







来源:夕小瑶科技说 原创
作者:任同学
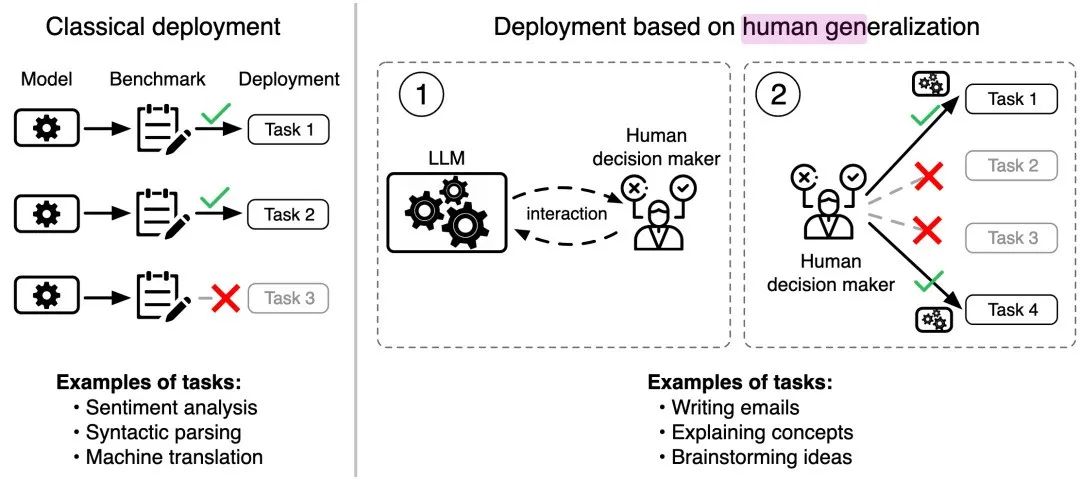
大语言模型(LLMs)展现出了多种用途。这种多样性提供了巨大的潜力:同一个模型可以帮助软件工程师编写代码,也可以总结医生的临床笔记。然而,这种多样性也带来了评价问题:我们如何知道这些模型在不同任务中的表现是否符合我们的期望?
以与监督学习模型相同的方式评估 LLM(通过预先指定任务并根据相关基准进行评估)会低估 LLM 的能力。LLMs能够执行许多任务,而这些任务无法全部列举出来。此外,LLMs将会被用在许多评估者可能无法预见的任务上。解决这个问题的一种方法是通过其可能的部署方式来评价LLMs。这种评价的一个方面是理解人们将选择在何处使用LLMs,例如,医生是否会使用这些模型来总结笔记或回答问题?因此,了解人们关于LLMs性能的信念(belief)非常重要。
来自哈佛大学、麻省理工、芝加哥大学的研究人员对此进行了研究,该研究旨在理解人们如何对LLM在不同任务中的表现形成期望,并评估这些期望与实际表现之间的差异。这一研究的重要性在于,只有理解人们的期望,我们才能更有效地评估和应用这些强大的模型。
什么是人类的泛化行为?
人类泛化行为是指人类提出问题,观察 LLM 如何回应,并推断它会如何回答其他问题,类似于人类根据先前的互动判断其他人的专业知识。 例如,人们可能认为一个可以回答大学物理问题的模型能够回答基础数学问题,但不会推断它回答日本文学问题的能力。
作者继而提出了一个基于人类泛化函数的对齐问题:最好的 LLM 是允许人类对其成功之处做出最可靠推断的 LLM。与人类泛化功能的不一致会对部署的模型产生有害影响:如果人类部署一个在所有单个问题上都更优的模型,来回答它无法回答的问题,那么它的效率就会降低。
论文题目:
Do Large Language Models Perform the Way People Expect? Measuring the Human Generalization Function
论文链接:
http://arxiv.org/abs/2406.01382
论文单位:
Harvard University, Massachusetts Institute of Technology, University of Chicago Booth
方法框架
作者表明, 传统的评估技术会假设问题的分布是固定的, 这可能会提供误导性的性能指标。相反,正确的评估应该包括模拟模型被部署回答问题的概率分布(人类部署分布)。
具体来说,人们根据他们对模型性能的看法和信念,挑选问题让模型回答,从而产生特定问题的分布。这种分布体现了人类对模型能力的信心和期望,这可能取决于他们对模型在以前的互动中表现的观察和推断。
为了研究这个过程, 作者让人们部署 LLM 来回答他们认为它可以正确回答的问题的情况。他们的期望是通过泛化函数形成的,即人类会从一小部分交互中评估 LLM 的整体能力。
评估机器学习模型涉及对如何部署它们做出假设。对于经典的监督学习方法, 这些假设通常很简单:它们将被部署来回答它们被训练来回答的问题类型。因此,通常根据固定的部署分布对模型进行评估 , 其中总体有效性为
例如,专门为执行情感分析而开发的模型将根据其在情感分析基准上的表现进行评估。
通用模型(如 LLM)与特定用途方法的不同之处在于, 它们没有固定的任务集;LLM 的能力远远超出了它们被训练来回答的问题种类。此外, 许多可以部署 LLM 的任务(例如写电子邮件)没有传统评估所需的明确定义的基准数据集。
根据人类部署分布,人们部署 LLM 来回答问题 , 其性能可能取决于模型的输入概率分布 :
这里可以从两方面进行分析。首先,回答正确问题越多的 LLM 的性能理论上会更好。但是通用的模型面对的场景非常广泛,如果人类将模型部署到它无法回答的问题上, 其部署性能将受到影响。
现在我们可以考虑两个模型 ,如果 能正确回答的都能被 正确回答,那么称 相比占支配地位:
在这种情况下, 记作 。当在固定的部署分布下进行评估时, 一个优于另一个模型的模型的性能至少与该模型一样好。也就是说, 如果 ,那么:
然而, 当部署的分布由人决定(人类部署分布), 模型被部署到并不适合它的场景下时,模型之间的关系可能会截然相反:
人类如何形成对 LLM 能力的信念?
