,千问-72B 是 720 亿参数规模的模型。
Qwen1.5
Qwen1.5 是 Qwen 开源系列的下一个版本。与之前的版本相比,Qwen1.5 显著提升了聊天模型与人类偏好的一致性,改善了它们的多语言能力,并具备了强大的链接外部系统能力。DashScope 上提供 API 服务的是新版本 qwen 模型的 chat 版本,在 chat 能力上大幅提升,即便在英文的 MT-Bench 上,Qwen1.5-Chat 系列也取得了优秀的性能。
Qwen2
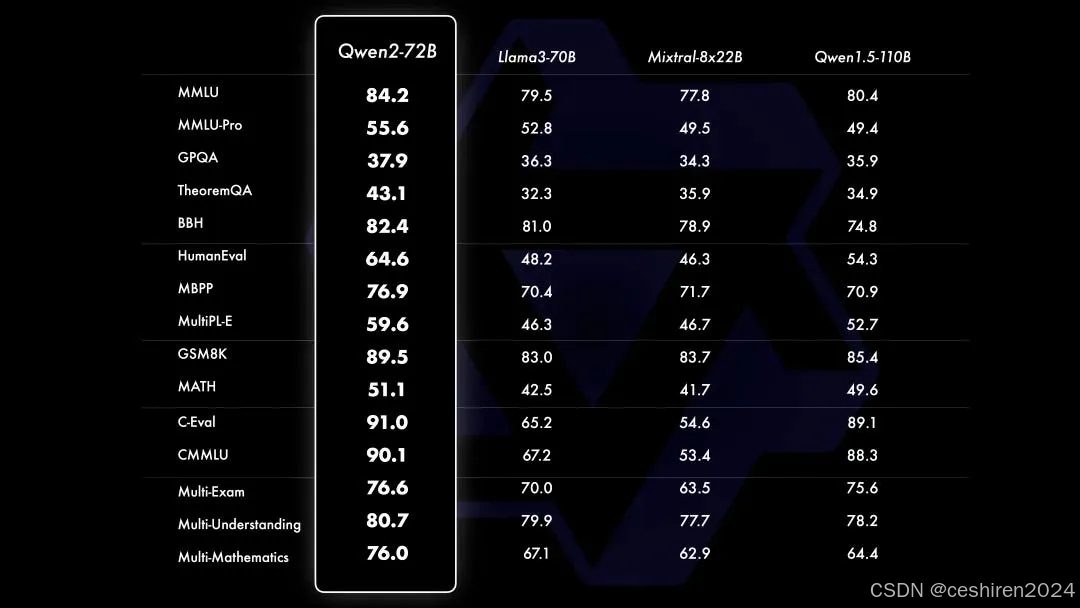
Qwen2 参数范围包括 0.5B 到 72B,包括 MOE 模型。Qwen2 在一系列针对语言理解、语言生成、多语言能力、编码、数学、推理等的基准测试中总体上超越了大多数开源模型,并表现出与专有模型的竞争力。Qwen2 增⼤了上下⽂⻓度⽀持,最⾼达到 128K tokens(Qwen2-72B-Instruct),能够处理大量输入

