






1 NVIDIA NIM是什么
NVIDIA NIM 是 NVIDIA AI Enterprise 的一部分,是一套易于使用的预构建容器工具,目的是帮助企业客户在云、数据中心和工作站上安全、可靠地部署高性能的 AI 模型推理。这些预构建的容器支持从开源社区模型到 NVIDIA AI 基础模型,以及定制的 AI 模型的广泛范围。
NIM 可通过单个命令部署,使用标准 API 和几行代码轻松集成到 企业级 AI 应用程序中。基于 Triton 推理服务器、TensorRT、TensorRT-LLM 和 PyTorch 等强大的推理引擎构建,NIM 旨在促进大规模的无缝 AI 推理,确保你可以在任何地方自信地部署 AI 应用。无论是在本地还是在云端,NIM 都是实现大规模加速生成式 AI 推理的更快方式。优势:
性能与规模:
- 通过低延迟、高吞吐量且可随云扩展的 AI 推理来提高总体拥有成本。
- 通过开箱即用的对微调模型的支持实现更佳的准确性。
易用性:
- 借助预先构建且云原生的微服务加快产品上市时间,这些微服务持续维护,以便在 NVIDIA 加速基础设施上提供优化的推理。
- 为企业开发者提供专为企业环境定制的行业标准 API 和工具安全和可管理性。
- 通过在您选择的基础设施(本地或云中)上自托管部署最新的 AI 模型,维护生成 式 AI 应用程序和数据的安全性与控制。
- 具有专用功能分支、严格验证流程和支持 (包括直接联系 NVIDIA AI 专家和定义的 服务水平协议) 的企业级软件。
2 为什么要使用NIM
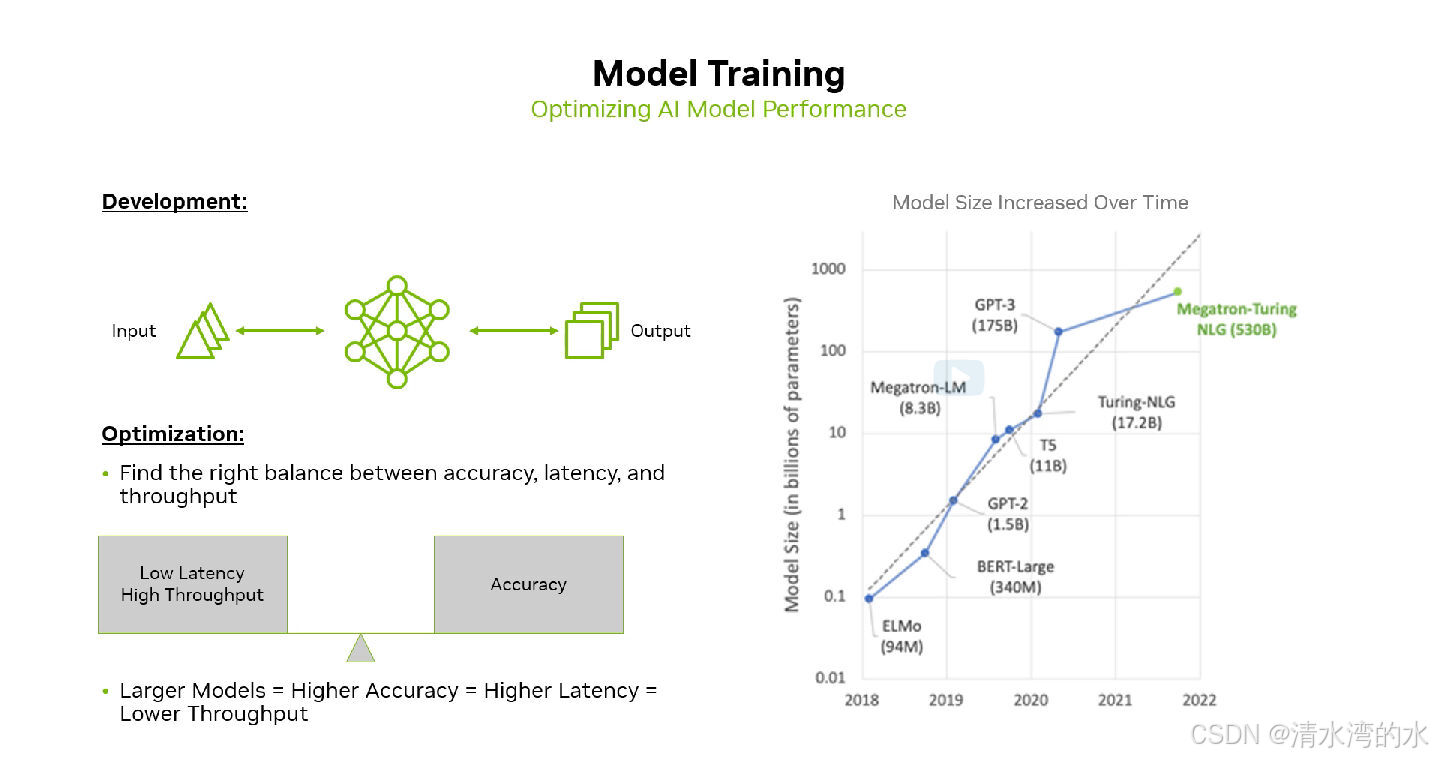
2.1 模型尺寸暴增带来的问题与挑战
模型尺寸越来越大,从2018年0.1B到现在的Llama3.1 405B。 例如,对于一个有 700 亿参数的大语言模型假设使用半精度或 float16,模型的大小可能达到 130GB。模型规模的增大带来了性能上的不可能三角:准确性高,高吞吐量和低延迟。
而NIM 可以更好的平衡这三者之间的关系。例如:使用Llama 3.1 8B模型, NIM 与直接在 GPU 上部署相比,可实现高达 2.8 倍的更高吞吐量。
2.2 使用API接入业务层,更便捷的使用方式
通过使用标准化的 API,开发者可以更改少量的代码来尝试不同的 NIM,模型通过API接入业务层来完成的指定任务。让开发者专注于更有意义的工作。