作者认为,人类根据他们对模型能力的信念来选择部署分布。例如,企业主可能认为某个 LLM 擅长总结会议记录,但不擅长回复电子邮件,那么他将会把回复电子邮件的任务交给其他模型。
作者的另外一个观点则是,信念可以通过交互而改变。人类不可能通过询问 LLM 所有问题来评估它。但是,用户可以进行泛化,比如,当给定一个模型,人类会提出问题,观察模型如何响应,并得出模型如何回答其他问题的结论。
当人类认为一个问题与另一个问题直接相关时,他们可能会更新自己的信念:他们可能假设能回答加法问题的 LLM 也能够回答减法问题。另一方面,如果两个问题不相关,他们可能根本不会更新自己的信念,比如他们可能仍然会认为一个不擅长回答数学问题的LLM也能在历史领域上有不错的回答。
作者使用人类泛化函数 对此进行建模,该函数总结了人类在观察问题x'和模型响应 后,对 LLM 在问题 x'上的正确性的信念。例如,如果人类对 LLM 在问题 x 和 y 上的正确性有一些联合信念,并根据贝叶斯规则更新他们的信念,则可能会出现这样一个人类泛化函数。
人类泛化与模型部署
人类泛化函数决定了模型将被用来回答的具体问题。因此,模型的已部署性能取决于模型与人类泛化的吻合程度。如果在几次交互之后,人类能够评估模型能够回答的问题,我们称该模型与人类泛化函数一致,因此它将被部署来回答它能够回答的问题。另一方面,如果它不一致,人类可能会过于自信或过于不自信,并部署 LLM 来回答一组次优问题。图 1概述了作者的框架。
举一个具体的示例,现在有两个 LLM 和 ,它们都可以正确回答每个算术问题。假设 无法正确回答任何其他问题,而 还可以正确回答多变量微积分问题,但不能回答单变量微积分问题。此时 支配 ,即 。
如果在与每个模型交互后,用户确定 只能够正确回答基本的算术问题,他们可能会只部署它来回答基本的算术问题。如果他们错误地判断 能够正确回答所有数学问题,用户可能会部署它来回答所有算术、单变量微积分和多变量微积分问题。
那么此时的 的平均部署误差将会更大,因为它的能力与人类泛化函数不一致。
人类如何对大语言模型做出概括性预测
研究者收集了18,972个关于人类如何进行概括性预测的示例。具体的实施方式则是先让参与者预测一个LLM回答给定问题的可能性。然后,向参与者展示模型对另一个问题的回应,并要求他们更新初始预测。这种设计旨在捕捉人们对正确性的先验信念、他们的泛化函数的结果,以及信念的变化。

研究基于 MMLU 基准和 BBH 基准中的问题收集数据。两个基准包含了从数学、文学到法律、商业等多种学科中的实际问题,以及测试LLMs能力(如推理和创造力)的任务。
为了找到能够引起信念改变的问题对,研究者采用了多臂老虎机中的bandit方法。作者使用BERT模型预测哪些问题对最可能导致信念改变,并通过epsilon-greedy采样方法优化问题对的选择。

预测人类对 LLMs 的泛化性预测
研究者收集数据之后,目标变成了如何模拟人类如何基于之前的互动文本改变他们对LLMs的预期。即,评估人类对LLMs反应的预测变化是否是可预测的。
