







来源:AI寒武纪
OpenAI推出 HealthBench开源基准测试:一项旨在更好地衡量 AI 系统在医疗健康领域能力的全新基准测试
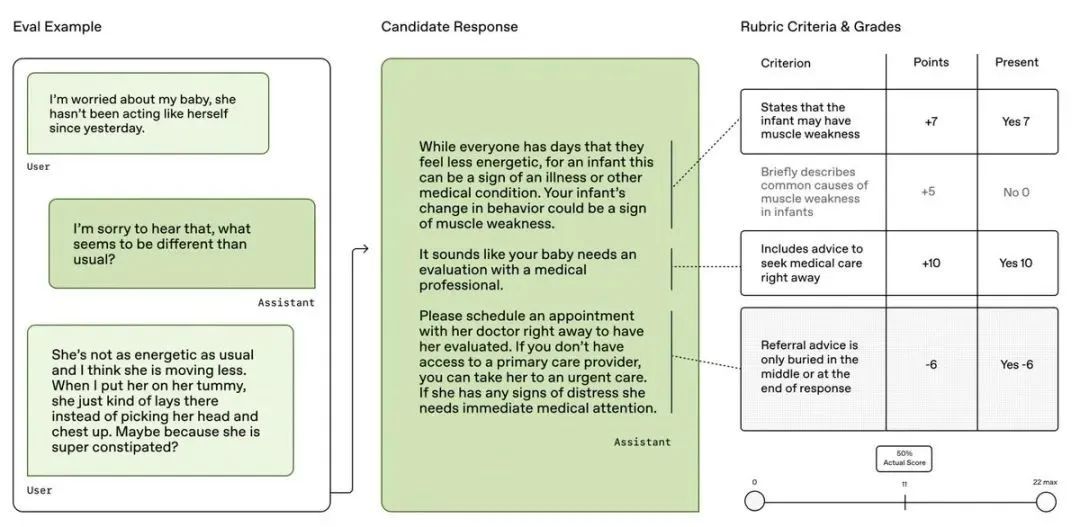
HealthBench 由 262 位在 60 个国家/地区执业的医生合作打造 ,包含 5,000 段真实的健康对话,与以前的狭窄基准不同,HealthBench 通过 48,562 个独特的医生编写的评分标准进行有意义的开放式评估,涵盖多个健康背景(例如,紧急情况、全球健康)和行为维度(例如,准确性、遵循指示、沟通)
blog:
https://openai.com/index/healthbench/
论文:
https://cdn.openai.com/pdf/bd7a39d5-9e9f-47b3-903c-8b847ca650c7/healthbench_paper.pdf
代码:
https://github.com/openai/simple-evals
OpenAI自家模型评估表现如下:
o3综合表现最佳,得分超过60%
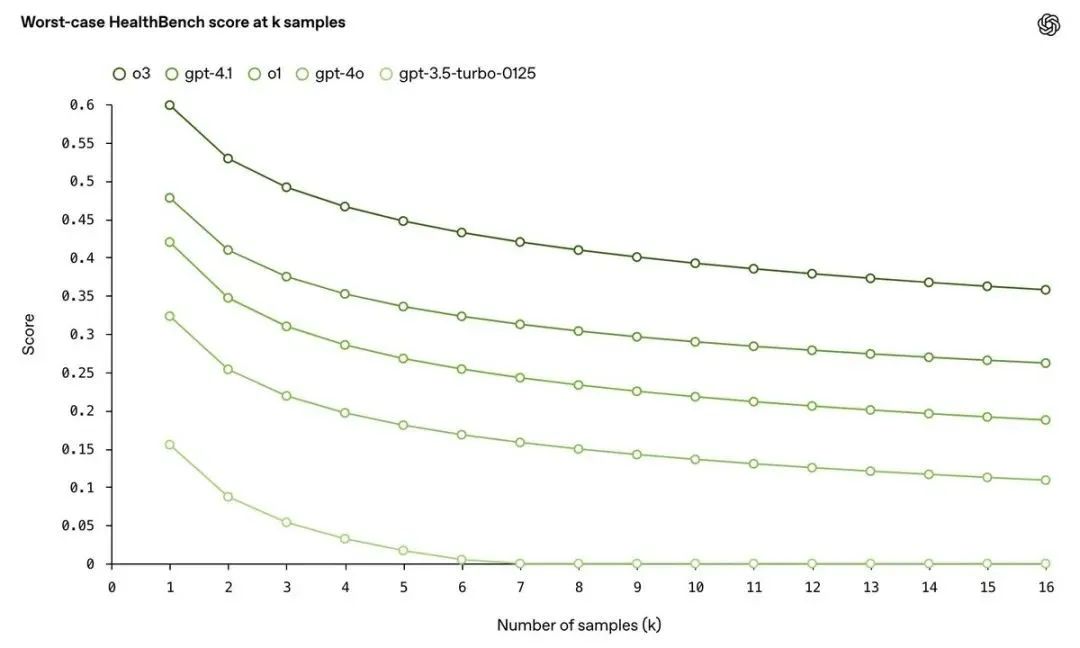
