







来源:将门创投
作者:张文祺
来源:公众号【量子位】
目前,LLM Agent大多专注于特定任务。研究者在了解该任务的领域知识后,手工编写大量复杂的Prompt,告知任务的规则并规范LLM 的输入输出的形式等。此外,大部分LLM Agent缺乏从任务环境中学习的能力, 他们无法通过与环境互动来提升自己的行为,从而更好地达成人类设定的目标。
因此当面对复杂的动态的环境时,例如多人德州扑克、21点等大型非完美信息博弈游戏,LLM Agent给出的决策往往不够合理,不懂变通。那么, 在不调整模型参数的前提下,LLM Agent能否像人类一样,在复杂动态环境中学习并持续提升,从一个新手小白进化为一个熟练的专家呢?
针对这一问题,来自浙江大学, 中科院软件所等机构的研究者提出了Agent-Pro: an LLM-based Agent with Policy-level Reflection and Optimization,具备策略级自我反思和行为优化的LLM Agent。Agent-Pro 能够与游戏环境交互,学习游戏环境的世界模型,优化自己的行为策略,提升游戏技巧。
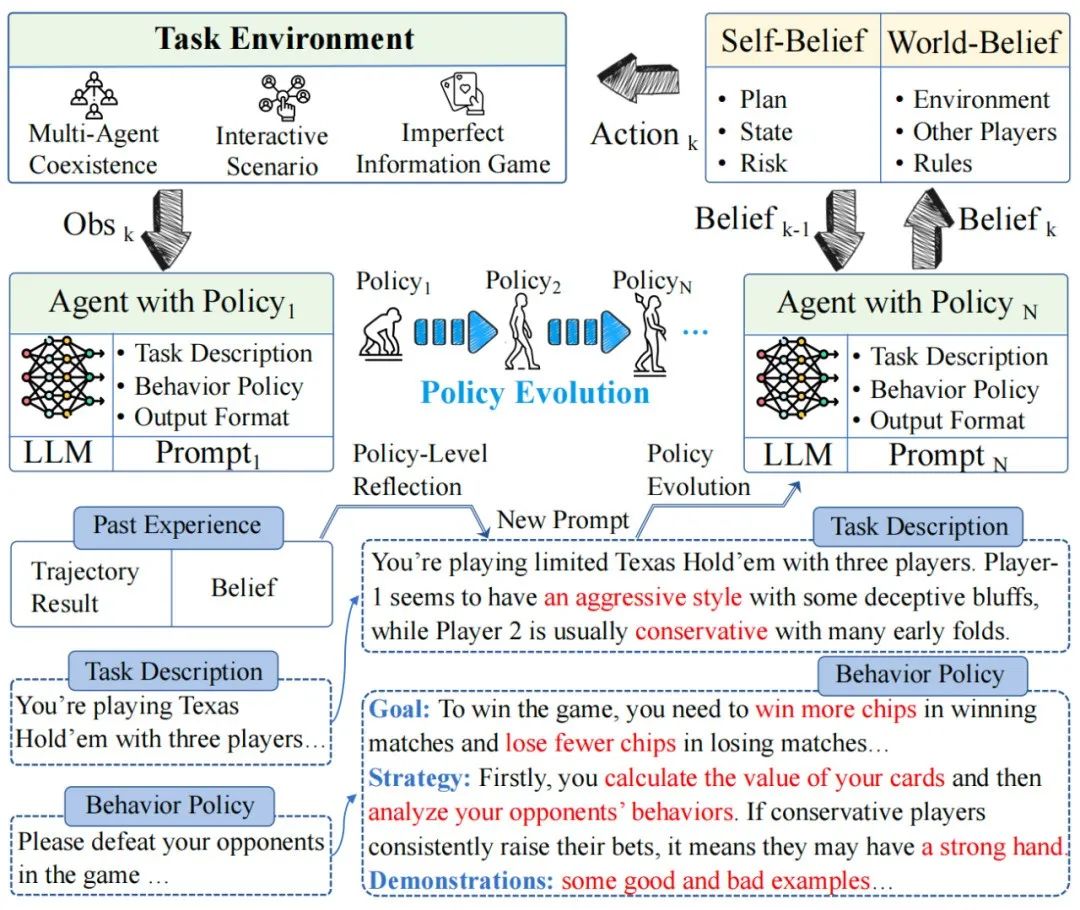
图1 Agent-Pro示意图
如上图1所示,Agent-Pro以LLM作为基座模型,通过自我优化的Prompt来建模游戏世界模型和行为策略。
Dynamic belief:Agent-Pro 动态地生成自我信念(Self-Belief)和对外部世界的信念(World-Belief)。每次决策都基于这些信念,并动态地更新这些信念。
World Modeling & Behavior Policy: Agent-Pro内部包括一个对任务世界的建模以及对自己行为策略的描述。在持续环境交互和探索中,Agent-Pro不断优化这个游戏世界模型和行为策略。
