







关键词:大语言模型,深度学习,计算复杂度

来源:集智俱乐部
作者:郭瑞东
大语言模型(LLMs)在人工智能领域取得显著进展,但同时也带来了推理成本方面的挑战。而随着模型变得更加先进,所需的计算资源显著增加,如GPT-4的计算量是GPT-3.5的十倍左右。通常用户会倾向于使用最强大的模型来处理所有任务,而不考虑任务的复杂性。该研究提出一种系统化的方法,微调小型语言模型来评估任务复杂性来自动选择最合适的模型,以减少计算资源的浪费。
https://arxiv.org/pdf/2312.11511

表一:不同模型的成本
这项研究中,首先根据编程问题数据库,给出对应的prompt,之后分别使用Lamma7B,GPT3.5和GPT4 尝试回答问题,每个模型运行五次,计算每个模型的给出正常答案的成功率,之后根据不同模型成功率的差异,定义问题的计算复杂性。具体分级方式如图2所示。
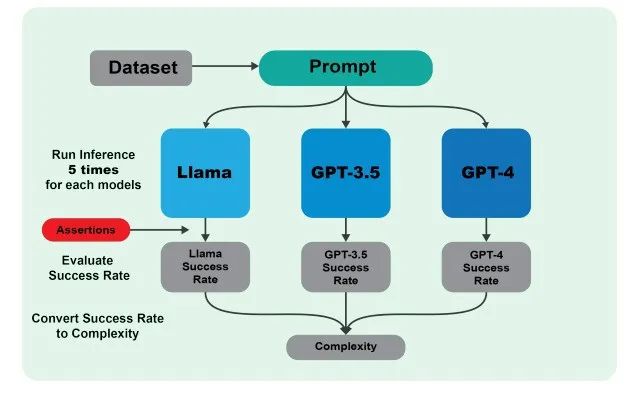
图1:研究所用的问题复杂度如何计算
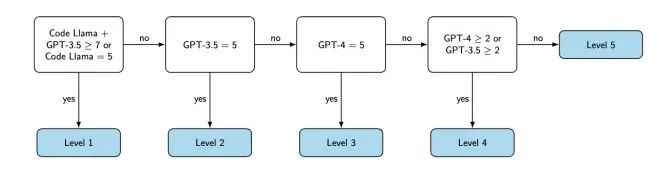
图2:对问题复杂度分级的决策树,例如Lamma五次都答对或Lamma及GPT3.5答对次数超过7次的是一级。
之后研究者基于GPT3.5微调了一个大模型,用于根据prompt预测问题的复杂度,微调后的模型在测试集上达到了79%的准确率,相比未微调的34%有显著提升。
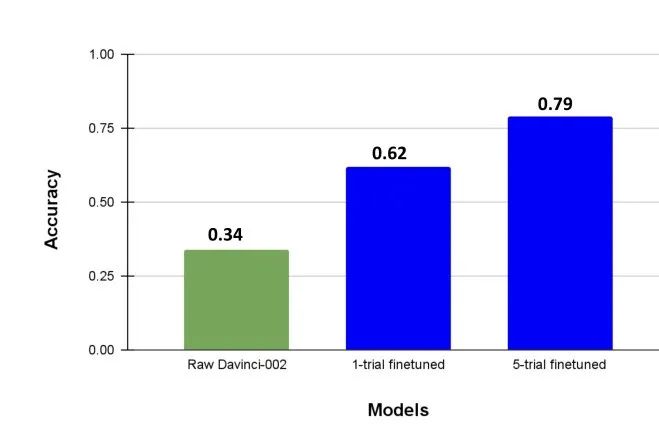
图3:微调后的GPT3.5模型能够预测问题的复杂性
如果对比将所有180道编程题目交给GPT-4进行运算的成本,以及先使用微调后的模型进行复杂度判别,将复杂度1的问题交给Lamma,复杂度2和3的问题交给GPT3.5,而将其余问题使用GPT4回答,先估计复杂度的方法能实现了90%的推理成本降低,同时保持了86.7%的准确率。
总结
这篇论文提出了一个名为 "ComplexityNet" 的框架,旨在通过评估任务复杂性并将其分配给不同能力的LLMs来提高推理效率。与传统的将所有任务分配给最复杂模型的方法相比,该框架通过微调小型模型来预测任务复杂性,并根据预测结果选择最合适的模型,从而在保持高准确率的同时显著降低了计算资源的使用。这项研究为优化LLM应用提供了一个有希望的方向,尤其是在资源受限的环境中。
该研究专注于提高LLMs的使用效率和成本效益,而不是单纯追求模型的规模和能力。它的特点在于提出了一种系统化的方法来评估任务复杂性,并根据评估结果智能选择最合适的模型,这对于资源优化和可持续的AI发展具有重要意义。
类似的方案,不止针对编程类任务。例如针对使用大模型进行翻译的应用场景,可根据输入prompt的复杂度(如信息熵,文本中的结构,单词频率等)来对任务进行分类,并根据复杂度调整推理时采用的模型,从而减少成本。在其它推理类任务中,也可以采取类似该文的方式,根据不同参数大小模型的准确性差异,来定义问题的复杂度,再通过微调小模型来先预测问题的复杂度。而这样简单有效的工具,则说明了计算复杂度这一认知概念,在大模型时代,仍然能够有实用的新应用场景。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