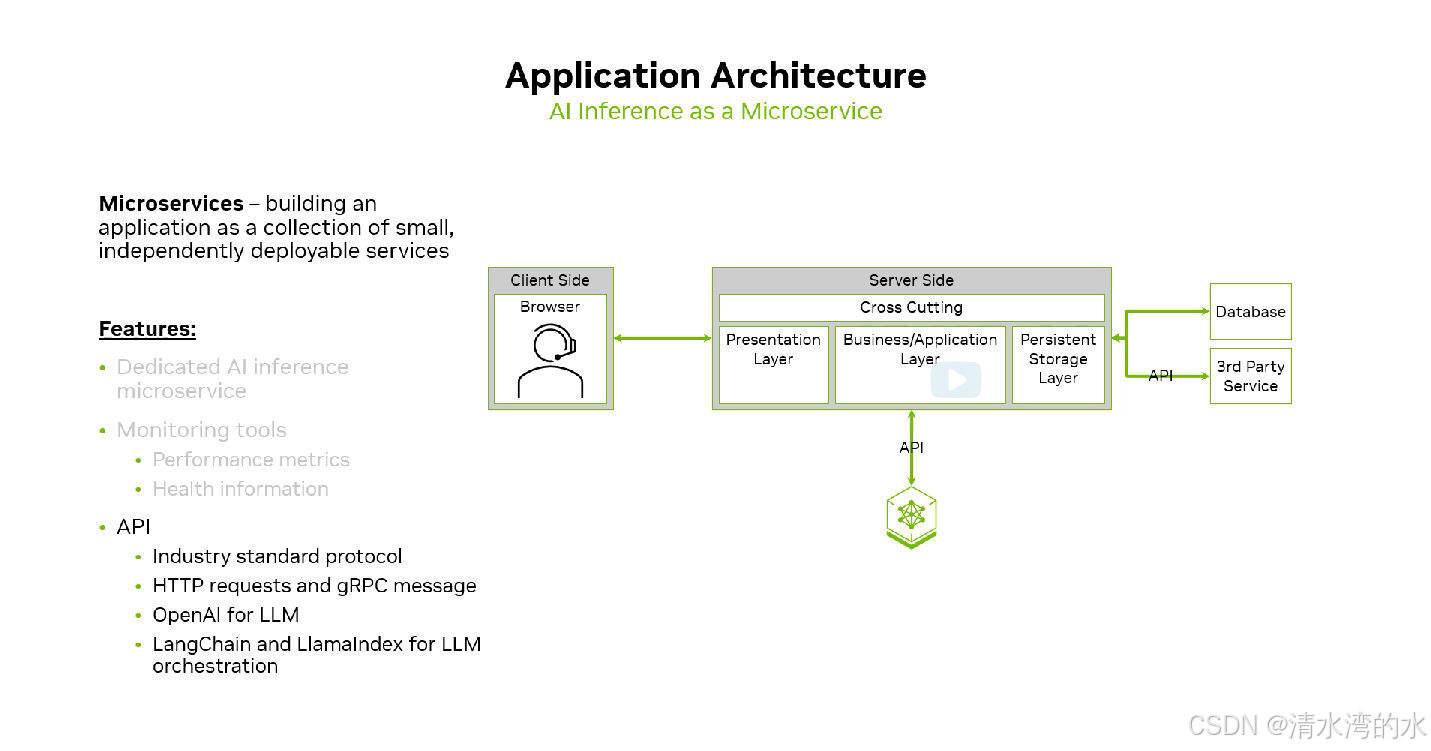
3 NIM基础
3.1 容器化部署是NIM的基础
使用不同的模型镜像,可以快速的启动容器。

4 部署流程与实践
4.1 准备:获取API KEY
在本次体验中,我们使用Lama3 NIM。需要提前获取API KEY。
-
打开
build.nvidia.com登录,获取NVIDIA_API_KEY。 -
注意帐号这里要有credits,不然实验notebook运行会报错。
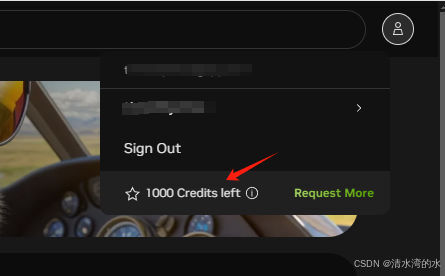
如果没有credits,实验运行代码时会提示帐号没有credits。解决办法:换个帐号。

-
搜索并找到模型,点击进入。
-
获取并保存KEY,实验notebook中需要使用。
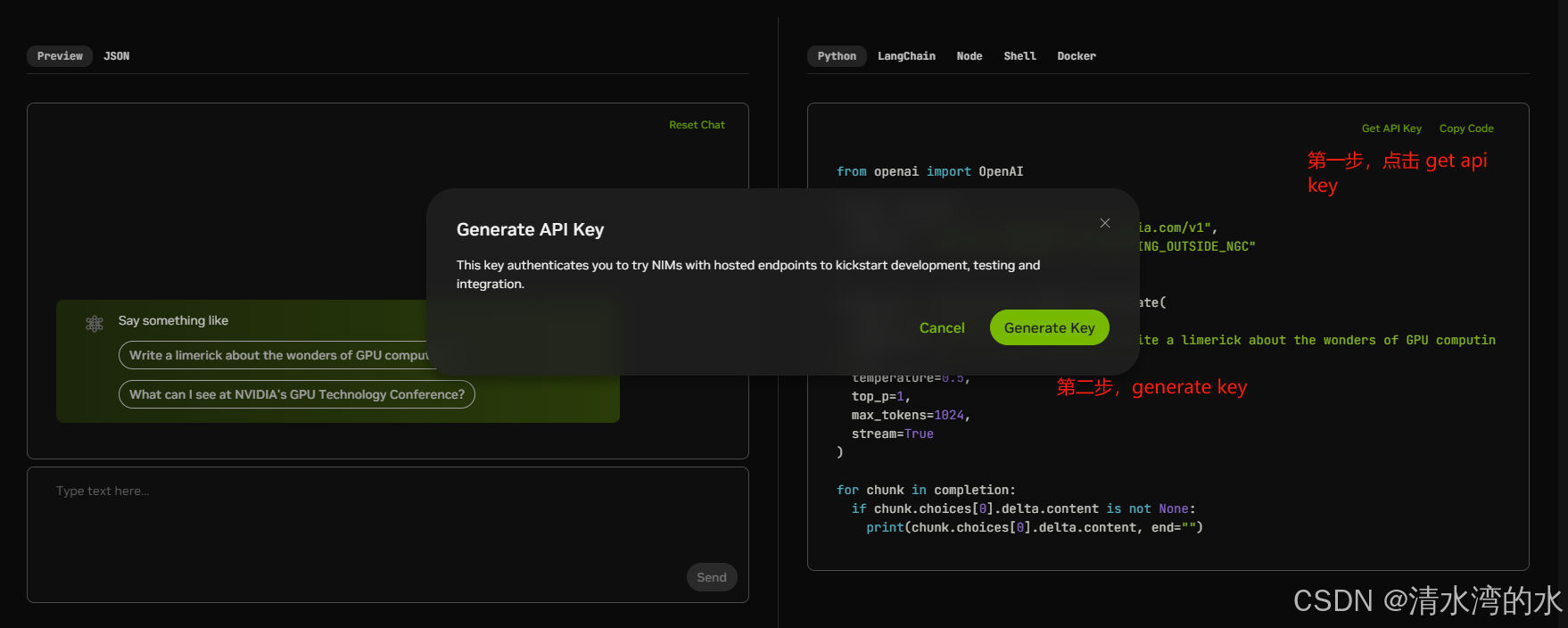
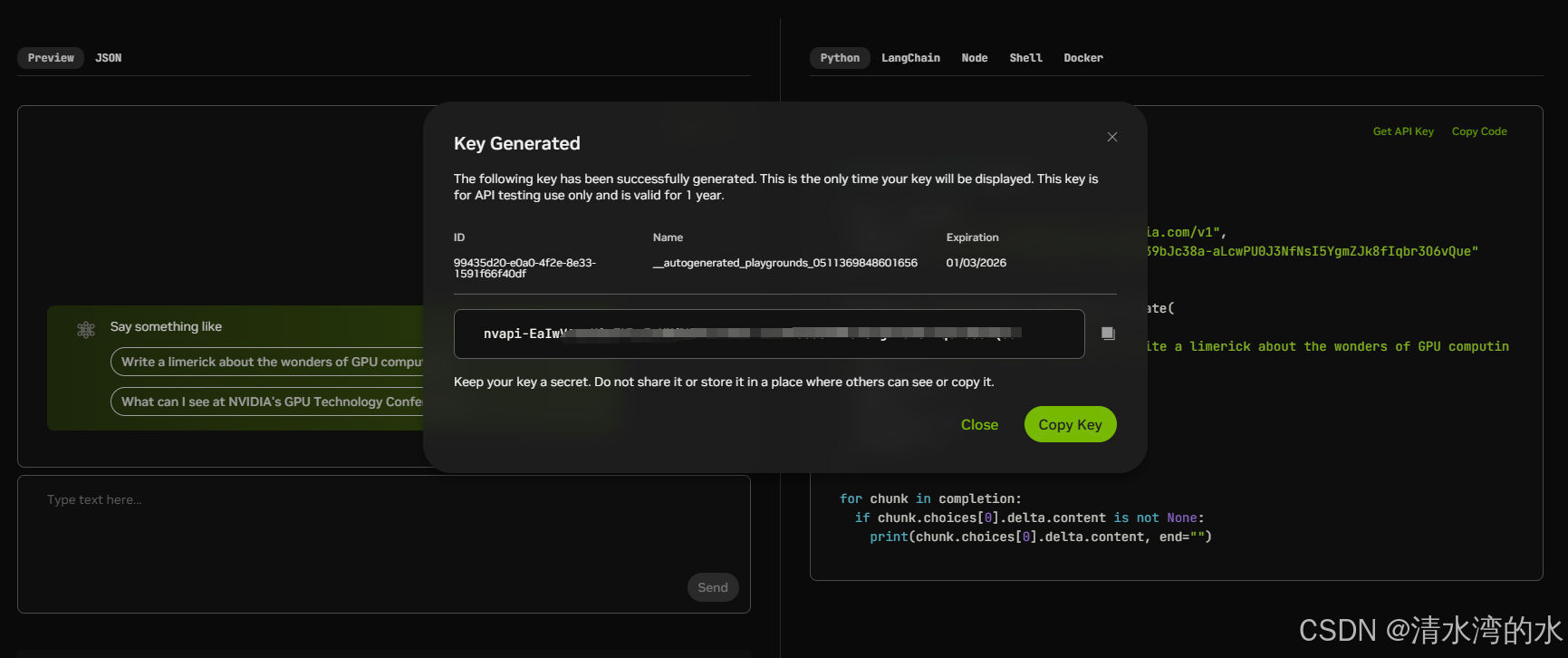
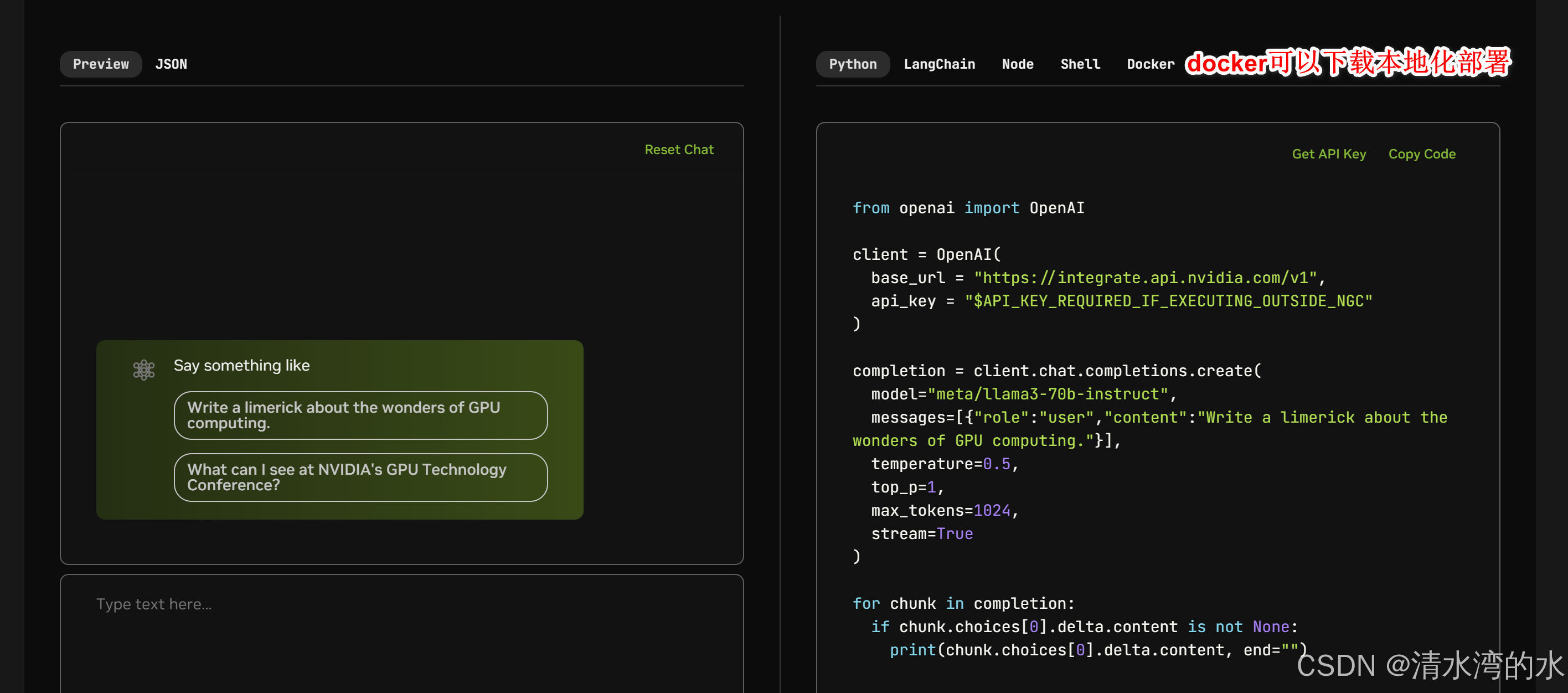
4.2 模型调用方式
