






 文章介绍了一个名为UniAD的综合端到端自动驾驶架构,旨在解决模块化任务中的误差累积和协调问题。UniAD通过统一的查询接口融合感知、预测和规划任务,利用Transformer解码器模块处理驾驶场景中的实体交互。通过联合训练,感知和预测任务的性能得到提升,同时对规划任务的贡献也得到验证。文章还探讨了不同模块的设计影响,并展示了UniAD在不同驾驶情况下的表现,尽管面临计算资源需求高等挑战。
文章介绍了一个名为UniAD的综合端到端自动驾驶架构,旨在解决模块化任务中的误差累积和协调问题。UniAD通过统一的查询接口融合感知、预测和规划任务,利用Transformer解码器模块处理驾驶场景中的实体交互。通过联合训练,感知和预测任务的性能得到提升,同时对规划任务的贡献也得到验证。文章还探讨了不同模块的设计影响,并展示了UniAD在不同驾驶情况下的表现,尽管面临计算资源需求高等挑战。
abstract
现代自动驾驶系统通常是模块化的序列任务,即感知预测规划,当代放大要么采用每个任务单独模型,要么设计多head的多任务范式,这种方式很容易造成累积误差和任务协调不足,而一个好的框架应该应该为一个最终目标而设计和优化,即自驾车规划。因此设计一个综合的端到端架构合并全栈驾驶任务,即UniAD。它充分利用每个模块优势,从全局的视角出发为agent的交互提供互补的特征提取。所有任务通过统一的查询接口进行通信,为最终的planning目标彼此促进。
introduction
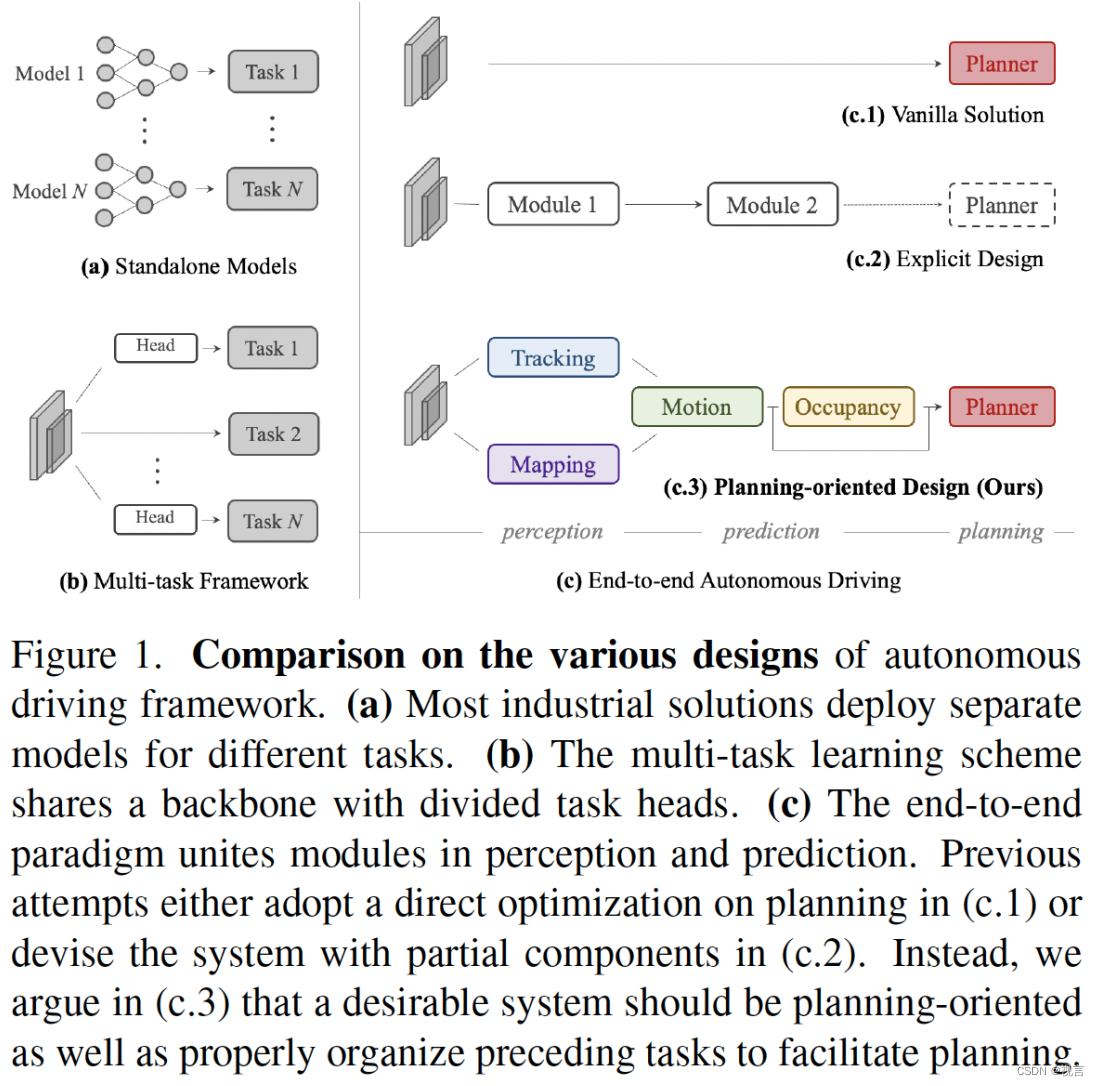
a) Most industrial solutions deploy separate models for different tasks.工业界的大多数解决方案为不同的任务部署了单独的模型, 虽然简化了团队难度,但是可能会有跨模块信息丢失、错误积累和特征错位的问题。
b) The multi-task learning scheme shares a backbone with divided task heads. 将多个任务整合到多任务学习中。这种可以利用feature abstraction协同训练,可以扩展任务,节约计算。 同时也可能会导致‘negative transfer’。
c) 端到端自动驾驶的出现将感知perception、预测prediction和规划planning的所有节点统一为一个整体。这样的系统,前期任务的选择和优先级应有利于规划。系统应以规划为导向,设计精巧,涉及到一定的组成部分,使得独立选项的累积误差或MTL方案的negative transfer都很少。以前的尝试要么在 (c.1) 中采用直接优化规划,即直接预测计划轨迹,而不对感知和预测进行任何明确监督, 但在安全保障和可解释性方面存在不足,特别是对于高度动态的城市场景。要么在 (c.2) 中设计具有部分组件的系统, 一种直观的解决方案是感知周围的物体、预测未来的行为并明确计划安全操作, 这个就取决于这个中间的细节考虑。
为了实现可靠且面向规划的自动驾驶系统,如何设计有利于规划的管道?哪些前置任务是必需的?(c.3) : A desirable system should be planning-oriented as well as properly organize preceding tasks to facilitate planning.(理想的系统应该以规划为导向,并适当组织前期任务以促进规划。)UniAD,一个统一的自动驾驶算法框架,可以利用五个基本任务来实现如图所示的safe and robust的系统。UniAD 本着 planning-oriented 精神设计,不仅仅是简单的工程任务堆栈。
Contributions