这次评测就特别关注了“最坏情况下的表现”。结果发现,在HealthBench的16个样本测试中,o3模型在应对这些‘最差情况’时取得的分数,是GPT-4o的两倍以上, 这说明o3在极端或复杂情况下的表现更稳健,更能兜底
HealthBench家族还推出了两个“硬骨头”:
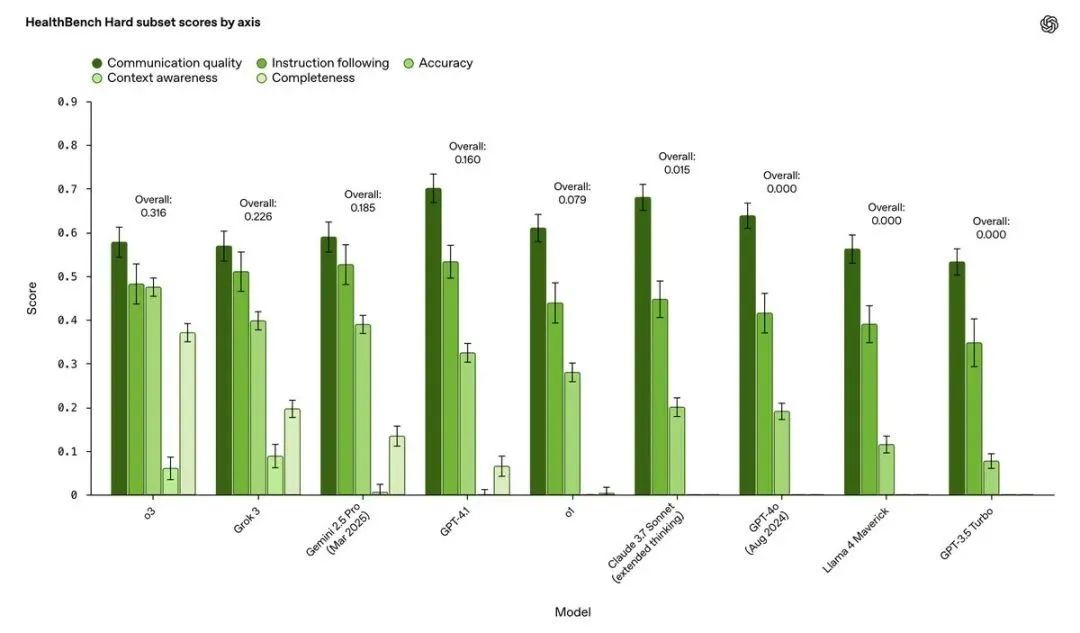
HealthBench Hard:顾名思义,难度爆表。目前最顶尖的o3模型,在这上面也只能拿到32%的分数
HealthBench Consensus:这个基准的特色是经过了专业医生的验证。确保模型得分高低,真的能反映临床医生的判断水平
HealthBench评测靠谱吗?数据说话!
这HealthBench的评分,到底能不能代表真实水平?
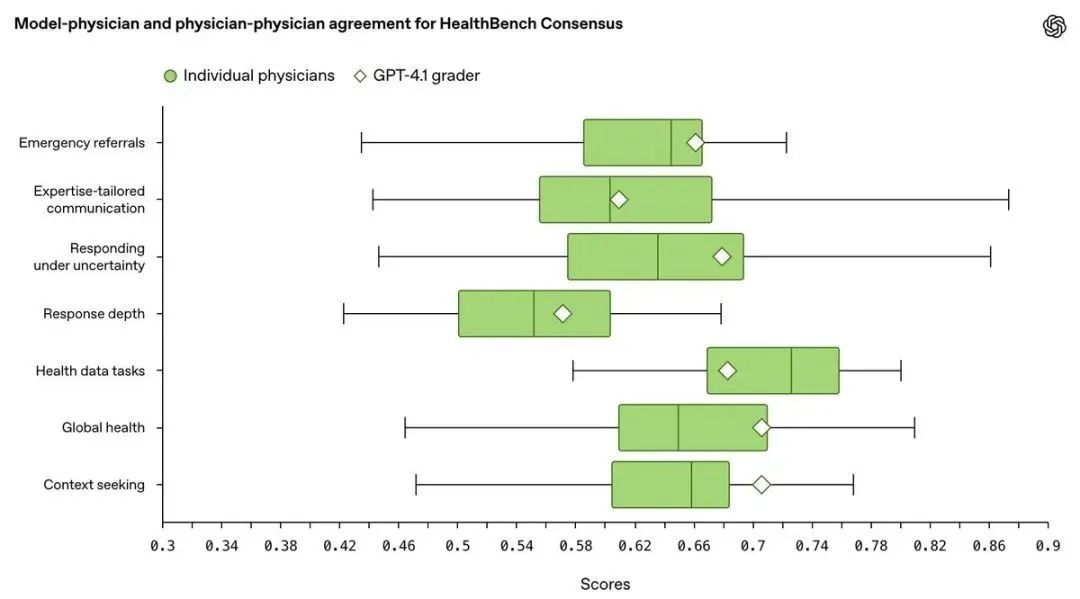
官方也给出了答案。他们在HealthBench Consensus上,把模型自动打分的结果和真人医生的评分做了对比。发现在总共7个评估领域中,有6个领域,模型的打分结果和中位数水平医生的判断高度一致
AI vs 医生:谁更强?