Policy-level Reflection and Optimization: 通过对历史行动轨迹、信念和每局游戏结果进行策略级的反思,Agent-Pro “微调” 其不正确的信念,优化一个更好的 prompt实现来对游戏世界和行为策略进行建模。
研究者在多人德州扑克和21 点这两个广为流行的博弈游戏中进行了实验。结果表明,受益于持续优化的世界模型和行为策略,Agent-Pro的游戏水平不断提升,涌现出很多类似人类的高阶技巧: 虚张声势,欺诈,主动放弃等。这为多种现实世界的很多场景提供了可行解决路径。

论文题目:
Agent-Pro: an LLM-based Agent with Policy-level Reflection and Optimization
论文链接:
https://arxiv.org/abs/2402.17574
代码链接:
https://github.com/zwq2018/Agent-Pro
一、Agent-Pro是如何学习和进化
1.1 🃏游戏规则
首先简要介绍下两个博弈游戏的基本规则。
🔔21点
游戏中包含一个庄家和至少一名玩家。
玩家可以看到自己的两张手牌, 以及庄家的一张明牌。庄家还隐藏了一张暗牌。玩家需要决定是继续要牌(Hit)还是停牌(Stand)。
目标是在总点数不超过21点的前提下,尽量使总点数超过庄家。
🔔有限注德州扑克
游戏开始阶段为Preflop阶段,每位玩家将获得两张只属于自己且对其他玩家保密的私牌(Hand)。
随后,会有五张公共牌面(Public Cards)依次发出:首先翻牌(Flop):3 张,其次转牌(Turn):1张,最后是河牌(River):1张。
玩家有四种选择:弃牌(fold)、过牌(check)、跟注(call)或加注(raise)。
目标是利用自己的两张Hand和五张Public Cards任意组合,尽可能构造出最佳的五张扑克牌组合。