UniAD拥抱了一种面向planning哲学的自动驾驶新框架,完成感知、预测和规划等多种任务的联合协作
一个关键组件是连接所有nodes的基于query的设计;与经典的边界框表示相比,query受益于更大的感受野,可以减轻上游预测的compounding error;此外,query可以灵活地对各种交互进行建模和编码,例如多个agents之间的关系。
method
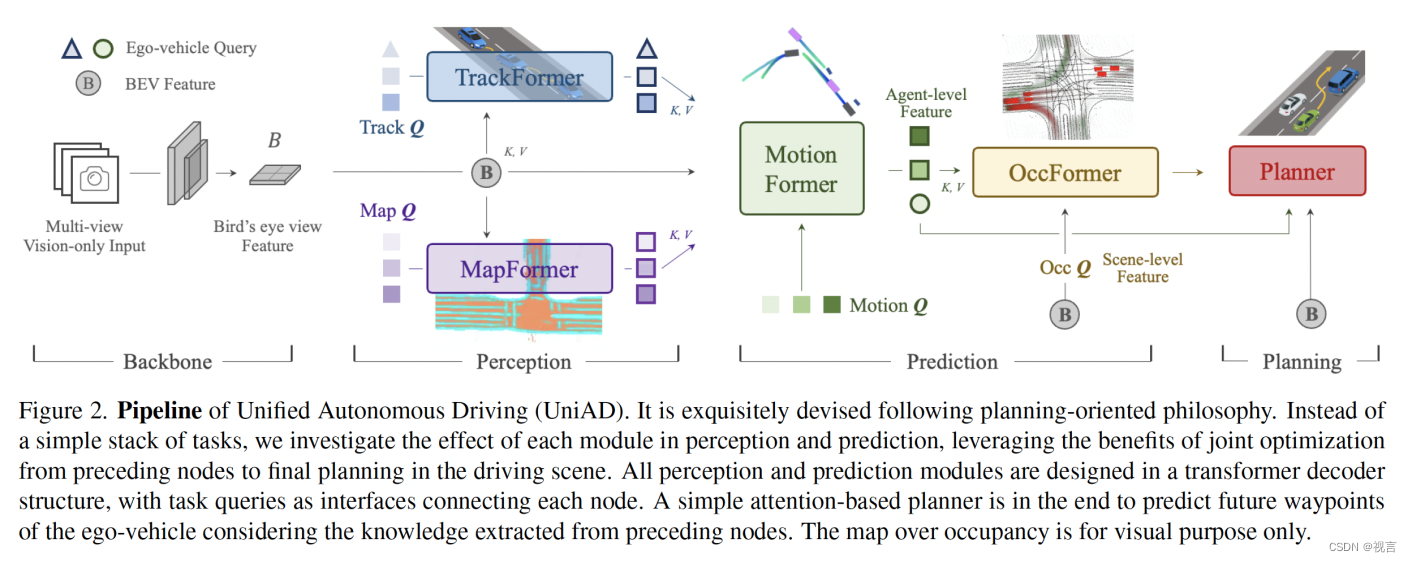
UniAD 包括四个基于 Transformer 解码器的感知Perception和预测Prediction模块,最后还有一个规划器Planer。Queries Q 扮演连接pipeline的角色,以模拟驾驶场景中实体的不同交互。
In backbone : 将一系列多相机图像输入特征提取器,并将生成的perspective-view特征通过 BEVFormer 中的现成 BEV 编码器转换为统一鸟瞰图 (BEV) 特征 B。 请注意,UniAD 并不局限于特定的 BEV 编码器,并且可以利用其他替代方案通过长期时间融合 或多模态融合 来提取更丰富的 BEV 表示。
In perception: 在 TrackFormer 中,我们称为track queries的可学习嵌入, 用来查询(inquire)来自 B 的agents信息以检测和跟踪agents。MapFormer 将map queries作为道路元素(例如,车道和分隔线)的语义抽象(semantic abstractions),并对地图进行全景分割。
In prediction: 通过上述代表agents和map的queries,MotionFormer 捕获agents和map之间的交互并预测每个agent的未来轨迹。 由于每个agent的动作都会显著影响场景中的其他agents,因此该模块对所有考虑的agents进行联合预测。 同时,设计了一个ego-vehicle query来明确地对ego-vehicle进行建模,并使其能够在这种以场景为中心(scene-centric)的范式中与其他agents进行交互。OccFormer 使用 BEV 特征 B 作为queries,配备agent-wise knowledge知识作为keys和values,并在保留agent identity的情况下预测多步未来占用(multi-step future occupancy)。
in planning: Planner 利用来自 MotionFormer 的expressive ego-vehicle query来预测规划结果,并使自己远离 OccFormer 预测的占用区域(occupied regions)以避免碰撞。
perception: trackformer
它联合执行检测和多目标跟踪 (MOT),而无需进行不可微分的后处理。 受 [MOTR, MUTR3D] 的启发,文章采用了类似的query设计。 除了对象检测中使用的常规detection queries 之外,还引入了额外的track queries来跨帧跟踪agent。 具体来说,在每个时间步,初始化的detection queries负责检测第一次被感知的newborn agents,而track queries则对在先前帧中检测到的agents保持建模。 Detection queries和track queries都通过关注(attending) BEV 特征 B 来捕获agent abstractions。 随着场景的不断演化,当前帧的track queries与先前记录的track queries在自注意力模块中交互, 以聚合temporal信息,直到相应的agents完全消失(在特定时间段内未被跟踪)。 与 [DETR] 类似,TrackFormer 包含 N 层,最终输出状态