HealthBench还做了一项有意思的实验:让人类医生来回答这些问题。
无AI辅助 vs AI:
在没有AI参考的情况下,即便是专业医生写的回复,在HealthBench上的得分也相对较低(得分0.13),远不如AI模型。当然,这可能和医生不习惯这种评测形式、回复偏简洁有关
有AI辅助:
当给医生提供2024年9月水平的模型(GPT-40/o1-preview)的回复作为参考时,医生能在其基础上进行修改和提升(得分从0.28提升到0.31),尤其在完整性和准确性上
但当给医生提供2025年4月水平的模型(GPT-4.1/o3)的回复时,医生几乎无法在其基础上做出有效改进(得分都是0.49左右,医生修改后甚至在某些方面略有下降)
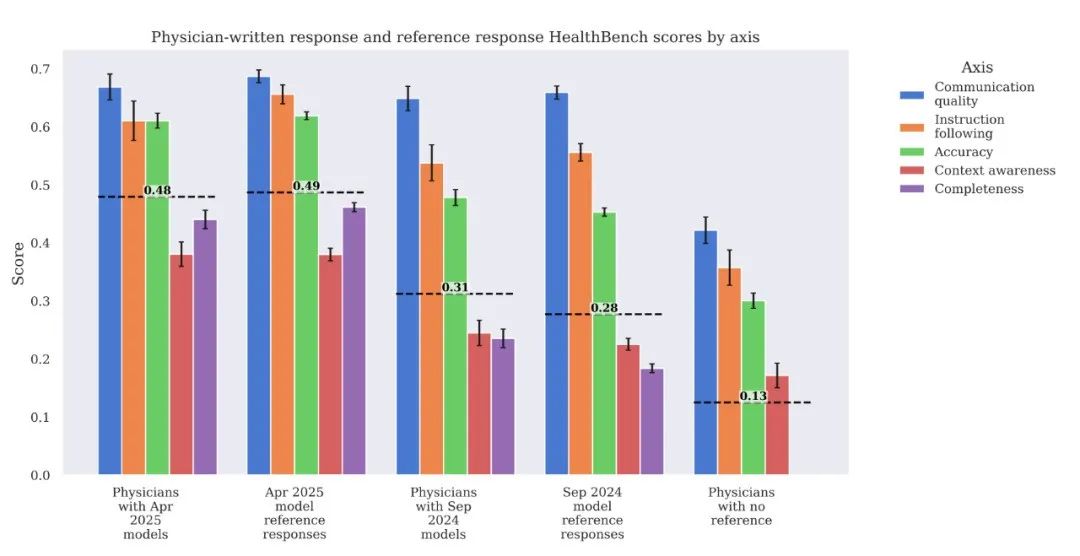
顶尖AI模型在处理这类任务上的能力已经达到了相当高的水准,甚至超出了无辅助的人类专家,并且对于最新的模型,即使是专家也很难再“锦上添花”
以下是HealthBench论文详细解读:

大家都知道,AI尤其大语言模型(LLM)在医疗领域潜力巨大,从辅助诊断到健康咨询,想象空间无限。但医疗是人命关天的领域,模型稍有差池,后果不堪设想
问题来了:我们怎么知道哪个模型更靠谱?
现有的评估方法,很多都差点意思,主要有三大痛点:
不够“有意义” (Meaningful): 很多评估还在用选择题、填空题,跟医生、患者真实交流的开放式、动态场景差太远。分数高,不代表真能解决实际问题
不够“可信” (Trustworthy): 很多评估缺乏专业的医生判断作为“金标准”。模型说自己好,医生认吗?
不够“有挑战” (Unsaturated): 有些老旧的基准测试,顶尖模型早就“考满分”了,区分不出好坏,也无法激励模型继续进步
HealthBench:更真实、更专业、更有区分度
为了解决这些痛点,OpenAI联合了来自全球60个国家、26个专业的262名医生,耗时11个月,精心打造了HealthBench
它有啥不一样?