可以通过Python、LangChain、Node、Shell 和Docker进行调用。
其中Docker可以下载镜像到本地进行部署。
4.3 课程环境准备
-
点击视频下面的start开始
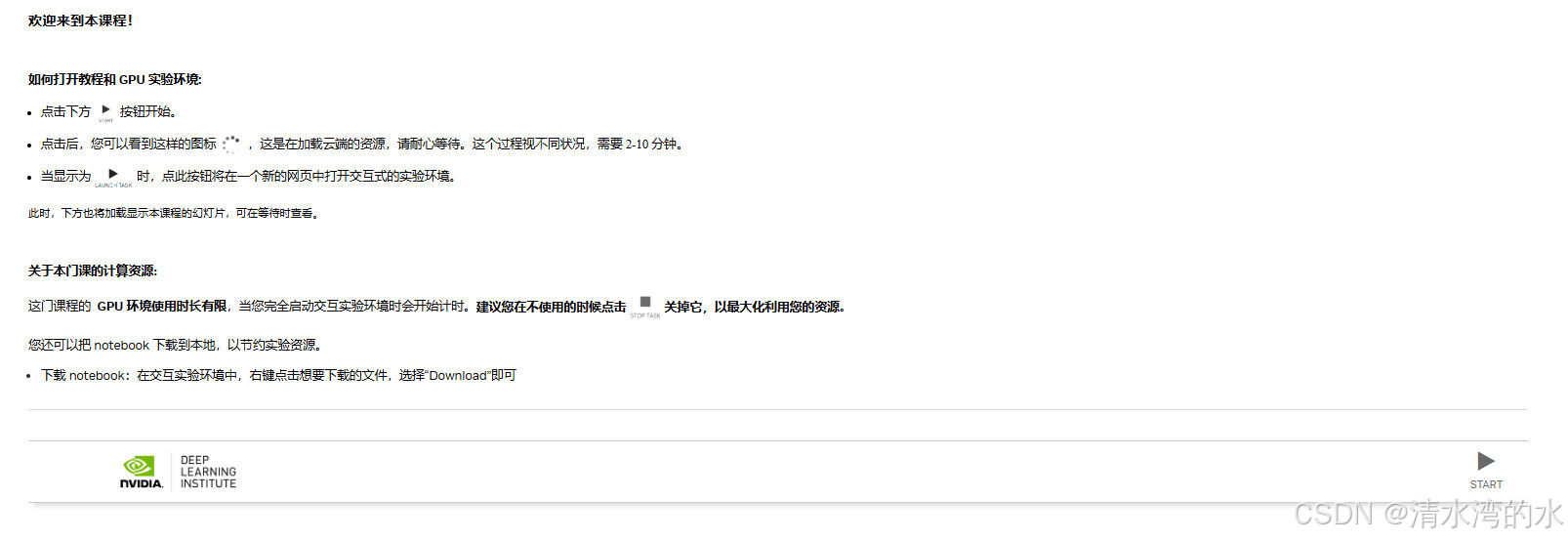
-
等待10分钟左右,点击LAUNCH

-
实验完成后记得点击STOP TASK
4.4 AI聊天机器人构建的体验
本次体验使用LangChain,内容为 NVIDIA Triton 文档网站,构建 RAG 链。
主要步骤如下:
- 从网络爬取NVIDIA Triton 文档,分块数据,并使用 FAISS 生成嵌入,并将嵌入保存到 ./data/nv_embedding 目录的离线向量存储中。
- 加载向量存储中的嵌入并使用 NVIDIAEmbeddings 构建 RAG
- 构建对话机器人
4.4.1 导入模块
import os
from langchain.chains import ConversationalRetrievalChain, LLMChain
from langchain.chains.conversational_retrieval.prompts import CONDENSE_QUESTION_PROMPT, QA_PROMPT
from langchain.chains.question_answering import load_qa_chain
from langchain.memory import ConversationBufferMemory
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_nvidia_ai_endpoints import ChatNVIDIA
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
4.4.2 输入API KEY
运行代码,会出现一个提示输入key,将刚才得到的key复制进去。
import getpass
if not os.environ.get("NVIDIA_API_KEY", "").startswith("nvapi-"):
nvapi_key = getpass.getpass("Enter your NVIDIA API key: ")
assert nvapi_key.startswith("nvapi-"), f"{nvapi_key[:5]}... is not a valid key"
os.environ["NVIDIA_API_KEY"] = nvapi_key
4.4.3 爬虫模块
将网页url中的内容提取出来
import re
from typing import List, Union
import requests
from bs4 import BeautifulSoup
def html_document_loader(url: Union[str, bytes]) -> str:
"""
Loads the HTML content of a document from a given URL and return it's content.
Args:
url: The URL of the document.
Returns:
The content of the document.
Raises:
Exception: If there is an error while making the HTTP request.