Q
A
Q_A
QA 为下游预测任务提供
N
a
N_a
Na 个有效agents的知识(knowledge)。 除了编码ego-vehicle周围其他agents的query外,我们在query set中引入了一个特定的ego-vehicle query,以明确地对自动驾驶车辆本身进行建模,并将其进一步用于规划。
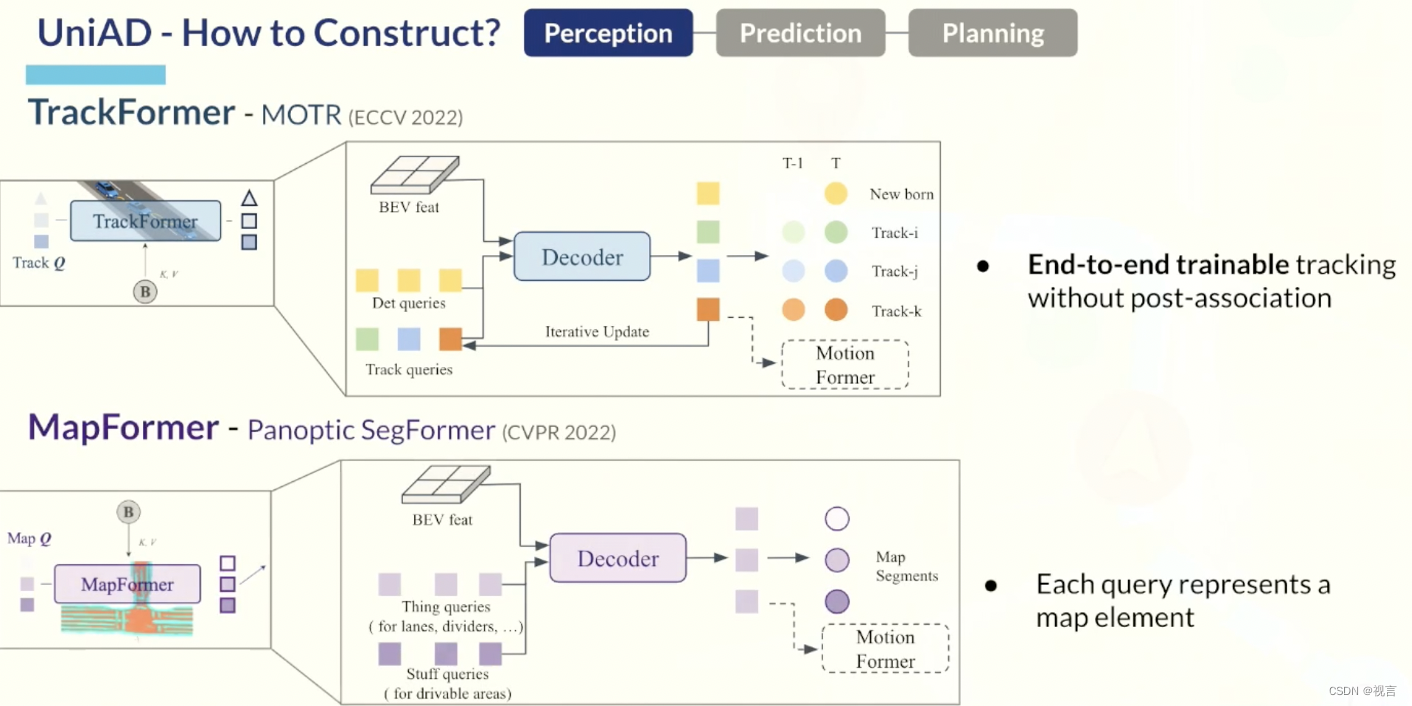
perception: mapformer
我们基于 2D 全景分割方法 Panoptic SegFormer 设计它。 我们将道路元素稀疏地表示为map queries,以帮助下游运动预测,并对位置和结构知识进行编码。 对于驾驶场景,我们将车道、分隔线和十字路口设置为things,将可行驶区域设置为stuff 。 Map Former 也有 N 个堆叠层,每层的输出结果都是有监督的,而只有最后一层更新的queries Q M Q_M QM 被转发给 MotionFormer 进行agent-map交互。
Prediction: Motion Forecasting
通过分别从 TrackFormer 和 MapFormer 对dynamic agents Q A Q_A QA 和static map Q M Q_M QM 进行高度abstract queries,MotionFormer 以场景为中心的方式预测所有agents的多模态未来运动,即前 k 个可能轨迹。 这种范式通过一次前向传播在帧中产生multi-agent轨迹,这大大节省了将整个场景与每个agent的坐标对齐的计算成本。 同时,考虑到未来动态,来自 TrackFormer 的ego-vehicle query经过 MotionFormer 传递,让ego-vehicle与其他agents进行交互。 形式上,输出运动被表述为 X ^ i , k ∈ R T × 2 ∣ i = 1.... , N a ; k = 1 , . . . . , K {\hat{X}_{i,k}∈R^{T \times 2} | i=1....,N_a; k=1,....,K} X^i,k∈RT×2∣i=1....,Na;k=1,....,K,其中 i 索引agent,k 索引轨迹的模态,T 是预测范围的长度。
MotionFormer它由 N 层组成,每层捕获三种类型的交互:agent-agent、agent-map 和 agent-goal point。 对于每个motion query Q_{ik},其与其他agents
Q
A
Q_A
QA 或地图元素
Q
M
Q_M
QM 之间的交互可以表示为:
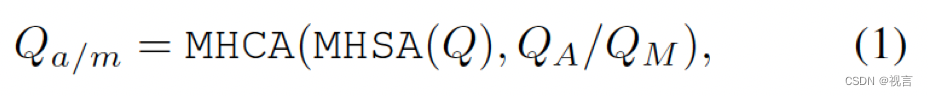
MHCA, MHSA denote multi-head cross-attention and multi-head self-attention.
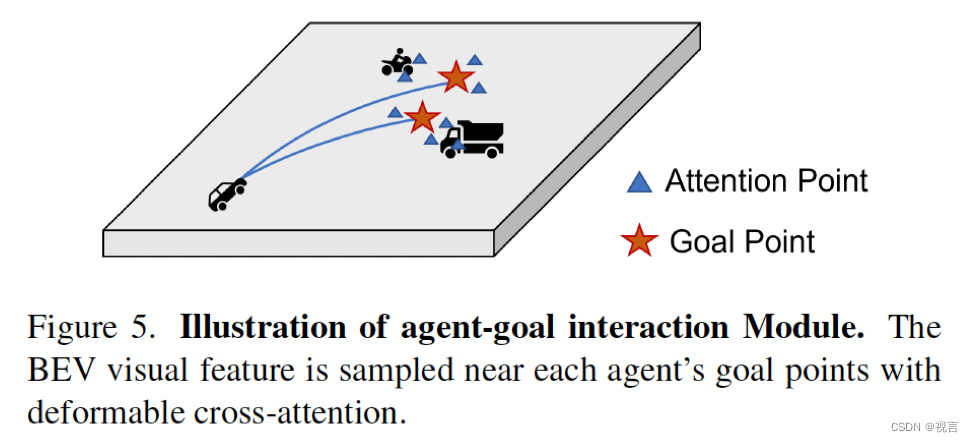
由于关注intended posiiton(即目标点)以细化预测轨迹也很重要,因此我们通过deformable attention设计了agent-goal point注意力,如下所示:
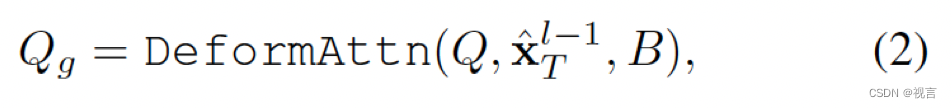
x
^
T
l
−
1
\hat{x}_T^{l−1}
x^Tl−1是上一层预测轨迹的终点。
DeformAttn(q,r,x), 一个稀疏attention模块, 输入query q, reference point r 以及 spatial feature x. DeformAttn对参考点周围的空间特征进行稀疏attention。通过这个,预测的轨迹因为对端点周围环境的了解被进一步refine 。