1.2 🤖学习和进化
Agent-Pro包括 “动态的信念--策略层面的反思--世界模型和行为策略优化” 这三个组件。
1.2.1 基于信念的决策(Belief-aware Decision-Making)
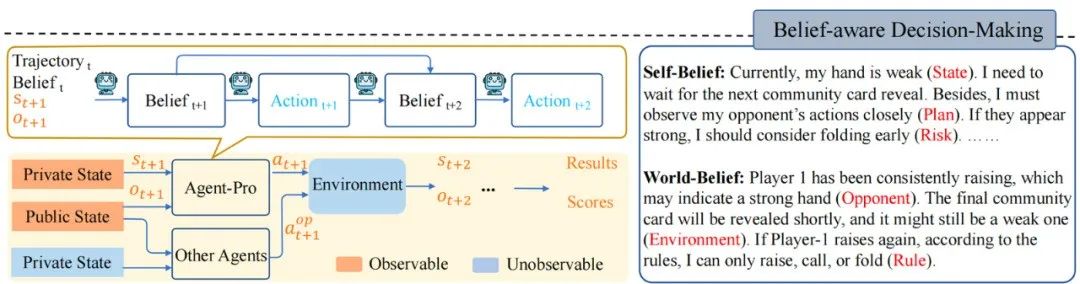
图2 基于信念的决策示意图
如上图,Agent-Pro根据环境信息,首先形成自我信念Self-Belief和对外部世界的信念World-Belief,然后基于这些信念Belief做出决策Action。在后续环境交互中,Agent-Pro动态更新Belief,进而使做出的Action适应环境的变化。
例如,🃏德州扑克游戏中:
环境信息可包括手牌Private State、公共牌Public State、行动轨迹Trajectory等;
Agent-Pro对手牌State、出牌计划Plan及潜在风险Risk的预估等构成了它的Self-Belief;
而Agent-Pro对对手Opponent、环境Environment和规则Rule的理解则构成了它的World-Belief;
这些Belief在每一个决策周期中都会被更新,从而影响下个周期中Action的产生
1.2.2 策略层面的反思(Policy-Level Reflection)
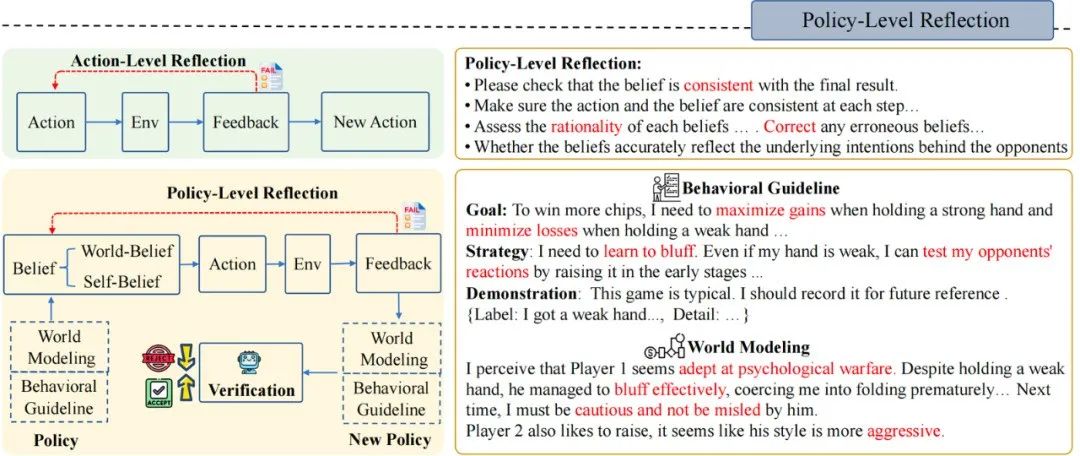
图3 策略层面的反思示意图
与人类一样,Agent-Pro 会从历史经验、历史认知和历史结果中进行反思和优化。它自主调整自己的Belief,寻找有用的提示指令,并将其整合到新的策略Policy中。
首先Agent-Pro以文字的形式设计了一个对任务世界的建模以及对行为准则的描述, 他们一起被当做 Policy:
