







 本文详细介绍了循环神经网络(RNN)的发展历史、工作原理及其在序列数据处理中的应用。从RNN的引入,到RNN模型、前向传播和反向传播(BPTT)的详细推导,探讨了RNN面临的梯度消失和梯度爆炸问题以及解决方案,如LSTM和GRU。
本文详细介绍了循环神经网络(RNN)的发展历史、工作原理及其在序列数据处理中的应用。从RNN的引入,到RNN模型、前向传播和反向传播(BPTT)的详细推导,探讨了RNN面临的梯度消失和梯度爆炸问题以及解决方案,如LSTM和GRU。
文章目录
概述
1.RNN的引入
CNN主要适用于计算机视觉,而BP主要是点对点的映射。他们输入的数据维度相同,而且各个输入之间是独立的,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立。在面对有顺序的序列化的数据时,如自然语言处理,处理数据有一定的顺序的时候,显得效果不够好。此时,RNN就能很好的处理这种数据。
也就是说:训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。
2.RNN的发展历史
1982年,美国加州理工学院物理学家John hopfield 发明了一种单层反馈神经网络 Hopfield network,用来解决组合优化问题。这是最早的RNN的雏形。
1990年, 美国认知科学家Jeffrey L. Elman 对jordan network进行了简化,并采用BP算法进行训练,便有了如今最简单的包含单个自连接节点的RNN 模型。但此时RNN由于梯度消失(gradient vanishing)及梯度爆炸(gradient exploding)的问题,训练非常困难,应用非常受限。
1997年,Jurgen Schmidhuber 提出长短期记忆(LSTM),LSTM使用门控单元及记忆机制大大缓解了早期RNN训练的问题。
同样在1997年,Mike Schuster 提出双向RNN模型(Bidirectional RNN)。这两种模型大大改进了早期RNN结构,拓宽了RNN的应用范围,为后续序列建模的发展奠定了基础。此时RNN虽然在一些序列建模任务上取得了不错的效果,但由于计算资源消耗大,后续几年一直没有太大的进展。
2010年,Tomas Mikolov对bengio提出的feedforward Neural network language model (NNLM) 进行了改进,提出了基于RNN的语言模型(RNN LM),并将其用在语音识别任务中,大幅提升了识别精度。在此基础上Tomas Mikolov于2013年提出了大名鼎鼎的word2vec,与NNLM及RNNLM不同,word2vec的目标不再专注于建模语言模型,而是如何利用语言模型学习每个单词的语义化向量(distributed representation),其中distributed representation概念最早要来源于Hinton 1986年的工作。
Word2vec引发了深度学习在自然语言处理领域的浪潮,除此之外还启发了knowledge representation,network representation等新的领域。
2014年,Bengio团队与google几乎同时提出了seq2seq架构,将RNN用于机器翻译,自此机器翻译全面进入到神经机器翻译(NMT)的时代。
2017年,facebook人工智能实验室提出基于卷积神经网络的seq2seq架构,将rnn替换为带有门控单元的cnn,提升效果的同时大幅加快了模型训练速度。
此后不久,google提出transformer架构,使用self-attention代替原有的RNN及CNN,更进一步降低了模型复杂度。
在词表示学习方面,Allen人工智能研究所2018年提出上下文相关的表示学习方法ELMo,利用双向LSTM语言模型对不同语境下的单词学习不同的向量表示,在6个nlp任务上取得了提升。
3.RNN工作原理
以时间序列的数据为例,简单的来说,就是 t t t时刻的输出不仅与 t t t时刻的输入 x ( t ) x^{(t)} x(t)有关,还与前一时刻有关。就是隐藏层之间有连接关系。最后的训练的方式和传统的深度神经网络相同,采用反向传播算法训练。
一、RNN模型
传统的深度神经网络DNN如下图所示:
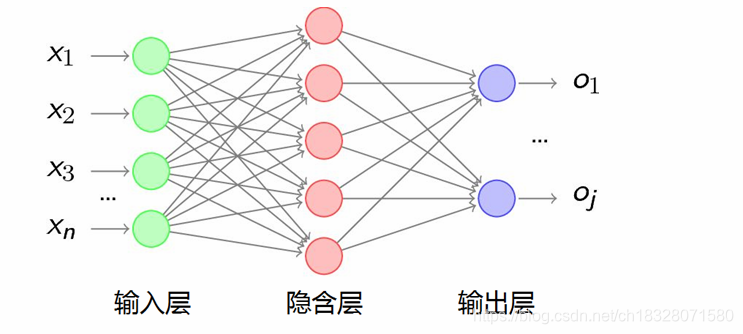
注:上图中的 x 1 , x 2 , x 3 … … , x n x_1,x_2,x_3……,x_n x1,x2,x3……,xn表示一个样本的不同属性。比如在预测男女生的性别时,输出 o 1 , o j o_1,o_j o1,oj表示男生和女生,而输入的 x 1 , x 2 , x 3 … … , x n x_1,x_2,x_3……,x_n x1,x2,x3……,xn可以表示为某个人的身高、体重、喜好等属性。所以, x 1 , x 2 , x 3 … … , x n x_1,x_2,x_3……,x_n x1,x2,x3……,xn整体表示一个样本,这里要和下边RNN讲解的 x t 1 , x t 2 , x t 3 … … , x t n x_{t1},x_{t2},x_{t3}……,x_{tn} xt1,xt2,xt3……,xtn要分开,一个单独的 x t i x^{ti} xti表示 t i t_i ti时刻的一个样本,该样本是许多属性的综合,即 x 1 t i , x 2 t i , x 3 t i , … … , x m t i x^{ti}_1,x^{ti}_2,x^{ti}_3,……,x^{ti}_m x1ti,x2ti,x3ti,……,xmti,表示一个时刻的样本 x t i x_{ti} xti包含了m个属性。故,在RNN中, x t 1 , x t 2 , x t 3 … … , x t n x_{t1},x_{t2},x_{t3}……,x_{tn} x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