所有三种交互都是并行建模的,其中生成的
Q
a
Q_a
Qa、
Q
m
Q_m
Qm 和
Q
g
Q_g
Qg 被连接起来并传递给多层感知器 (MLP),生成query context
Q
c
t
x
Q_{ctx}
Qctx。 然后,
Q
c
t
x
Q_{ctx}
Qctx被发送到后续层进行refine或解码作为最后一层的预测结果。
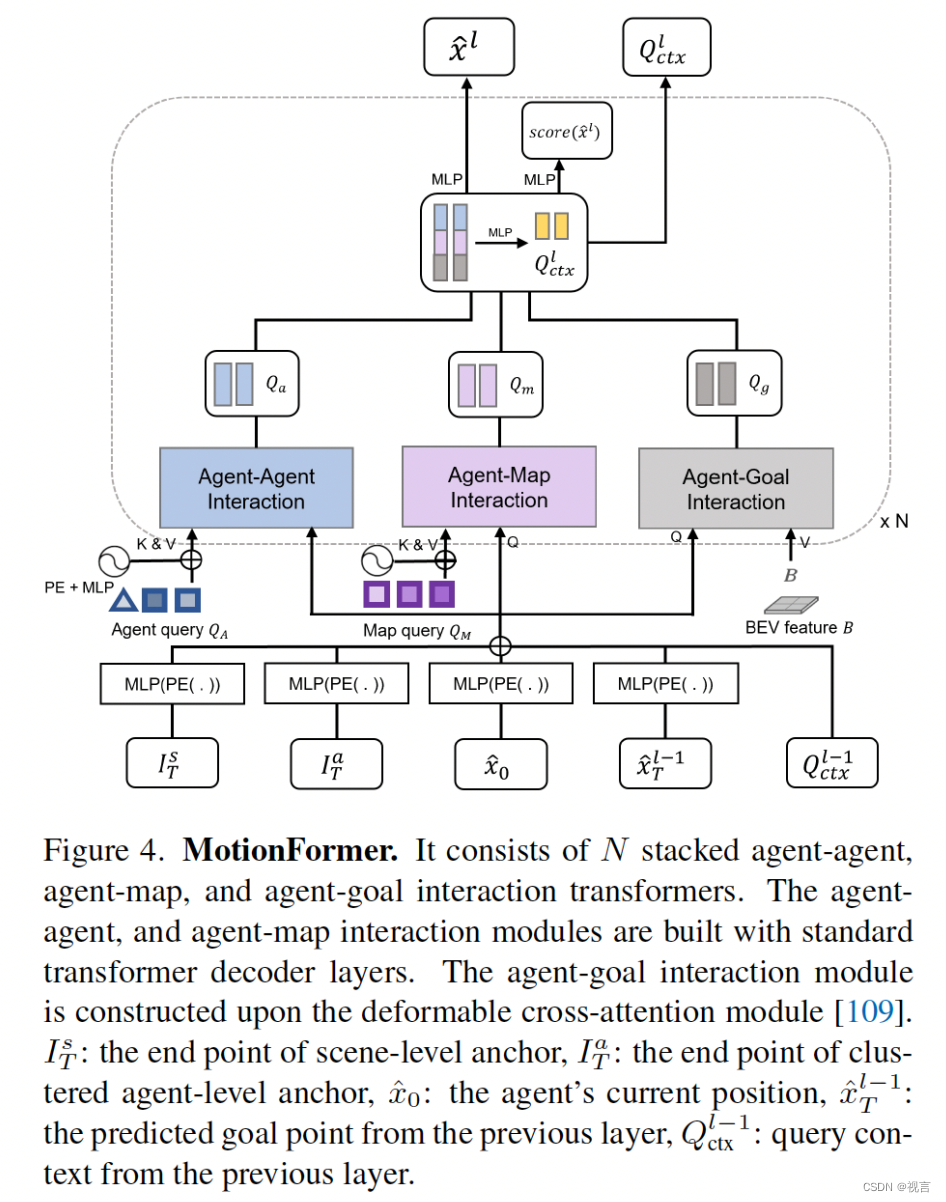
agent-agent、agent-map交互module都是构建在标准transformer decoder之上,而agent-goal构建在deformable cross-attention module之上,前面预测的轨迹的goal point作为参考点,每个参考点周围4个采样点,每个agent 6个轨迹(模态)。
用高斯混合模型构建每个agent的轨迹,即
x
^
l
∈
R
6
×
T
×
5
\hat{x}_l \in R^{6 \times T \times 5}
x^l∈R6×T×5. 最后一个维度的前两维为最终输出轨迹点;每个轨迹预测一个分数。
Motion queries:motionformer每一层的input queries就是motion queries,由上一层的query context
Q
c
t
x
Q_{ctx}
Qctx,以及query position
Q
p
o
s
Q_{pos}
Qpos组成。
Q
p
o
s
Q_{pos}
Qpos集成了四重位置知识,包括:
1.scene-level anchors
I
s
I^s
Is(prior movement statistics in a global view) ,
2.agent-level anchors
I
a
I^a
Ia(captures the possible intention in the local coordinate),
3.current location of agent i (provides customized positional embedding for each agent),
4.predict goal point(serves as a dynamic anchor optimized layer-by-layer in a coarse-to-fine fashion)
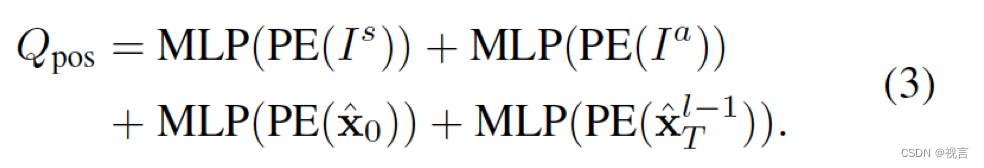
紧接着MLP的正弦位置编码PE(.)是用来编码位置点的,
x
^
T
0
\hat{x}_{T}^0
x^T0设为第一层的
I
s
I^s
Is(ik忽略). scene-level anchor表示全局视角下的先验移动统计,agent-level anchor捕捉局部坐标下的潜在意图。他们都在ground-truth轨迹端点上通过k-means聚类来缩小预测的不确定度。和先验知识相反,起始点为每一个agent提供了自定义的位置嵌入,预测的终点充当由粗到精逐层优化的动态anchor。
Non-linear Optimization: 和经典的motion forecast方法直接访问真值感知结果(即agents的位置与对应的track)不同,我们考虑在我们的端到端范式下上一个模块的预测不确定度。从一个不准确的检测位置或航向角暴力回归真值路径点会导致大曲率大加速度的不真实轨迹预测。为了克服这个问题,我们采用一个non-linear smoother调整目标轨迹,使得他们在给定上游模块预测的不精确起点时物理可行。过程是:
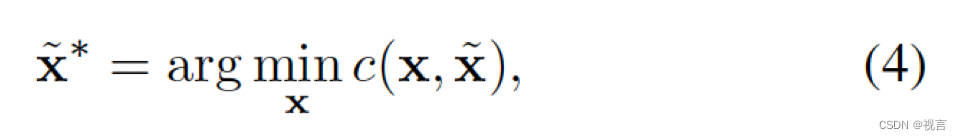
where
x
^