World Modeling:任务世界的建模,例如对游戏环境的理解、对手们的风格分析、环境中其他 Agent的策略估计等
Behavioral Guideline:行为准则的描述,例如对游戏目标的认识、自己策略规划、未来可能面临的风险等
其次,为了更新World Modeling和Behavioral Guideline,Agent-Pro 设计了一个 Policy-level Reflection 过程。与Action-level Reflection不同,在Policy-level的反思中,Agent-Pro被引导去关注内在和外在信念是否对齐最终结果,更重要的是,反思背后的世界模型是否准确,行为准则是否合理,而非单个Action。
例如,🃏德州扑克游戏中Policy-level的反思:
在当前世界模型和行为准则(World Modeling & Behavioral Guideline)的指导下,Agent-Pro观察到外部状态,然后生成Self-Belief和World-Belief,最后做出Action。但如果Belief不准确,则可能导致不合逻辑的行动和最终结果的失败;
Agent-Pro根据每一次的游戏来审视Belief的合理性,并反思导致最终失败的原因(Correct,Consistent,Rationality...);
然后,Agent-Pro将反思和对自身及外部世界的分析整理,生成新的行为准则Behavioral Guideline和世界建模World Modeling;
基于新生成的Policy(World Modeling & Behavioral Guideline),Agent-Pro重复进行相同游戏,来进行策略验证。如果最终分数有所提高,则将更新后的World Modeling & Behavioral Guideline和保留在提示中。
1.2.3 世界模型和行为准则的优化(DFS-based Policy Evolution)