"""
try:
response = requests.get(url)
html_content = response.text
except Exception as e:
print(f"Failed to load {url} due to exception {e}")
return ""
try:
# Create a Beautiful Soup object to parse html
soup = BeautifulSoup(html_content, "html.parser")
# Remove script and style tags
for script in soup(["script", "style"]):
script.extract()
# Get the plain text from the HTML document
text = soup.get_text()
# Remove excess whitespace and newlines
text = re.sub("\s+", " ", text).strip()
return text
except Exception as e:
print(f"Exception {e} while loading document")
return ""
4.4.4 索引文档
def index_docs(url: Union[str, bytes], splitter, documents: List[str], dest_embed_dir) -> None:
"""
Split the document into chunks and create embeddings for the document
Args:
url: Source url for the document.
splitter: Splitter used to split the document
documents: list of documents whose embeddings needs to be created
dest_embed_dir: destination directory for embeddings
Returns:
None
"""
embeddings = NVIDIAEmbeddings(model="NV-Embed-QA", truncate="END")
for document in documents:
texts = splitter.split_text(document.page_content)
# metadata to attach to document
metadatas = [document.metadata]
# create embeddings and add to vector store
if os.path.exists(dest_embed_dir):
update = FAISS.load_local(folder_path=dest_embed_dir, embeddings=embeddings, allow_dangerous_deserialization=True)
update.add_texts(texts, metadatas=metadatas)
update.save_local(folder_path=dest_embed_dir)
else:
docsearch = FAISS.from_texts(texts, embedding=embeddings, metadatas=metadatas)
docsearch.save_local(folder_path=dest_embed_dir)
4.4.5 爬取关于triton的网页,生成嵌入并保存
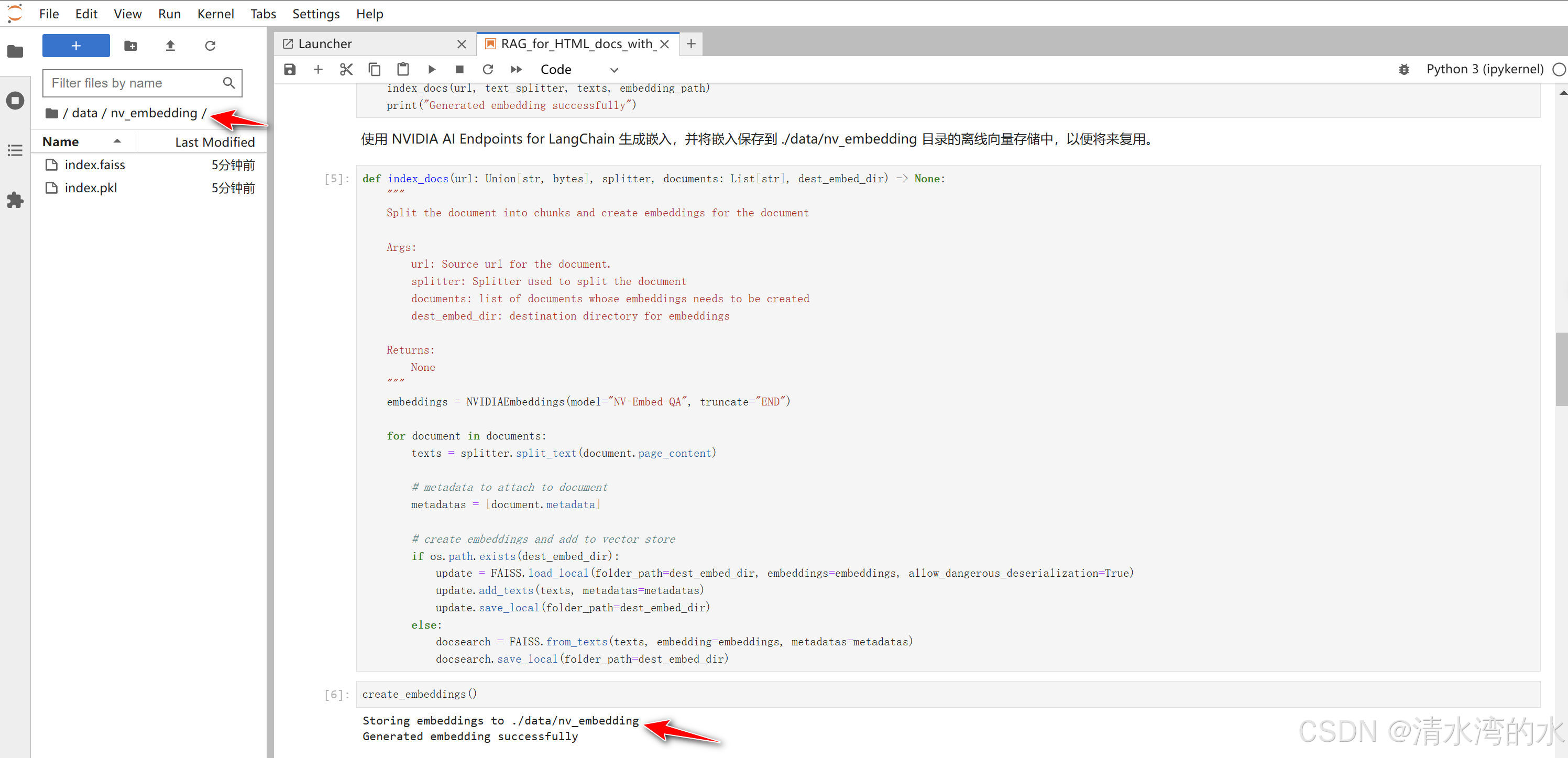
def create_embeddings(embedding_path: str = "./data/nv_embedding"):
embedding_path = "./data/nv_embedding"
print(f"Storing embeddings to {embedding_path}")
# List of web pages containing NVIDIA Triton technical documentation
urls = [
"https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/index.html",
"https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/getting_started/quickstart.html",
"https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/user_guide/model_repository.html",
"https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/user_guide/model_analyzer.html",
"https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/user_guide/architecture.html",
]
documents = []
for url in urls:
document = html_document_loader(url)