千问 2 性能
文生文本地部署 ollama
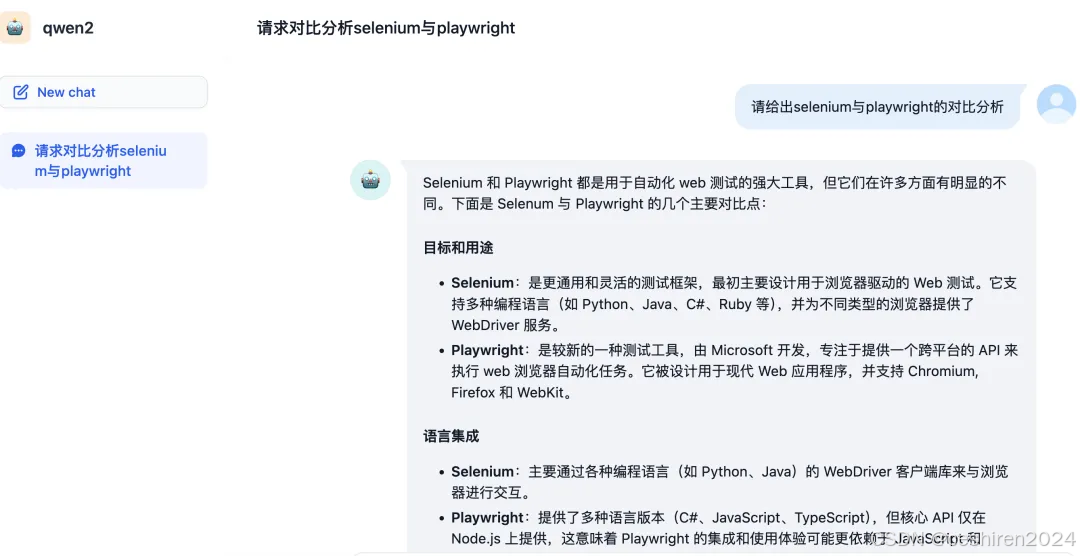
Qwen2-72B-Instruct-demo 在线体验
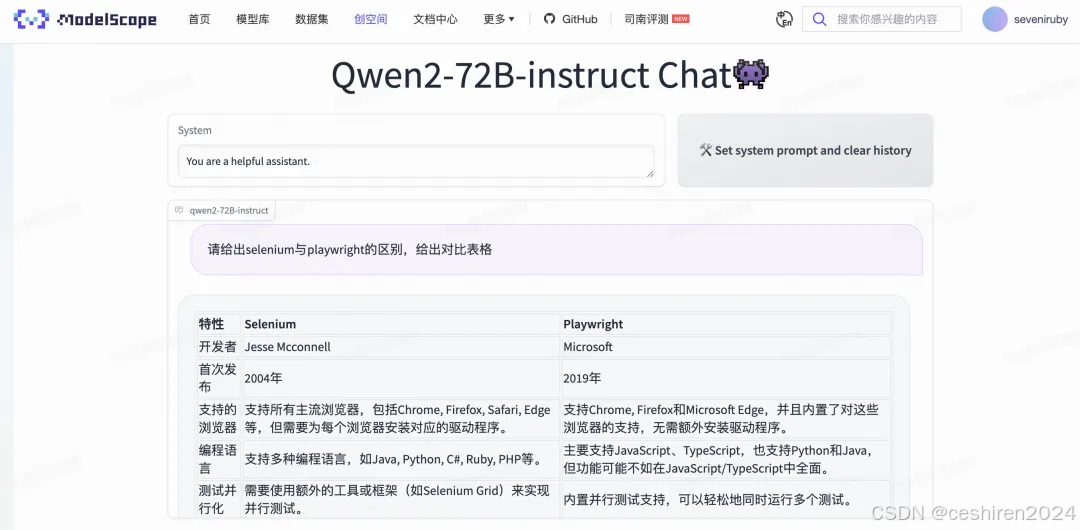
Qwen2-VL ModelScope
Qwen2-VL 可以处理任意图像分辨率,将它们映射到动态数量的视觉标记中,提供更接近人类的视觉处理体验
Qwen2-VL 模型特点
-
读懂不同分辨率和不同长宽比的图片:Qwen2-VL 在 MathVista、DocVQA、RealWorldQA、MTVQA 等视觉理解基准测试中取得了全球领先的表现。
-