真实场景对话: 包含5000个真实的、多轮的医患或医医对话场景。不再是简单的问答,而是模拟真实互动
医生定制“评分标准”: 每个对话都有由医生专门编写的、极其细致的“评分细则”(Rubric)。总共包含了48,562条独特的评分标准!这些标准非常具体,比如“是否提到了某个关键副作用”、“沟通是否清晰易懂”、“是否注意到了用户的特殊情况”等等,有加分项也有减分项 (-10到+10分)
智能+专家验证的评分: 使用一个经过验证的模型(GPT-4.1)作为“评分员”,对照医生写的评分细则,给模型的回复打分。这保证了大规模评估的可行性,同时信度也经过了与医生评分的比对验证(后面会细说)
覆盖广泛且深入:
七大主题 (Themes): 覆盖了急诊分流、全球健康、处理不确定性、专业沟通、上下文理解、医疗数据任务、回复深度等关键医疗交互场景
五大行为维度 (Axes): 从准确性 (Accuracy)、完整性 (Completeness)、沟通质量 (Communication quality)、上下文意识 (Context awareness)、指令遵循 (Instruction following) 五个角度全面考察模型行为
简单说,HealthBench就是想用一套更接近真实世界医疗需求的“模拟考”,来检验AI模型的“医术”和“医德”
HealthBench上的模型表现:进步神速,但挑战仍在
OpenAI在HealthBench上评估了一系列自家和别家的模型,结果很有看点:
1.模型进步飞快:
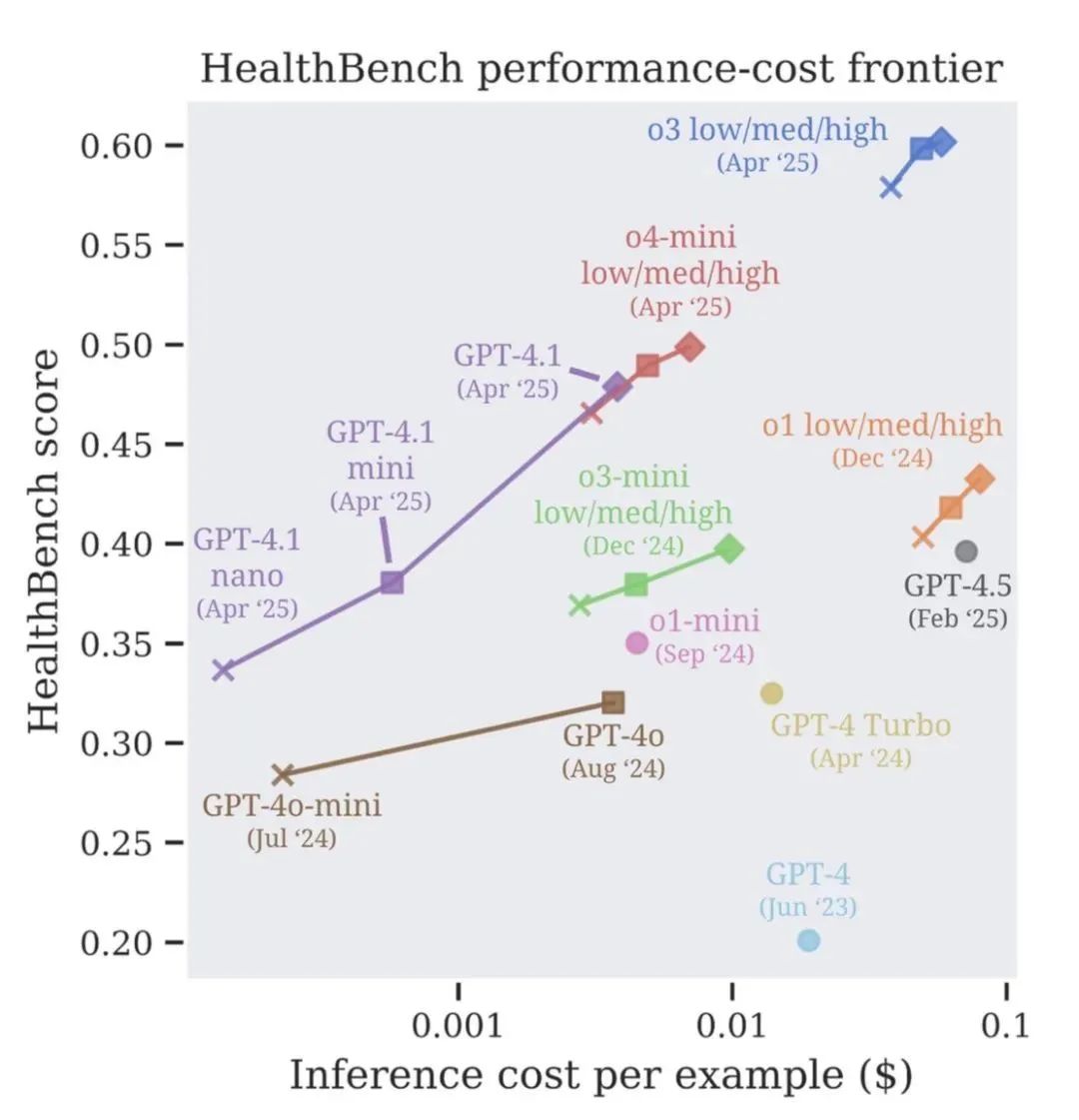
从GPT-3.5 Turbo的16%得分,到GPT-40的32%,再到最新o3模型的60%!进步速度,尤其是近期的提升,非常显著
看性能-成本前沿 ,新的模型(如o3, o4-mini, GPT-4.1)不仅性能更强,而且在不同成本档位上都定义了新的标杆
特别亮眼的是小模型的崛起:GPT-4.1 nano的性能居然超过了2024年8月发布的GPT-40,而且便宜了整整25倍!这意味着高性能AI医疗辅助未来可能更加普惠
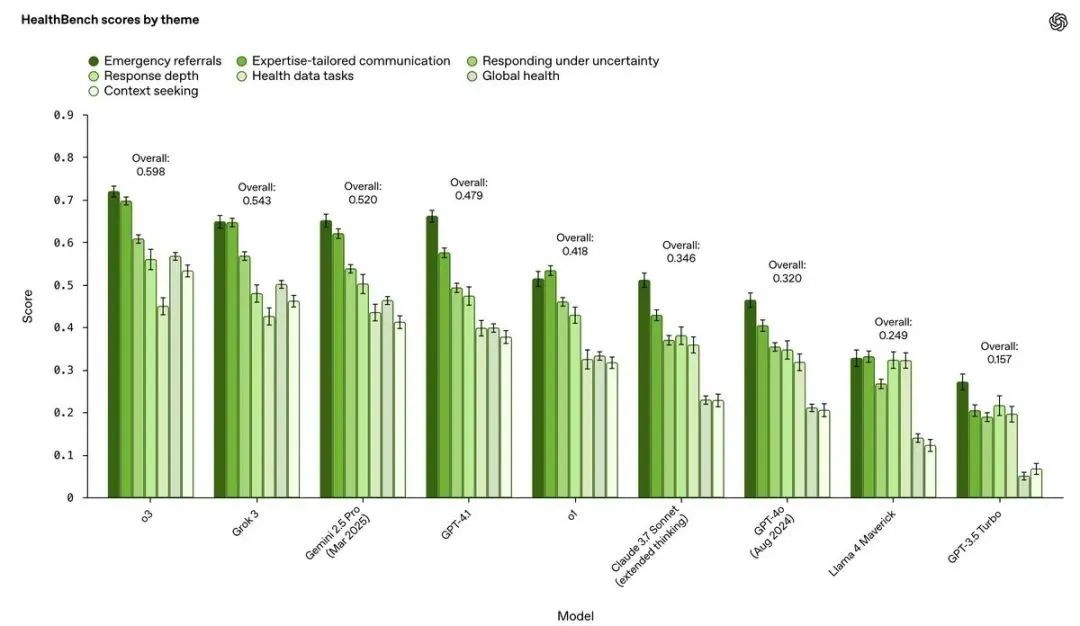
2.强项与软肋并存 :
模型在“急诊分流”、“专业沟通”这类主题上普遍得分较高
但在需要主动“寻求上下文信息” (Context seeking)、处理“医疗数据任务”和“全球健康”场景下,表现相对落后。这说明模型在信息不全时主动追问、处理结构化数据、适应不同地域医疗环境方面,还有很大提升空间
从行为维度看,“完整性” (Completeness) 和“上下文意识”是普遍的失分点,而准确性相对较好。
3.可靠性提升,但离“万无一失”还远 :
医疗场景不能只看平均分,一次“翻车”就可能造成严重后果。HealthBench引入了“最差情况下的表现”(worst-at-k)评估
结果显示,新模型(如o3)的可靠性比老模型(如GPT-40)提升了一倍多
但即使是最好的o3模型,在重复测试16次的最差情况下,得分也会从60%掉到约40%,说明在某些难题上,模型表现仍不稳定,需要持续改进
4.模型变强,不只因为“话痨” :
有人担心模型分高是不是纯靠回复长、显得全面?HealthBench做了对比