documents.append(document)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0,
length_function=len,
)
texts = text_splitter.create_documents(documents)
index_docs(url, text_splitter, texts, embedding_path)
print("Generated embedding successfully")
可以看到生成的嵌入已经保存到了目录下面。
4.4.6 测试向量搜索
embedding_model = NVIDIAEmbeddings(model="NV-Embed-QA", truncate="END", allow_dangerous_deserialization=True)
embedding_path = "./data/nv_embedding"
docsearch = FAISS.load_local(folder_path=embedding_path, embeddings=embedding_model, allow_dangerous_deserialization=True)
retriever = docsearch.as_retriever()
retriever.invoke("Deploy TensorRT-LLM Engine on Triton Inference Server")
4.4.7 定义模型和对话链
llm = ChatNVIDIA(model='mistralai/mixtral-8x7b-instruct-v0.1')
chat = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1", temperature=0.1, max_tokens=1000, top_p=1.0)
retriever = docsearch.as_retriever()
##Requires question and chat_history
qa_chain = (RunnablePassthrough()
## {question, chat_history} -> str
| CONDENSE_QUESTION_PROMPT | llm | StrOutputParser()
# | RunnablePassthrough(print)
## str -> {question, context}
| {"question": lambda x: x, "context": retriever}
# | RunnablePassthrough(print)
## {question, context} -> str
| QA_PROMPT | chat | StrOutputParser()
)
4.4.8 开始对话提问
chat_history = []
query = "What is Triton?"
chat_history += [qa_chain.invoke({"question": query, "chat_history": chat_history})]
chat_history
得到回答

4.4.9 更多的对话演示请参考课程提供的notebook
5 使用Docker进行本地部署
5.1 拉取运行容器
!export NGC_API_KEY="YOUR API KEY"
!docker login nvcr.io --username $oauthtoken --password "${NGC_API_KEY}"
!export LOCAL_NIM_CACHE=~/.cache/nim
!mkdir -p "$LOCAL_NIM_CACHE"
#拉取运行容器
!docker run -it --rm --gpus all shm-size=16GB -e NGC_API_KEY -v "$LOCAL_NIM_CACHE:/opt/nim/.cache" -u $(id -u) -p 8000:8000 nvcr.io/nim/meta/llama3-70b-instruct:latest
#测试接口
curl -X 'POST' \
'http://0.0.0.0:8000/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama3-70b-instruct",
"messages": [{"role":"user", "content":"Write a limerick about the wonders of GPU computing."}],
"max_tokens": 64
}'
5.2 使用python进行调用
from langchain_nvidia_ai_endpoints import ChatNVIDIA
chat = ChatNVIDIA(base_url="http://0.0.0.0:8000/v1/", model="meta/llama3-70b-instruct", temperature=0.1, max_tokens=1000, top_p=1.0)
其余代码和上一个实验相同。
6 NVIDIA DLI课程的官方链接
快来体验吧
https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-FX-23+V1-ZH

















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