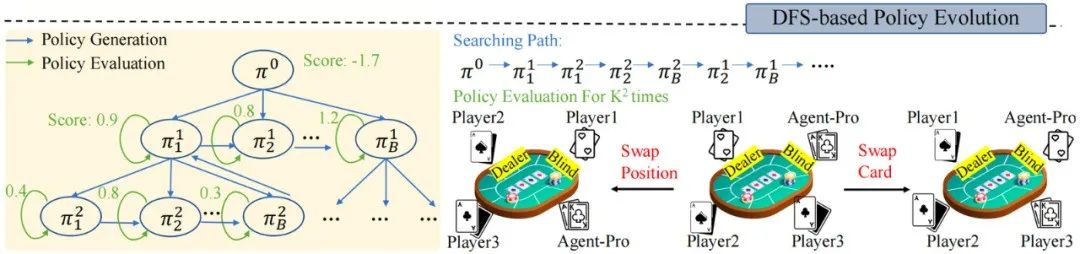
图4 世界模型和行为准则的优化示意图
在Policy-level Reflection之上,面对动态的环境,Agent-Pro还采用了深度优先搜索(DFS)和策略评估,来持续优化世界模型和行为准则,从而找到更优的策略。
策略评估:Agent-Pro 在新的采样的轨迹中对新Policy进行更全面的评估,从而考察新策略的泛化能力。例如,🃏德州扑克游戏中,新采样多条游戏轨迹。通过交换玩家位置或手牌,来消除由于运气带来的随机因素,从而更全面评估新策略的能力。
DFS搜索: 若新策略不能在新的场景中带来预期的改进(策略评估),则按照 DFS搜索策略,从其他候选策略中寻找更优的策略。
二、Qualitative Evaluation
以🃏德州扑克为例:
一次牌局中3个对手(DQN、DMC、GPT3.5)和Agent-Pro的手牌和公共牌如下图:

图5 牌型,两个字符组成,前方为4种花色:S,H,C,D,后方为大小
在当前游戏状态Current game state下,Agent-Pro分析得出Self-Belief、World-Belief和最终的Action。并随着游戏状态的变化,不断更新Belief,根据自身和对手的情况,做出灵活合理的选择。
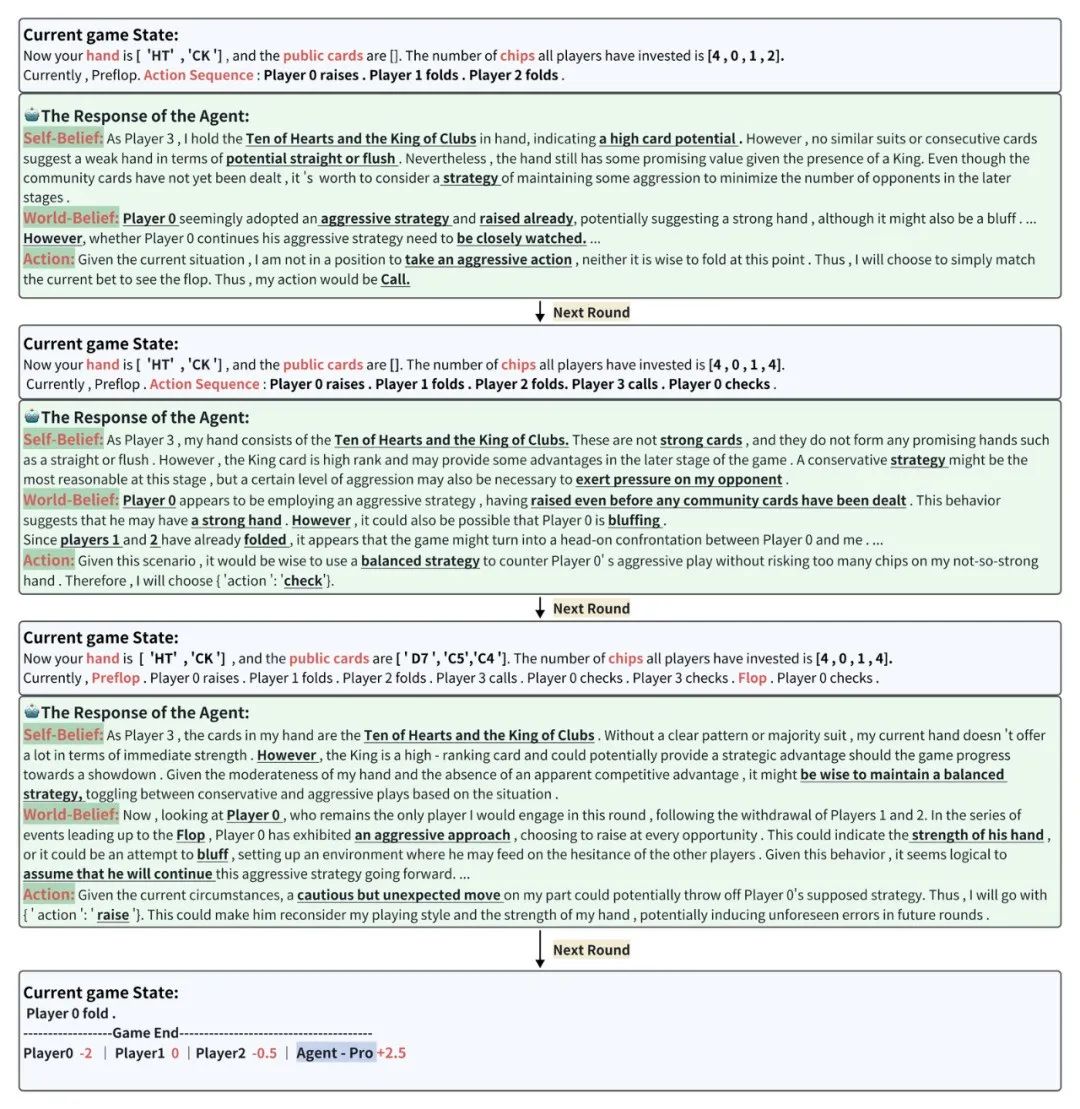
图6 基于GPT4的Agent-Pro游戏过程(相同牌局同一位置的Baseline结果为-13)
以🃏21点为例,在同一手牌的情况下,对比实验中ReAct和Agent-Pro的差异。
如下图7所示,Agent-Pro通过分析得出Self-Belief和World-Belief,正确认识到自己的手牌已接近21点,合理的选择了停牌。而ReAct则未能及时停牌,导致最终爆牌,输掉了游戏。从游戏中能够看出Agent-Pro更好的理解了游戏的规则,并给出了合理的选择。