\hat{x}
x^ and
x
^
∗
\hat{x}^∗
x^∗ denote the ground-truth and smoothed trajectory,
x
x
x is generated by multiple-shooting , 代价函数如下:
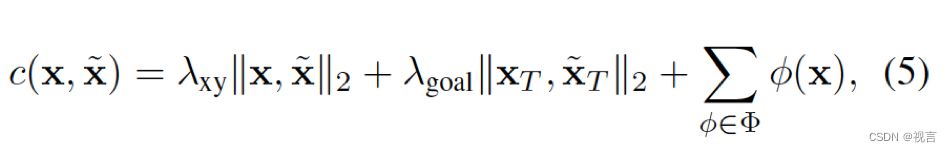
运动学函数集 Φ有五项,包括加加速度,曲率,曲率速率,加速度和横向加速度。代价函数正则化目标轨迹以服从运动学 约束。此目标轨迹优化仅在训练中 进行,不影响推理。
Prediction: Occupancy Prediction
Occupancy grid map是离散化的bev表示,每个cell表示是否被占据的belif, occupancy prediction任务预测occupancy未来变化。
以前的方法为从观察到的BEV特征时间扩展未来预测利用RNN结构,然而,它们依赖于高度手工制作的聚类后处理 来生成每个代理的占用图,因为它们 主要是通过将BEV特征作为 整体压缩到RNN隐藏状态而与代理无关。由于智能体知识的使用不足 ,对他们来说, 预测全局所有智能体的行为是一项挑战,这对于理解场景如何演变至关重要 。为了解决这个问题,我们提出OccFormer在两个方面结合场景级和代理级语义:(1)密集场景特征通过精心设计的 注意力模块在展开到未来视野时获得代理级特征; (2)我们通过代理级特征和密集场景特征之间的矩阵乘法轻松地产生实例占用,而无需进行繁重的后处理。
occformer由
T
o
T_o
To个序列块组成,
T
o
T_o
To表示预测视野, 由于密集表示的occupancy计算代价很高:
T
o
(
5
)
<
T
(
12
)
T_o(5) < T(12)
To(5)<T(12)。每个序列块输入丰富的agent特征
G
t
G^t
Gt和来自早先层状态(密集特征)
F
t
−
1
F_{t-1}
Ft−1,考虑instance- 和scene-level信息生成
F
t
F_{t}
Ft。为了获得带有动态和空间先验的agent特征
G
t
G_t
Gt,在模态维度max-pool motion queries
Q
X
∈
R
N
a
×
D
Q_X \in R^{N_a \times D}
QX∈RNa×D. 然后通过一个时间特定MLP融合上游track query
Q
A
Q_A
QA和当前位置嵌入
P
A
P_A
PA:
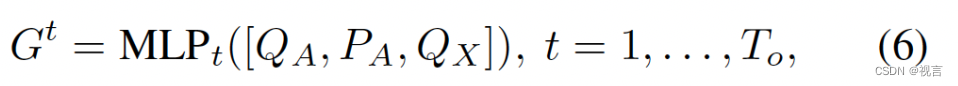
其中[.]表示concatenation。对于场景级特征,为了训练效率。BEV特征B下采样1/4 作为第一个block输入
F
0
F^0
F0。为了进一步节省内存,每个block follow一个下采样-上采样方式在1/8下采样特征上构建pixel-agent交互
F
d
s
t
F^t_{ds}
Fdst。
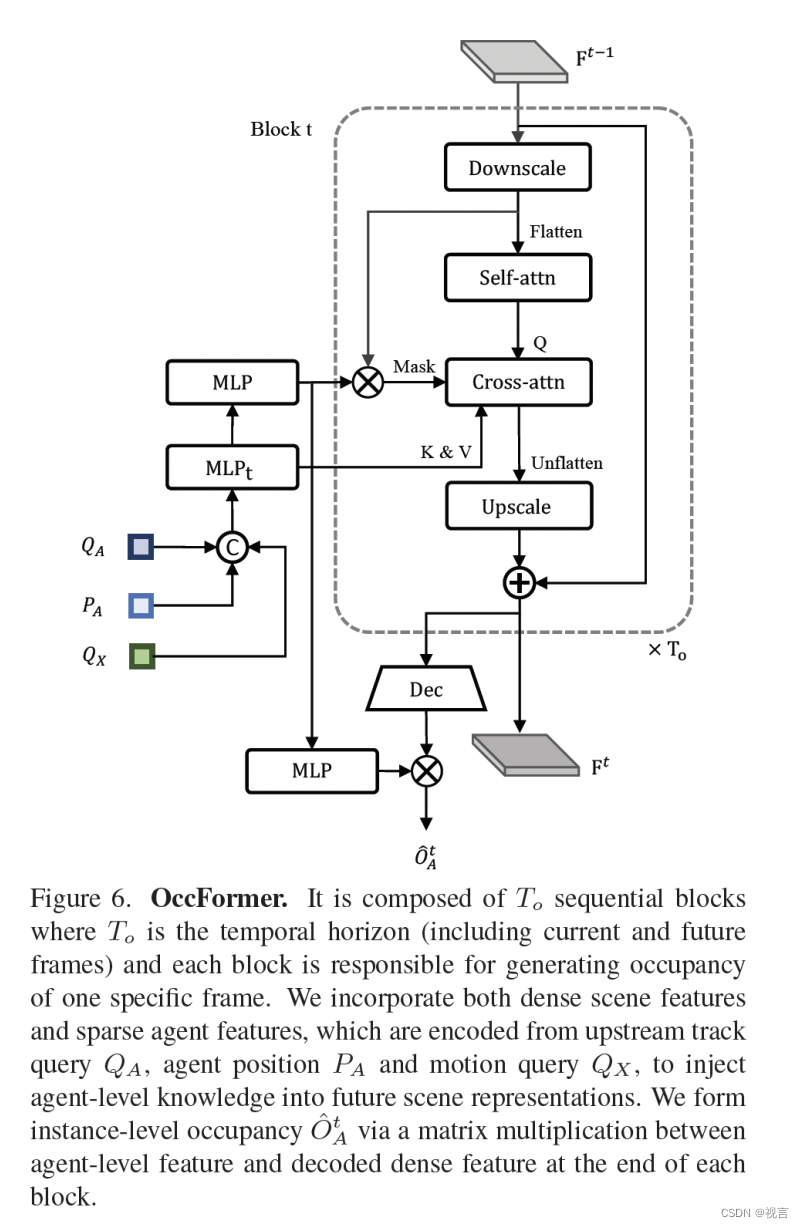
Pixel-agent interaction的设计目的是在预测未来占用时统一场景和代理级理解。密集特征
F
d
s
t
F^t_{ds}
Fdst作为查询,实例级特征作为key、value在时间上更新dense feature。为了对齐pixel-agent一致性,通过一个attention mask限制cross-attention,每个像素只看时刻
t
t
t占用的agent,dense特征更新过程如下:
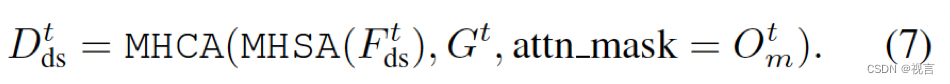
attention mask
Q
m
t
Q^t_m
Qmt 语义类似于occupancy,由mask feature
M
t
(
M
t
=
M
L
