







Week 1
- 对于图像应用,我们经常在神经网络上使用卷积(Convolutional Neural Network),通常缩写为CNN。对于序列数据,例如音频,有一个时间组件,随着时间的推移,音频被播放出来,所以音频是最自然的表现。作为一维时间序列(两种英文说法one-dimensional time series / temporal sequence).对于序列数据,经常使用RNN,一种递归神经网络(Recurrent Neural Network),语言,英语和汉语字母表或单词都是逐个出现的,所以语言也是最自然的序列数据,因此更复杂的RNNs版本经常用于这些应用。
- structured data :dataset
unstructured data:image,voice
Week 2
forward/backward propagation 前向/反向 传播
n = dimension of input feature victor
m = training examples

我们用parameter w来表示逻辑回归的参数,这也是一个nx维向量(因为实际上是特征权重,维度与特征向量相同),参数里面还有b,这是一个实数(表示偏差)。
sigmoid函数的公式是这样的,Z在这里是一个实数
- Loss(error) function:我们称为损失函数,来衡量预测输出值和实际值有多接近。
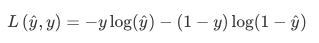
- Cost function :损失函数只适用于单个训练样本,而cost function是用于衡量the entire training set
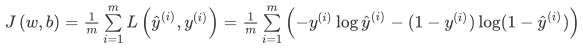
local / global optima 局部/全局最优解
optimize 优化
梯度下降法 gradient decent
derivative 导数
slope 斜率
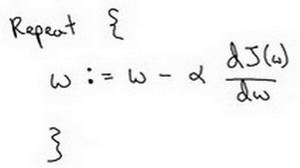
变量命名
dvar:最终的输出变量,你真正想要关心或者说优化的。
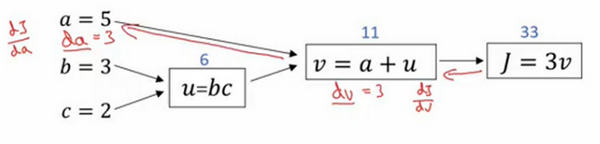
逻辑回归中的梯度下降(Logistic Regression Gradient Descent)


d
a
=
∂
L
∂
a
=
−
y
a
+
1
−
y
1
−
a
da = \frac{∂L}{∂a}=-\frac{y}{a}+\frac{1-y}{1-a}
da=∂a∂L=−ay+1−a1−y
∂
a
∂
z
=
a
(
1
−
a
)
\frac{∂a}{∂z}=a(1-a)
∂z∂a=a(1−a)
d
z
=
∂
L
∂
z
=
∂
L
∂
a
∗
∂
a
∂
z
=
(
−
y
a
+
1
−
y
1
−
a
)
∗
a
(
1
−
a
)
=
a
−
y
dz = \frac{∂L}{∂z}=\frac{∂L}{∂a}*\frac{∂a}{∂z}=(-\frac{y}{a}+\frac{1-y}{1-a})*a(1-a)=a-y
dz=∂z∂L=∂a∂L∗∂z∂a=(−ay+1−a1−y)∗a(1−a)=a−y
d
w
1
=
∂
L
(
w
,
b
)
∂
w
1
=
∂
L
∂
z
∗
∂
z
∂
w
1
=
x
1
∗
d
z
=
x
1
(
a
−
y
)
dw1 = \frac{∂L(w,b)}{∂w1}=\frac{∂L}{∂z}*\frac{∂z}{∂w1}=x1*dz=x1(a-y)
dw1=∂w1∂L(w,b)=∂z∂L∗∂w1∂z=x1∗dz=x1(a−y)
d
b
=
∂
L
(
w
,
b
)
∂
b
=
∂
L
∂
z
∗
∂
z
∂
b
h
=
1
∗
d
z
=
a
−
y
db = \frac{∂L(w,b)}{∂b}=\frac{∂L}{∂z}*\frac{∂z}{∂bh}=1*dz=a-y
db=∂b∂L(w,b)=∂z∂L∗∂bh∂z=1∗dz=a−y
修正量:
w
1
=
w
1
−
α
∗
d
w
1
w1 = w1 - α * dw1
w1=w1−α∗dw1
w
2
=
w
2
−
α
∗
d
w
2
w2 = w2 - α * dw2
w2=w2−α∗dw2
b
=
b
−
α
∗
d
b
b = b - α * db
b=b−α∗db
- 对于整体案例 on m examples
//梯度下降法 gradient decent
J=0;dw1=0;dw2=0;db=0; //dw1,dw2作为累加器, 无下标
for i = 1 to m
z(i) = wx(i)+b;
a(i) = sigmoid(z(i));
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));
dz(i) = a(i)-y(i);
{
dw1 += x1(i)dz(i);
dw2 += x2(i)dz(i);
...n loop}
db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
{n loop
w=w-alpha*dw
b=b-alpha*db
}
weekness: n for loop in m for loop
solution:Vectorization
向量化
# 向量化计算 z=wTx + b
z=np.dot(w,x)+b