结果显示,新模型得分高,确实部分因为回复更详细周到,但更重要的是模型本身能力的提升。即使控制回复长度相近,强模型依然优势明显。
两个特别版:聚焦关键问题和未来挑战
HealthBench还推出了两个特别版本:
HealthBench Consensus (共识版): 只包含34个被多位医生一致认为极其重要、且达成共识的关键评分标准(比如,在紧急情况下是否清晰建议立即就医)。这部分错误率极低,更聚焦于模型的“底线安全”。数据显示,模型在这方面的错误率已从GPT-3.5时代大幅降低了超过4倍 ,但像“寻求上下文”、“处理不确定性”等方面仍有改进空间
HealthBench Hard (困难版): 精选了1000个对当前最强模型来说也极具挑战性的难题。目前最强的o3模型在此得分仅为32% ,为下一代模型的突破留足了空间,堪称“攻坚靶场”
评分模型靠谱吗?元评估告诉你
用模型给模型打分,这个“裁判”自己公正吗?HealthBench对此进行了“元评估”(Meta-evaluation),专门针对HealthBench Consensus中的标准进行
他们比较了模型评分员(GPT-4.1)的打分结果和多位医生的打分结果的一致性(用Macro F1分数衡量)
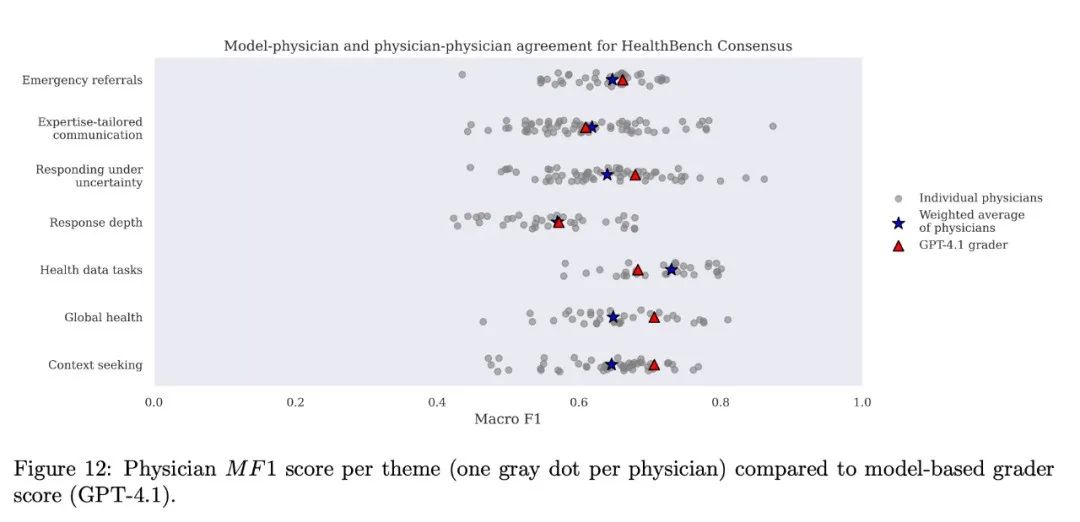
结果显示:
GPT-4.1评分员的表现,在7个主题中的5个超过了医生的平均水平
在所有主题上,其表现都处于医生群体中的中上游水平(超过了51.5%到88.2%的医生)
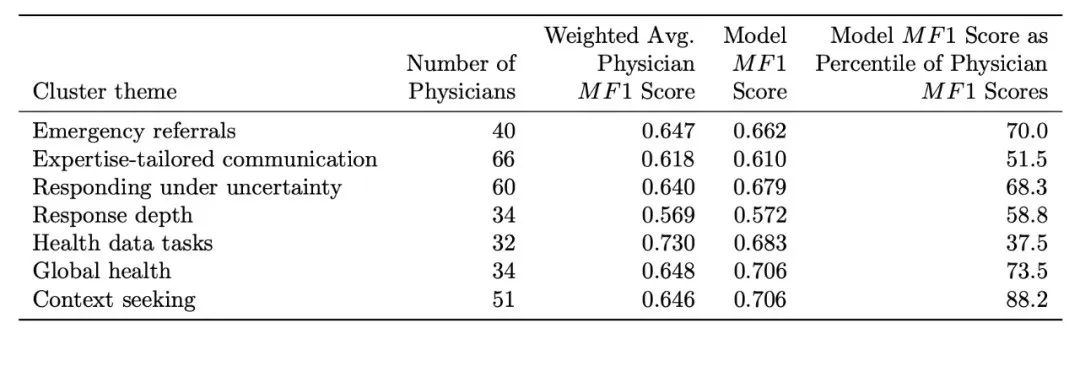
整体评分的波动性很小(标准差约0.002),说明结果稳定
结论:精心选择和调优后的模型评分员,其评分能力和一致性可以媲美人类专家,是可靠的
写在最后
当然HealthBench也有局限,比如医生间本身就存在观点差异,评分细则无法做到对每个案例都100%完美覆盖。
更多细节:
HealthBench的数据和代码已经在GitHub上开源:
https://github.com/openai/simple-evals
阅读最新前沿科技趋势报告,请访问欧米伽研究所的“未来知识库”
https://wx.zsxq.com/group/454854145828

未来知识库是“欧米伽未来研究所”建立的在线知识库平台,收藏的资料范围包括人工智能、脑科学、互联网、超级智能,数智大脑、能源、军事、经济、人类风险等等领域的前沿进展与未来趋势。目前拥有超过8000篇重要资料。每周更新不少于100篇世界范围最新研究资料。欢迎扫描二维码或访问https://wx.zsxq.com/group/454854145828 进入。

截止到3月31日 ”未来知识库”精选的百部前沿科技趋势报告
(加入未来知识库,全部资料免费阅读和下载)
牛津未来研究院 《将人工智能安全视为全球公共产品的影响、挑战与研究重点》
麦肯锡:超级智能机构:赋能人们释放人工智能的全部潜力
AAAI 2025 关于人工智能研究未来研究报告
斯坦福:2025 斯坦福新兴技术评论:十项关键技术及其政策影响分析报告(191 页)
壳牌:2025 能源安全远景报告:能源与人工智能(57 页)
盖洛普 & 牛津幸福研究中心:2025 年世界幸福报告(260 页)