P
(
G
t
)
)
M^t (M^t = MLP(G^t))
Mt(Mt=MLP(Gt))和dense feature
F
d
s
t
F^t_{ds}
Fdst乘出来得到。
scene-level features
F
t
F^t
Ft通过卷积解码上采样到原bev特征大小得
F
d
e
c
t
F^t_{dec}
Fdect。对于agent-level 特征,进一步通过一个MLP更新粗糙的mask feature
M
t
M^t
Mt到occupancy feature
U
t
U^t
Ut。最终t时刻的instance-level occupancy为:
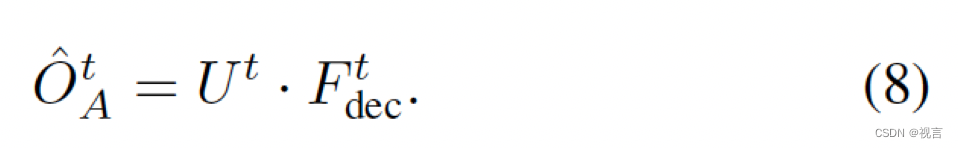
planning
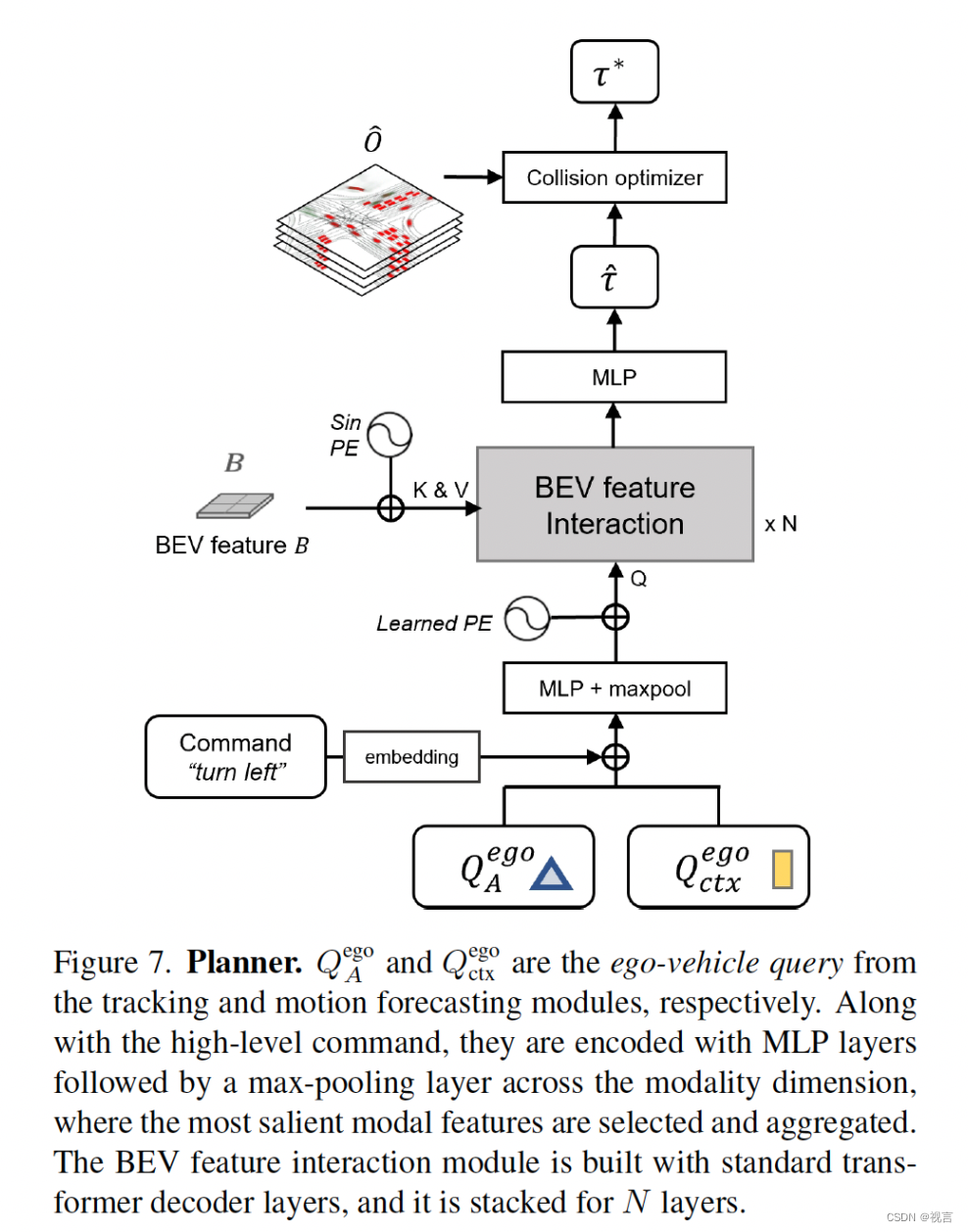
没有HD map和 redefined routes的planning需要指示方向的高级命令,将原始导航信号(左转、右转、执行)转成可学习command embeddings。motionformer出来的自车query已经表达了多模态意图,我们再配上command embeddings来形成plan query。将plan query attend to bev features B使得其意识到周围环境,再将其解码为未来的路径点
τ
^
\hat{τ}
τ^.
where
τ
^
∈
R
T
p
×
2
,
(
T
p
=
6
,
3
s
)
\hat{τ} \in R^{T_p \times 2}, (T_p=6, 3s)
τ^∈RTp×2,(Tp=6,3s).
为了进一步避免碰撞,我们在推理阶段基于牛顿法优化
τ
^
\hat{τ}
τ^:
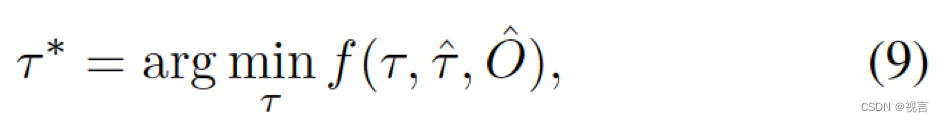
τ
∗
τ^*
τ∗是最优planning,是从multiple-shooting轨迹τ中最小化代价函数
f
(
.
)
f(.)
f(.)选出来的。
O
^
\hat{O}
O^是一个从occformer获得的实例occupancy预测合并来的经典二值occupancy map,
f
f
f的计算如下:
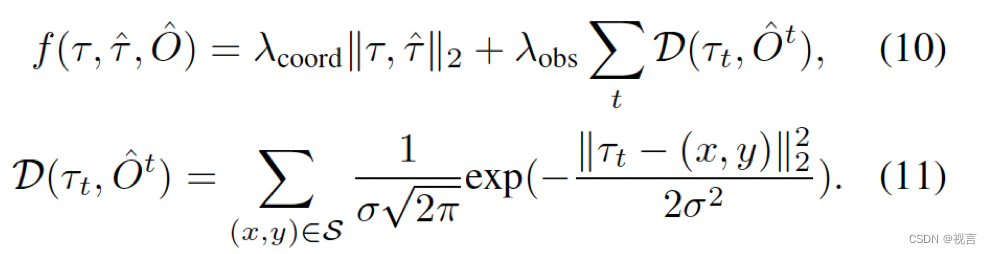
其中
S
=
(
x
,
y
)
∣
∥
(
x
,
y
)
−
τ
t
∥
2
<
d
,
O
^
x
,
y
t
=
1
S = {(x, y)| \ ∥(x, y)−τ_t∥_2 <d, \hat{O}^t_{x,y} = 1}
S=(x,y)∣ ∥(x,y)−τt∥2<d,O^x,yt=1. D将预测轨迹拉远occupied grids,L2将轨迹拉向原始预测的轨迹。
learning
训练分两个阶段:
1.联合训练感知部分,即tracking和mapping模块, 6epoch
2.端到端 train 20 epoch
Detection&tracking loss:focal loss+L1
Online mapping loss:focal loss+L1+Dice loss +GIoU loss
Motion forecasting loss:multi-path loss(classification score loss L_cls + a negative log-likelihood loss)
Occupancy prediction loss: binary cross-entropy and Dice loss
Planning loss: naive imitation l2 loss + collision loss
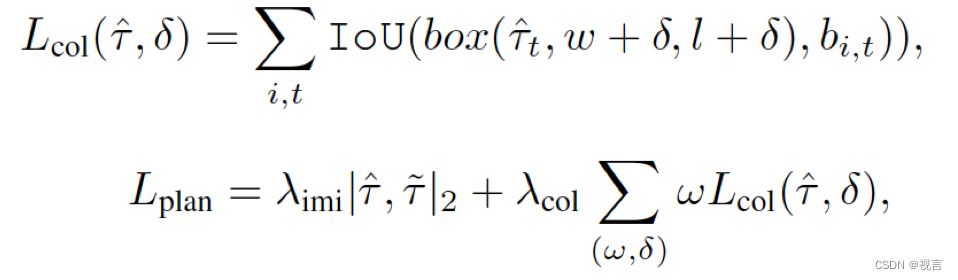
b
o
x
(
.