jupyter notebook上面实现,这里只有CPU,CPU和GPU都有并行化的指令,GPU更加擅长SIMD计算,但是CPU事实上也不是太差。
exponential operation 指数操作
# 梯度下降法 gradient decent using np 减少一次for loop
import numpy as np
J=0 # cost 函数
db=0 # dj/db
dw = np.zeros((nx,1))
for i = 1 to m:
z(i) = wx(i)+b
a(i) = sigmoid(z(i))
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i))
dz(i) = a(i)-y(i)
dw += x(i)dz(i)
db += dz(i)
J/= m
dw/= m
db/= m

输入矩阵X(nx,m)
import numpy as np
Z = np.dot(w.T,X) + b # Z:1xm 矩阵 b:py自动将实数b扩展成了一个1xm的行向量(broadcosting)
A = np.sigmod(Z)
dZ = A - Y
db = np.sum(dZ) / m
dw = X * dZt / m
w = w - αdw
b = b - αdb
python 中的broadcasting


编程作业1-识别猫
- Actually, we rarely use the “math” library in deep learning because the inputs of the functions are real numbers. In deep learning we mostly use matrices and vectors. This is why numpy is more useful.
- Please don’t hardcode the dimensions of image as a constant. Instead look up the quantities you need with
image.shape[0], etc.
softmax:
- s o f t m a x ( x ) = s o f t m a x [ x 11 x 12 x 13 … x 1 n x 21 x 22 x 23 … x 2 n ⋮ ⋮ ⋮ ⋱ ⋮ x m 1 x m 2 x m 3 … x m n ] = [ e x 11 ∑ j e x 1 j e x 12 ∑ j e x 1 j e x 13 ∑ j e x 1 j … e x 1 n ∑ j e x 1 j e x 21 ∑ j e x 2 j e x 22 ∑ j e x 2 j e x 23 ∑ j e x 2 j … e x 2 n ∑ j e x 2 j ⋮ ⋮ ⋮ ⋱ ⋮ e x m 1 ∑ j e x m j e x m 2 ∑ j e x m j e x m 3 ∑ j e x m j … e x m n ∑ j e x m j ] = ( s o f t m a x (first row of x) s o f t m a x (second row of x) . . . s o f t m a x (last row of x) ) softmax(x) = softmax\begin{bmatrix} x_{11} & x_{12} & x_{13} & \dots & x_{1n} \\ x_{21} & x_{22} & x_{23} & \dots & x_{2n} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ x_{m1} & x_{m2} & x_{m3} & \dots & x_{mn} \end{bmatrix} = \begin{bmatrix} \frac{e^{x_{11}}}{\sum_{j}e^{x_{1j}}} & \frac{e^{x_{12}}}{\sum_{j}e^{x_{1j}}} & \frac{e^{x_{13}}}{\sum_{j}e^{x_{1j}}} & \dots & \frac{e^{x_{1n}}}{\sum_{j}e^{x_{1j}}} \\ \frac{e^{x_{21}}}{\sum_{j}e^{x_{2j}}} & \frac{e^{x_{22}}}{\sum_{j}e^{x_{2j}}} & \frac{e^{x_{23}}}{\sum_{j}e^{x_{2j}}} & \dots & \frac{e^{x_{2n}}}{\sum_{j}e^{x_{2j}}} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \frac{e^{x_{m1}}}{\sum_{j}e^{x_{mj}}} & \frac{e^{x_{m2}}}{\sum_{j}e^{x_{mj}}} & \frac{e^{x_{m3}}}{\sum_{j}e^{x_{mj}}} & \dots & \frac{e^{x_{mn}}}{\sum_{j}e^{x_{mj}}} \end{bmatrix} = \begin{pmatrix} softmax\text{(first row of x)} \\ softmax\text{(second row of x)} \\ ... \\ softmax\text{(last row of x)} \\ \end{pmatrix} softmax(x)=softmax⎣⎢⎢⎢⎡x11x21⋮xm1x12x22⋮xm2x13x23⋮xm3……⋱…x1nx2n⋮xmn⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎡∑jex1jex11∑jex2jex21⋮∑jexmjexm1∑jex1jex12∑jex2jex22⋮∑jexmjexm2∑jex1jex13∑jex2jex23⋮∑jexmjexm3……⋱…∑jex1jex1n∑jex2jex2n⋮∑jexmjexmn⎦⎥⎥⎥⎥⎥⎤=⎝⎜⎜⎛softmax(first row of x)softmax(second row of x)...softmax(last row of x)⎠⎟⎟⎞