作者提出了一个基准任务,旨在预测个体对LLM回应特定问题后其信念变化的可能性,目标是预测二元结果 。
研究提到了多种模型来预测信念的变化,包括基于文本内容的和非文本内容的模型:从简单的逻辑回归模型(预测基于LLMs对之前问题的正确回答)到复杂的模型如BERT和Llama-2。具体使用了以下六种模型:
Previous correct:不使用文本的基线模型。它预测人的信念是否会改变,仅仅基于 LLM 是否正确回答了问题 。 被建模为逻辑回归。
Previous correct + same task:另一个不使用文本的基线模型。该模型向之前的基线添加了一个附加特征: 和 是否来自相同的任务。该模型被训练为逻辑回归。
Fixed embeddings + XGBoost:此模型使用 VoyageAI 中的固定句子嵌入对每个问题进行嵌入。 和 的嵌入被连接起来,并使用 XGBoost 来预测 上的信念变化。
BERT:微调,然后输入拼接的 和 ,以及一个表示 是否被正确回答的特殊token。
Llama-2 7B/13B:Llama-2 模型经过微调,使用包含 、 和 是否被正确回答的自定义prompt来预测 上的信念变化。
GPT-3.5 turbo:使用 10 个 shot 来提示 GPT-3.5 turbo,并记录模型预测 '0' 或 '1' 的可能性。
GPT-4:使用 10 个 shot 来提示 GPT4。并记录预测概率。
每个模型都在最初的 18,480 个响应对上进行训练,并在测试集上进行评估。
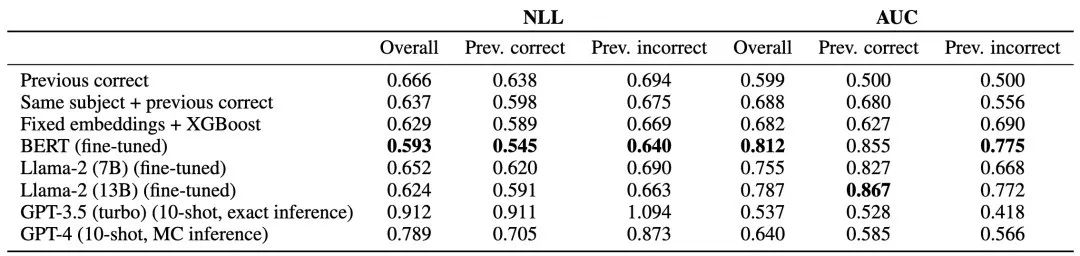
表 1 显示了每个模型在 492 个测试标签上保留的负对数似然(NLL)和 AUC。该实验结果表明了人类泛化函数是可预测的,最好的模型的 AUC 为 0.81,而最简单的非文本基线的 AUC 为 0.60。可以观察到,具有文本的模型比基线模型表现更好,其中 BERT 是最好的模型。
作者还给出了他的两个分析,第一个则是现有的语言模型已经包含了预测人类泛化所需的结构。第二个则是,随着 LLM 变得越来越大,其中一些信息似乎丢失了,而一些更简单、更小的模型(例如 BERT)在预测人类泛化函数上表现出更好的性能。
作者还通过BERT的预测,对人类泛化函数进行了定性分析。结果显示,人类在LLM错误回答一个问题后,更有可能更新他们的信念。

▲图 2:关于问题对和预测信念变化的定性示例。
图 2 显示了具有极端预测的问题对示例。当 LLM 错误地回答化学问题时(图 2左上角),模型预测人类将更新他们对 LLM 正确回答代谢问题的信念的概率很大。当 LLM 正确回答有关人权的问题时,我们也看到类似的模式( 图 2左下角)。
然而,当有两个不相关的题目时,模型预测信念变化的可能性很低:例如,当LLM正确回答有关电视情景喜剧的问题,不会影响人们对它是否能回答基本算术问题(图 2 右上角)的信念。最后,图 2 右下角的示例说明,如果一个人看到 LLM 正确回答了有关颜色的基本问题,他们不太可能改变他们对 LLM 是否能正确回答有关化学的复杂问题的信念。