理解 20 分钟以上的长视频:Qwen2-VL 可理解长视频,并将其用于基于视频的问答、对话和内容创作等应用中。
-
能够操作手机和机器人的视觉智能体:借助复杂推理和决策的能力,Qwen2-VL 可集成到手机、机器人等设备,根据视觉环境和文字指令进行自动操作。
-
多语言支持:为了服务全球用户,除英语和中文外,Qwen2-VL 现在还支持理解图像中的多语言文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
本地部署示例
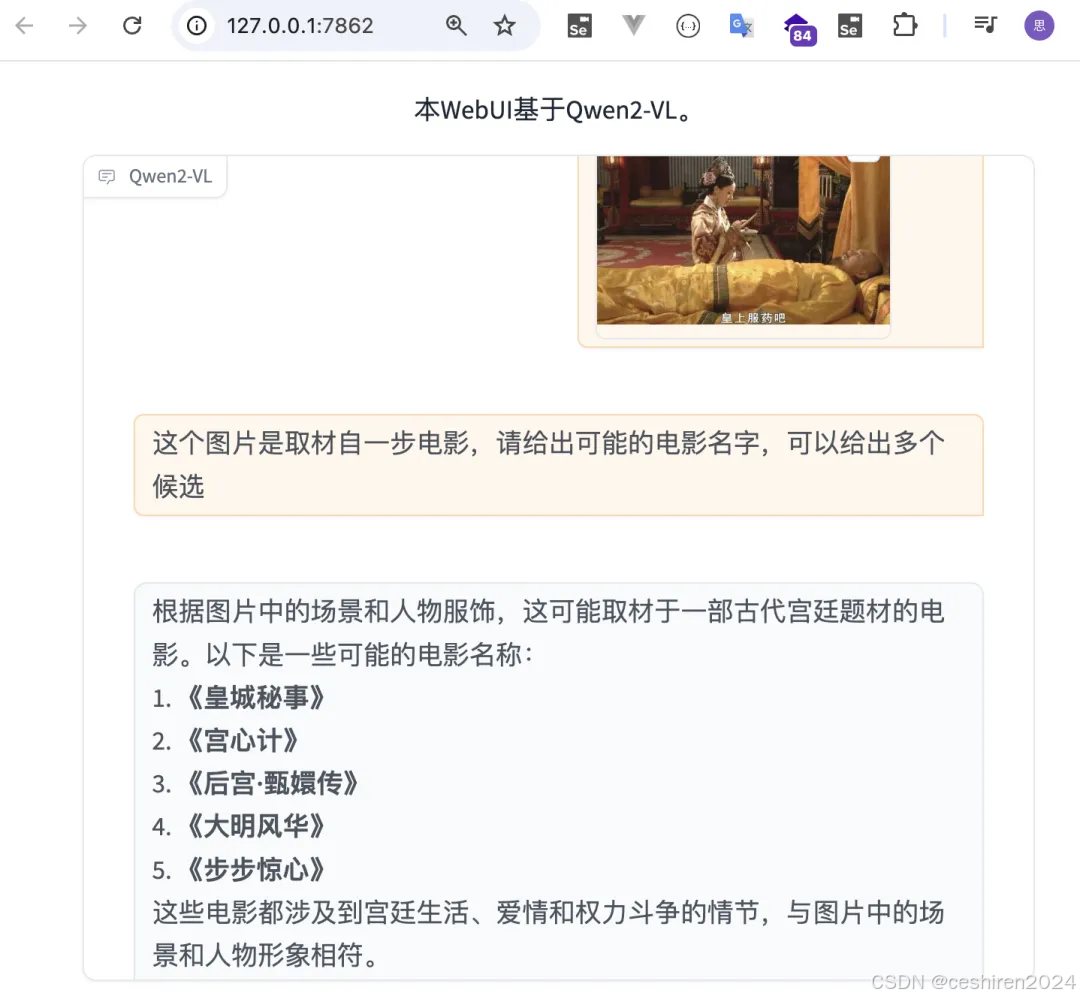
本地处理视频分析
Qwen2-VL ModelScope 在线体验


















 6911
6911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