# Example of a picture
index = 9
plt.imshow(train_set_x_orig[index])
print ("y = " + str(train_set_y[0,index]) + ", it's a '" + classes[np.squeeze(train_set_y[:, index])].decode("utf-8") + "' picture.")
# np.squeeze(train_set_y[:, index]) = 1 或者 0
print("【使用np.squeeze:" + str(np.squeeze(train_set_y[:,index])) + ",不使用np.squeeze: " + str(train_set_y[:,index]) + "】")
X.shape = [209,64,64,3] 209张64x64 的rgb三通道图片
A trick when you want to flatten a matrix X of shape (a,b,c,d) to a matrix X_flatten of shape (b
∗
*
∗c
∗
*
∗d, a) is to use:
X_flatten = X.reshape(X.shape[0], -1).T # X.T is the transpose of X
这一段意思是指把数组变为209行的矩阵(因为训练集里有209张图片),但是我懒得算列有多少,于是我就用-1告诉程序你帮我算,最后程序算出来时12288列,我再最后用一个T表示转置,这就变成了12288行,209列。测试集亦如此。
#使用断言来确保我要的数据是正确的
assert(w.shape == (dim, 1)) #w的维度是(dim,1)
assert(isinstance(b, float) or isinstance(b, int)) #b的类型是float或者是int
z = np.dot(w.T,X)+b # np.dot 而不是*
Week 3
双层(单隐藏层)神经网络结构
第0层:输入层 input layer:a[0] = X(activation)
第1层:隐藏层 hidden layer:a[1] :a[1]1,a[1]2,a[1]3…(hidden units)
第2层:输出层 output layer:a[2] 实数 = yhat
(层数2层,不计输入层)



在垂直方向,垂直索引对应于神经网络中的不同units。例如,位于矩阵的最左上的节点,它对应着第一个训练样本上的第一个隐藏单元的激活函数。它的下方一个位置对应于第二个隐藏单元的激活值。
水平扫描,将从第一个训练样本到第二个训练样本,第三个训练样本……直到右上角节点对应于第一个隐藏单元的激活值,且这个隐藏单元是位于这个训练样本中的最终训练样本。
激活函数(g)
- 二元分类时的output layer 可用sigmoid
g ′ ( z ) = a ( 1 − a ) g'(z)=a(1-a) g′(z)=a(1−a)
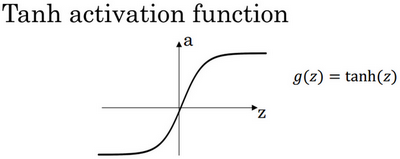
- tanh函数或者双曲正切函数(多数情况下优于sigmoid):
a = t a n h ( z ) = [ e z − e − z e z + e − z ] a = tanh(z) = \begin{bmatrix}\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}}\end{bmatrix} a=tanh(z)=[ez+e−zez−e−z]
g ′ ( z ) = 1 − a 2 g'(z)=1-a^2 g′(z)=1−a2
- ReLu 函数 rectified linear unit:(most)
a = g ( z ) = m a x ( 0 , z ) a =g(z)= max(0,z) a=g(z)=max(0,z)
g ′ ( z ) = { 0 if z<0 1 if z>0 u n d e f i n e d if z=0 g'(z)= \begin{cases} 0& \text{if z<0}\\ 1& \text{if z>0}\\ undefined& \text{if z=0} \end{cases} g′(z)=⎩⎪⎨⎪⎧01undefinedif z<0if z>0if z=0
(在z=0时没有定义,但是在实际应用中可以赋值成1或0即改第二项为 if z>=0,当然z=0的情况很少) - Leaky ReLu
a = g ( z ) = m a x ( 0.01 z , z ) a =g(z)= max(0.01z,z) a=g(z)=max(0.01z,z)
g ′ ( z ) = { 0.01 if z<0 1 if z>0 u n d e f i n e d if z=0 g'(z)= \begin{cases} 0.01& \text{if z<0}\\ 1& \text{if z>0}\\ undefined& \text{if z=0} \end{cases} g′(z)=⎩⎪⎨⎪⎧0.011undefinedif z<0if z>0if z=0
- 线性激活函数:隐藏单元不能使用,机器学习中的回归问题输出层可能可以使用
g ( z ) = z g(z) = z g(z)=z
神经网络的梯度下降
layers:
- n[0] = nx
- n[1] = 层数(4)
- n[2] = 1
parameters:
- w[1] (n[1],n[0])
- b[1] (n[1],1)
- w[2] (n[2],n[1])
- b[2] (n[2],1)