)
box(.)
box(.)是加了扰动的自车bounding box。
shared matching:tracking和mapping模块采用bipartite matching算法;track中,检测新诞生查询候选和真值配对,track queries的预测继承上一帧的分配。match结果复用到motion和occupancy结点以从历史tracks到未来motions一致性建模agents。
Experiments
实验主要在三方面:揭示任务协调优势及其对规划影响的联合结果, 各任务的模块化结果与以往方法的比较, 对特定模块设计空间的消融实验。
Joint Results
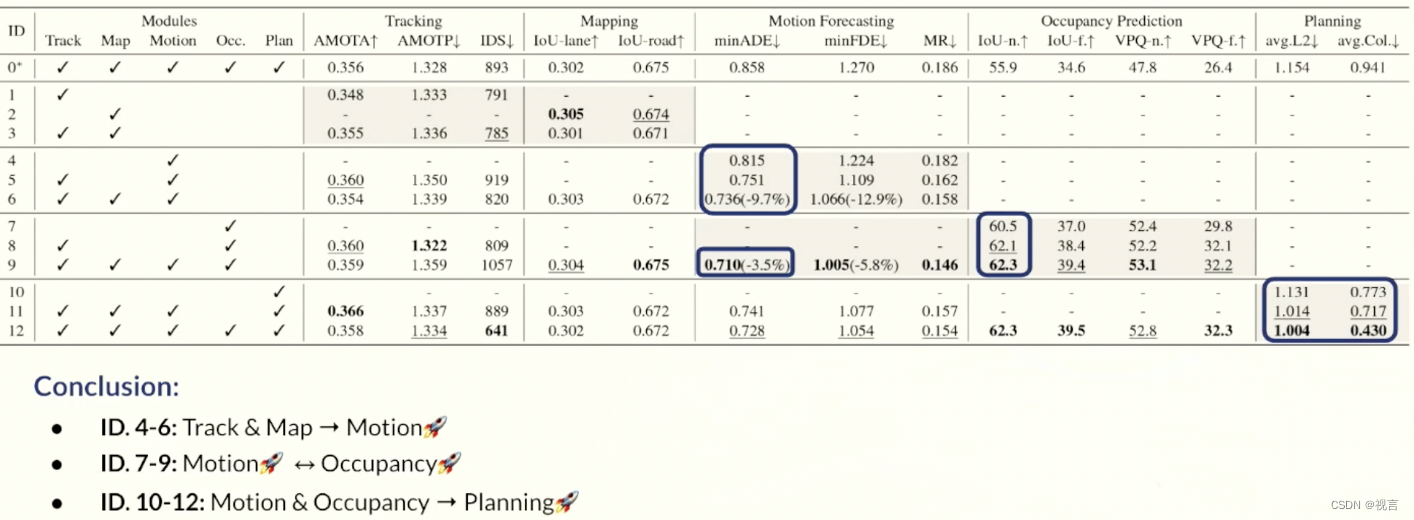
“avg.L2”和“avg.Col”是整个planning范围的平均值。ID
0
∗
0^*
0∗ 是 MTL 方案,每个任务都有单独的head。
每个指标的最佳结果以粗体标记,次优结果在每列中带有下划线。
在Exp.1-3,表明同时训练感知子任务会得到与单个任务相差不大的结果。
在Exp.4-6,探索了感知模块能做出多少贡献。