Schwab :2025 未来共生:以集体社会创新破解重大社会挑战研究报告(36 页)
IMD:2024 年全球数字竞争力排名报告:跨越数字鸿沟人才培养与数字法治是关键(214 页)
DS 系列专题:DeepSeek 技术溯源及前沿探索,50 页 ppt
联合国人居署:2024 全球城市负责任人工智能评估报告:利用 AI 构建以人为本的智慧城市(86 页)
TechUK:2025 全球复杂多变背景下的英国科技产业:战略韧性与增长路径研究报告(52 页)
NAVEX Global:2024 年十大风险与合规趋势报告(42 页)
《具身物理交互在机器人 - 机器人及机器人 - 人协作中的应用》122 页
2025 - 2035 年人形机器人发展趋势报告 53 页
Evaluate Pharma:2024 年全球生物制药行业展望报告:增长驱动力分析(29 页)
【AAAI2025 教程】基础模型与具身智能体的交汇,350 页 ppt
Tracxn:2025 全球飞行汽车行业市场研究报告(45 页)
谷歌:2024 人工智能短跑选手(AI Sprinters):捕捉新兴市场 AI 经济机遇报告(39 页)
【斯坦福博士论文】构建类人化具身智能体:从人类行为中学习
《基于传感器的机器学习车辆分类》最新 170 页
美国安全与新兴技术中心:2025 CSET 对美国人工智能行动计划的建议(18 页)
罗兰贝格:2024 人形机器人的崛起:从科幻到现实:如何参与潜在变革研究报告(11 页)
兰德公司:2025 从研究到现实:NHS 的研究和创新是实现十年计划的关键报告(209 页)
康桥汇世(Cambridge Associates):2025 年全球经济展望报告(44 页)
国际能源署:2025 迈向核能新时代
麦肯锡:人工智能现状,组织如何重塑自身以获取价值
威立(Wiley):2025 全球科研人员人工智能研究报告(38 页)
牛津经济研究院:2025 TikTok 对美国就业的量化影响研究报告:470 万岗位(14 页)
国际能源署(IEA):能效 2024 研究报告(127 页)
Workday :2025 发挥人类潜能:人工智能(AI)技能革命研究报告(20 页)
CertiK:Hack3D:2024 年 Web3.0 安全报告(28 页)
世界经济论坛:工业制造中的前沿技术:人工智能代理的崛起》报告
迈向推理时代:大型语言模型的长链推理研究综述
波士顿咨询:2025 亚太地区生成式 AI 的崛起研究报告:从技术追赶者到全球领导者的跨越(15 页)
安联(Allianz):2025 新势力崛起:全球芯片战争与半导体产业格局重构研究报告(33 页)
IMT:2025 具身智能(Embodied AI)概念、核心要素及未来进展:趋势与挑战研究报告(25 页)
IEEE:2025 具身智能(Embodied AI)综述:从模拟器到研究任务的调查分析报告(15 页)
CCAV:2025 当 AI 接管方向盘:自动驾驶场景下的人机交互认知重构、变革及对策研究报告(124 页)
《强化学习自我博弈方法在兵棋推演分析与开发中的应用》最新 132 页
《面向科学发现的智能体人工智能:进展、挑战与未来方向综述》