dz[1]= W[2]Tdz[2] * g[1]’(z[1])
随机初始化
使所有隐藏单元计算相同的函数由于对称原则
w 随机且取较小值,如果较大使得z较大,则在ReLu函数中处于斜率较为平缓的位置,会导致梯度下降迭代速度变慢。b可以初始化为0。
W = np.random.rand((2,2))* 0.01
b = np.zero((2,1))
weekly test
a[2](12) denotes the activation vector of the 2nd layer for the 12th training example.
a[2]4 is the activation output by the 4thneuron of the 2nd layer
#安装包的timeout问题
pip3 install --index-url https://pypi.douban.com/simple scipy
用pip(pip3)安装依赖包时默认访问https://pypi.python.org/simple/,但是经常出现不稳定以及访问速度非常慢的情况导致安装超时,此时可以换国内厂商提供的pipy镜像。
#查看pip安装属性
import pip._internal
print(pip._internal.pep425tags.get_supported())
Week 4 Deep Neural Network
核对矩阵的维度
z[1] = w[1] (np.dot) x + b
z[l] = (n[l], 1)
x(a[0]) = (n[0], 1)
w[l] = (n[l], n[l-1])
vectorized
Z[1] = (n[1], m)
W[1] = (n[1], n[0])
X = (n[0], m)
b[1] = (n[1], 1)(remain the same, since the broadcasting of py)

z = wx + b
Remember that when we compute W X + b W X + b WX+b in python, it carries out broadcasting. For example, if:
W = [ j k l m n o p q r ] X = [ a b c d e f g h i ] b = [ s t u ] W = \begin{bmatrix} j & k & l\\ m & n & o \\ p & q & r \end{bmatrix}\;\;\; X = \begin{bmatrix} a & b & c\\ d & e & f \\ g & h & i \end{bmatrix} \;\;\; b =\begin{bmatrix} s \\ t \\ u \end{bmatrix} W=⎣⎡jmpknqlor⎦⎤X=⎣⎡adgbehcfi⎦⎤b=⎣⎡stu⎦⎤
Then W X + b WX + b WX+b will be:
W X + b = [ ( j a + k d + l g ) + s ( j b + k e + l h ) + s ( j c + k f + l i ) + s ( m a + n d + o g ) + t ( m b + n e + o h ) + t ( m c + n f + o i ) + t ( p a + q d + r g ) + u ( p b + q e + r h ) + u ( p c + q f + r i ) + u ] WX + b = \begin{bmatrix} (ja + kd + lg) + s & (jb + ke + lh) + s & (jc + kf + li)+ s\\ (ma + nd + og) + t & (mb + ne + oh) + t & (mc + nf + oi) + t\\ (pa + qd + rg) + u & (pb + qe + rh) + u & (pc + qf + ri)+ u \end{bmatrix} WX+b=⎣⎡(ja+kd+lg)+s(ma+nd+og)+t(pa+qd+rg)+u(jb+ke+lh)+s(mb+ne+oh)+t(pb+qe+rh)+u(jc+kf+li)+s(mc+nf+oi)+t(pc+qf+ri)+u⎦⎤















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