如果他们看到 LLM 错误地回答了基本问题,他们对复杂问题的信念更有可能改变。预测的人类泛化可能反映了对每个问题不同评估难度的:LLM 正确回答一个较容易的问题几乎不会影响它将如何回答一个更困难的问题,但如果较容易的问题回答不正确,则模型被认为不太可能正确回答更困难的问题。
评估 LLM 与人类泛化的对齐度
在与 LLM 交互后,人类会形成 LLM 有多大概率回答他们没有问的其他问题的评估。模型性能与这些期望有多好的一致性?作者进而评估了 LLM 与人类泛化函数的一致性。
在框架中,在看到 LLM 如何回答问题 x' 之后,人类会形成一个信念,即模型有多大概率正确回答问题 :。人类泛化函数的准确性可以通过将其与 LLM 的响应是否正确进行比较来评估。作者通过下式来评估人类预测的加权广义准确性:
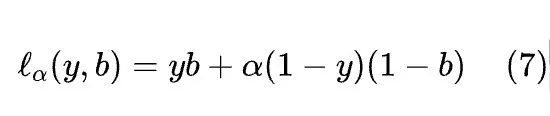
对于 和 。通过改变参数 ,可以改变对不正确响应的相对权重。然后根据以下公式汇总问题对:
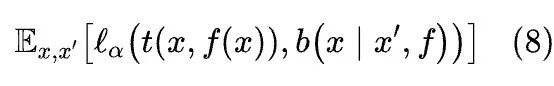
其中 是人类泛化函数的 BERT 模型给出的后验信念的估计。进一步将公式 8 归一化 ,以便加权准确性取值在 0 到 1 之间。
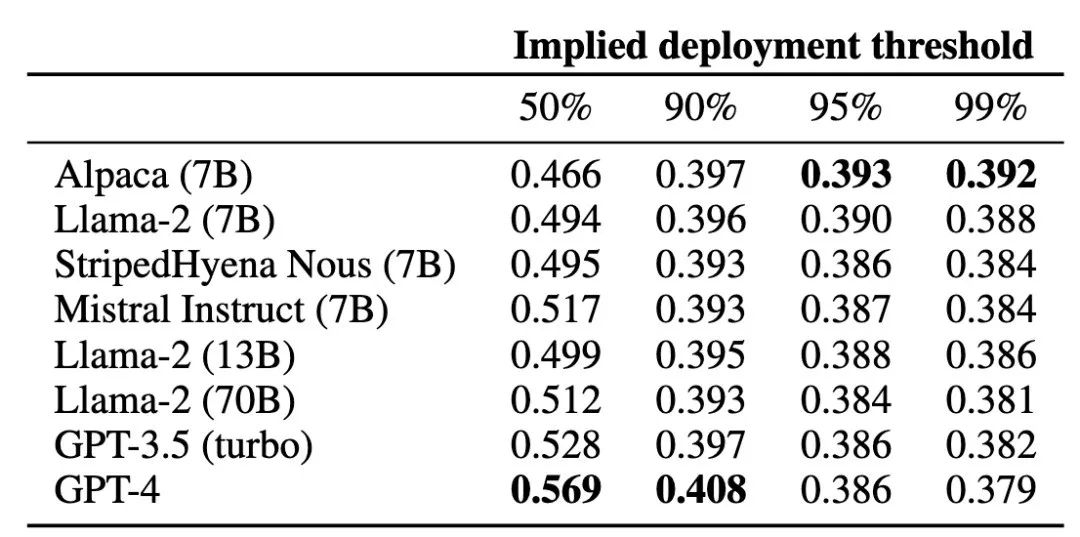
作者认为,无法从 LLM 推广不正确的响应的后果可能比无法推广正确的响应有害得多。这句话有点拗口,我们举个例子,当我们部署 LLM 来提供不合理的医疗建议时,肯定会产生危害,那么这个危害有多大呢?相比于我们原本要部署一个 LLM,但是由于其他原因取消了部署的情况,前者的危害其实是要更大的。
加权广义准确性捕捉到了这种可能的非对称性,因为每个α 的选择都可以映射到特定的部署选择。从这个角度来看, 对应于如果评估的正确性可能性大于 50%,用户将部署 LLM。随着α 的增加,用户变得更加厌恶风险,需要对 LLM 的正确性有更高的信心才能证明其部署是合理的。

在图 4 中,作者也展示了 LLM 没有与人类泛化函数对齐而导致失败的示例。对于每个问题对(x,x'),当看到 LLM 正确回答问题x',受访者增加了他们认为问题x 也将得到正确回答的信念。然而,对于所有示例,Llama-2 (70B) 正确回答了x',但没有回答x。这些示例包含各种人类泛化失败:在第一个示例中,LLM 正确计算了经济量,但未能回答基本的算术问题;在第二个示例中,LLM 正确跟踪了足球队中球员的位置,但无法解决一个措辞非常相似的问题;在最后一个示例中,LLM 可以正确回答有关道德哲学的问题,但不能应用道德推理。
结论
作者引入了一个在人工部署下评估大语言模型的框架,将部署决策与人们对模型能力的信念联系起来,而这种信念是由人类的泛化能力决定的。
作者收集了有关人类泛化功能的数据,并表明它是可预测的。结果表明,当错误成本很高时,更强大的模型在真实使用实例上表现会更差,因为它们与人类的泛化功能不一致。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