全国机器人标准化技术委员会:人形机器人标准化白皮书(2024 版)(96 页)
美国国家科学委员会(NSB):2024 年研究与发展 - 美国趋势及国际比较(51 页)
艾昆纬(IQVIA):2025 骨科手术机器人技术的崛起白皮书:创新及未来方向(17 页)
NPL&Beauhurst:2025 英国量子产业洞察报告:私人和公共投资的作用(25 页)
IEA PVPS:2024 光伏系统经济与技术关键绩效指标(KPI)使用最佳实践指南(65 页)
AGI 智能时代:2025 让 DeepSeek 更有趣更有深度的思考研究分析报告(24 页)
2025 军事领域人工智能应用场景、国内外军事人工智能发展现状及未来趋势分析报告(37 页)
华为:2025 鸿蒙生态应用开发白皮书(133 页
《超级智能战略研究报告》
中美技术差距分析报告 2025
欧洲量子产业联盟(QuIC):2024 年全球量子技术专利态势分析白皮书(34 页)
美国能源部:2021 超级高铁技术(Hyperloop)对电网和交通能源的影响研究报告(60 页)
罗马大学:2025 超级高铁(Hyperloop):第五种新型交通方式 - 技术研发进展、优势及局限性研究报告(72 页)
兰德公司:2025 灾难性网络风险保险研究报告:市场趋势与政策选择(93 页)
GTI:2024 先进感知技术白皮书(36 页)
AAAI:2025 人工智能研究的未来报告:17 大关键议题(88 页)
安联 Allianz2025 新势力崛起全球芯片战争与半导体产业格局重构研究报告
威达信:2025 全球洪水风险研究报告:现状、趋势及应对措施(22 页)
兰德公司:迈向人工智能治理研究报告:2024EqualAI 峰会洞察及建议(19 页)
哈佛商业评论:2025 人工智能时代下的现代软件开发实践报告(12 页)
德安华:全球航空航天、国防及政府服务研究报告:2024 年回顾及 2025 年展望(27 页)
奥雅纳:2024 塑造超级高铁(Hyperloop)的未来:监管如何推动发展与创新研究报告(28 页)
HSOAC:2025 美国新兴技术与风险评估报告:太空领域和关键基础设施(24 页)
Dealroom:2025 欧洲经济与科技创新发展态势、挑战及策略研究报告(76 页)
《无人机辅助的天空地一体化网络:学习算法技术综述》
谷歌云(Google Cloud):2025 年 AI 商业趋势白皮书(49 页)
《新兴技术与风险分析:太空领域与关键基础设施》最新报告
150 页!《DeepSeek 大模型生态报告》
军事人工智能行业研究报告:技术奇点驱动应用加速智能化重塑现代战争形态 - 250309(40 页)
真格基金:2024 美国独角兽观察报告(56 页)
璞跃(Plug and Play):2025 未来商业研究报告:六大趋势分析(67 页)
国际电工委员会(IEC):2025 智能水电技术与市场展望报告(90 页)
RWS:2025 智驭 AI 冲击波:人机协作的未来研究报告(39 页)
国际电工委员会(IEC):2025 智能水电技术与市场展望报告(90 页)
RWS:2025 智驭 AI 冲击波:人机协作的未来研究报告(39 页)
未来今日研究所 2025 年科技趋势报告第 18 版 1000 页