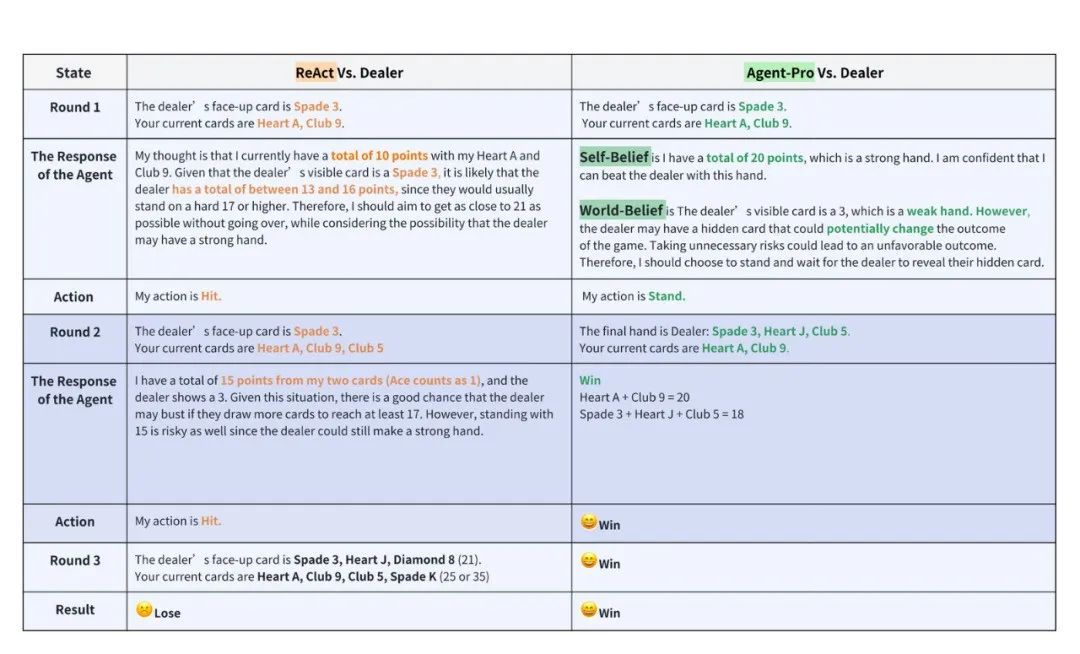
图7 基于GPT4的ReAct和Agent-Pro游戏过程
三、Quantitative Evaluation
如下图8所示,在21点游戏上,Agent-Pro在大多数LLMs中显著超过了Vanilla LLM和其他的 Agents。
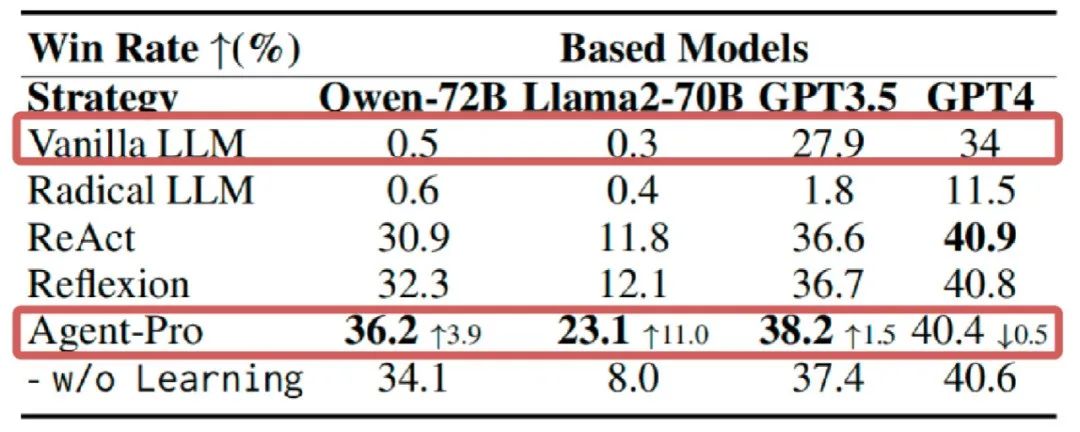 图8 21点实验结果
图8 21点实验结果
在更为复杂的德州扑克游戏中,Agent-Pro不仅超过了基于LLM的基线代理,还击败了训练后的强化学习Agent,例如DMC。
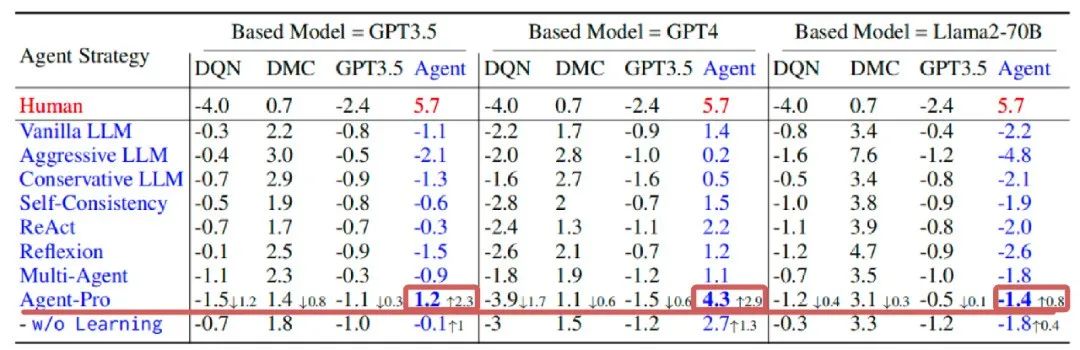 图9 德州扑克实验结果,分别以4个玩家为一组进行对弈,第4位置为测试Agent
图9 德州扑克实验结果,分别以4个玩家为一组进行对弈,第4位置为测试Agent
四、总结
在本文中,研究者开发了一种能够在交互环境中学习任务世界模型,优化自身行为策略的LLM-based Agent:Agent-Pro, 从而具备在复杂动态的环境中学习与进化的能力。
研究者聚焦于多玩家非完美信息的博弈:21点和德州扑克。受益于不断优化的世界模型和行为准则,我们观察到Agent-Pro的决策能力有了显著提升。
在现实世界的情景中,如竞争、公司谈判和安全等,大多可以抽象为multi-agent博弈任务。Agent-Pro通过对这类情境的研究,为解决众多现实世界的问题提供了有效策略。
Illustration From IconScout By 22
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