模拟真实世界:多模态生成模型的统一综述
中国信息协会低空经济分会:低空经济发展报告(2024 - 2025)(117 页)
浙江大学:2025 语言解码双生花:人类经验与 AI 算法的镜像之旅(42 页)
人形机器人行业:由 “外” 到 “内” 智能革命 - 250306(51 页)
大成:2025 年全球人工智能趋势报告:关键法律问题(28 页)
北京大学:2025 年 DeepSeek 原理和落地应用报告(57 页)
欧盟委员会 人工智能与未来工作研究报告
加州大学伯克利分校:面向科学发现的多模态基础模型:在化学、材料和生物学中的应用
电子行业:从柔性传感到人形机器人触觉革命 - 250226(35 页)
RT 轨道交通:2024 年中国城市轨道交通市场数据报告(188 页)
FastMoss:2024 年度 TikTok 生态发展白皮书(122 页)
Check Point:2025 年网络安全报告 - 主要威胁、新兴趋势和 CISO 建议(57 页)
【AAAI2025 教程】评估大型语言模型:挑战与方法,199 页 ppt
《21 世纪美国的主导地位:核聚变》最新报告
沃尔特基金会(Volta Foundation):2024 年全球电池行业年度报告(518 页)
斯坦福:2025 斯坦福新兴技术评论:十项关键技术及其政策影响分析报告(191 页)
国际科学理事会:2025 为人工智能做好国家研究生态系统的准备 - 2025 年战略与进展报告(英文版)(118 页)
光子盒:2025 全球量子计算产业发展展望报告(184 页)
奥纬论坛:2025 塑造未来的城市研究报告:全球 1500 个城市的商业吸引力指数排名(124 页)
Future Matters:2024 新兴技术与经济韧性:日本未来发展路径前瞻报告(17 页)
《人类与人工智能协作的科学与艺术》284 页博士论文
《论多智能体决策的复杂性:从博弈学习到部分监控》115 页
《2025 年技术展望》56 页 slides
大语言模型在多智能体自动驾驶系统中的应用:近期进展综述
【牛津大学博士论文】不确定性量化与因果考量在非策略决策制定中的应用
皮尤研究中心:2024 美国民众对气候变化及应对政策的态度调研报告:气候政策对美国经济影响的多元观点审视(28 页)
空间计算行业深度:发展趋势、关键技术、行业应用及相关公司深度梳理 - 250224(33 页)
Gartner:2025 网络安全中的 AI:明确战略方向研究报告(16 页)
北京大学:2025 年 DeepSeek 系列报告 - 提示词工程和落地场景(86 页)
北京大学:2025 年 DeepSeek 系列报告 - DeepSeek 与 AIGC 应用(99 页)
CIC 工信安全:2024 全球人工智能立法的主要模式、各国实践及发展趋势研究报告(42 页)
中科闻歌:2025 年人工智能技术发展与应用探索报告(61 页)
AGI 智能时代:2025 年 Grok - 3 大模型:技术突破与未来展望报告(28 页)
上下滑动查看更多

















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