在Exp.7-9,展示了两种预测的协同效应。
只有同时引入两个任务 (ID.12) 时,planning的 L2 和碰撞率指标才能都获得最佳结果。因此,作者得出结论,这两个预测任务都是安全规划目标所必需的。
Modular Results
感知结果
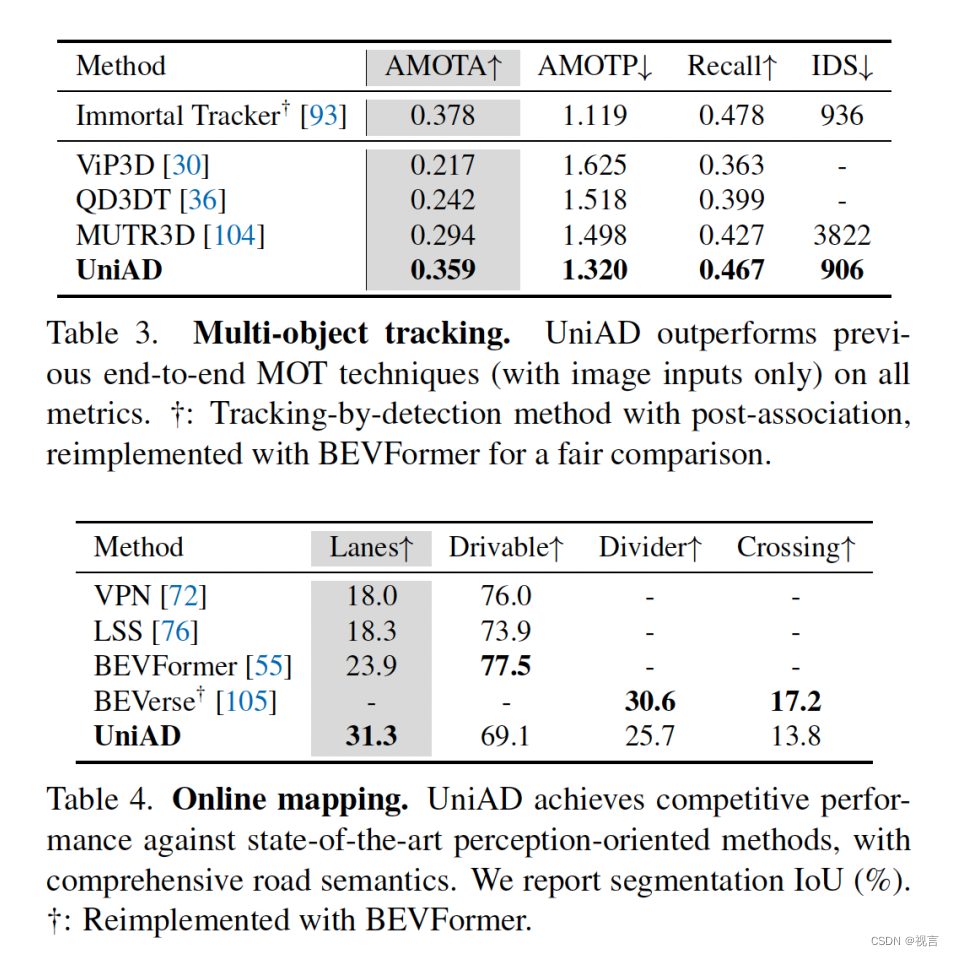
track比Immortal Tracker差点,map特定类差点;
预测结果
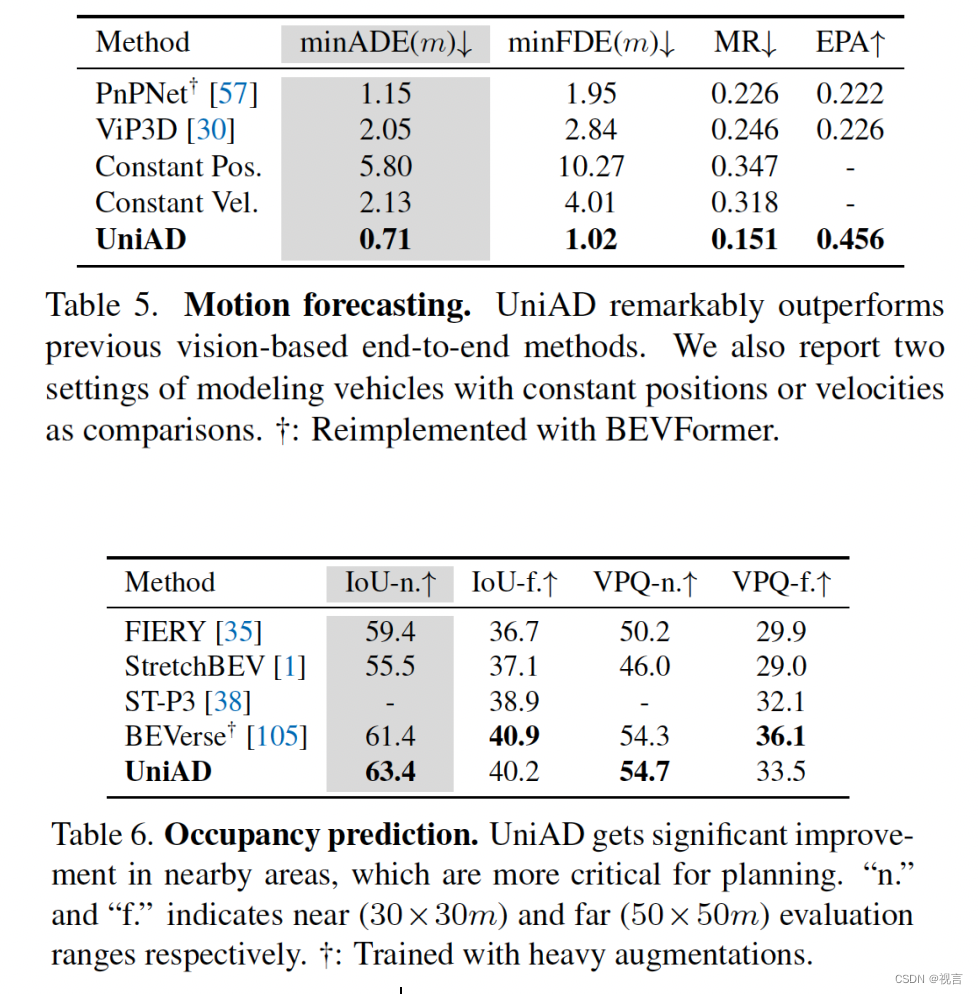
显著提高
规划结果
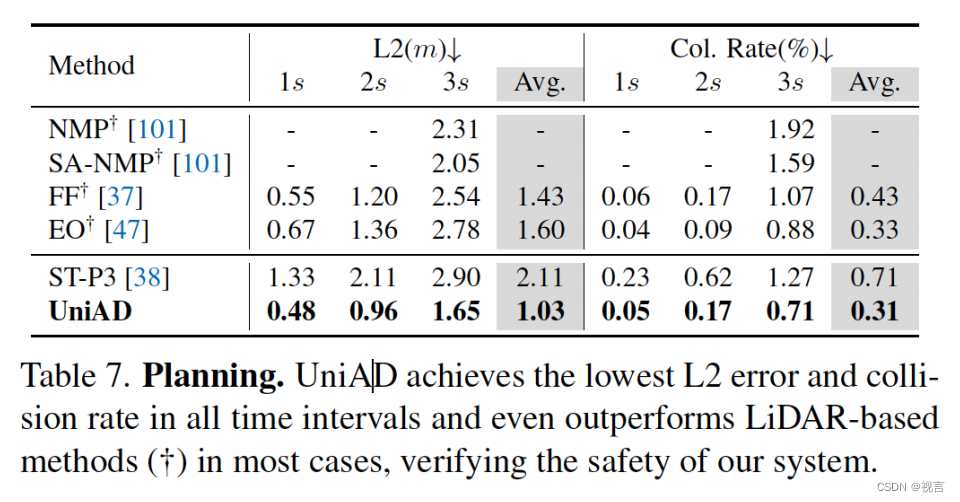
超过lidar-based方法
Ablation Study
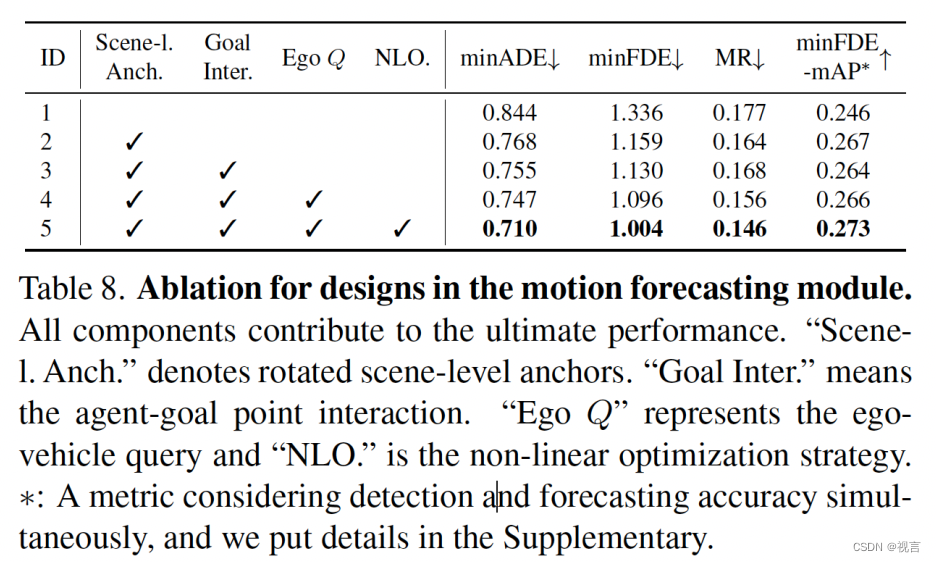
MotionFormer设计的影响:
OccFormer设计影响:

planner设计影响:
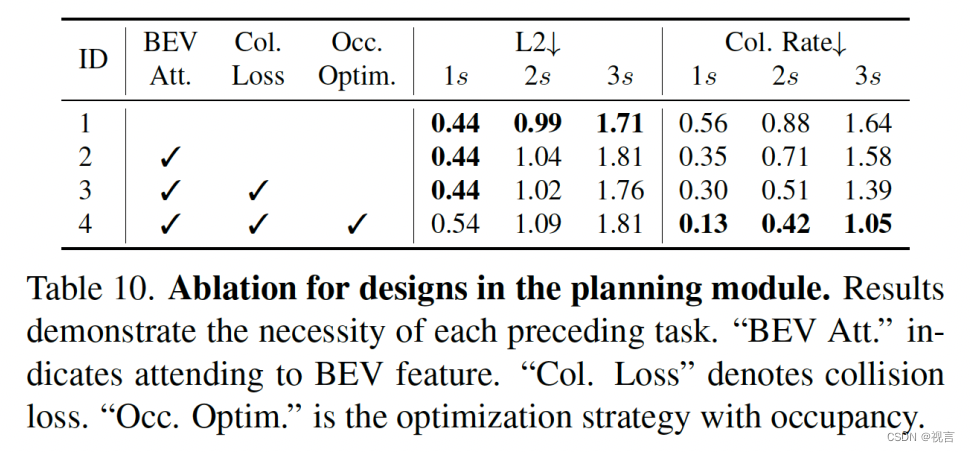
Qualitative Results
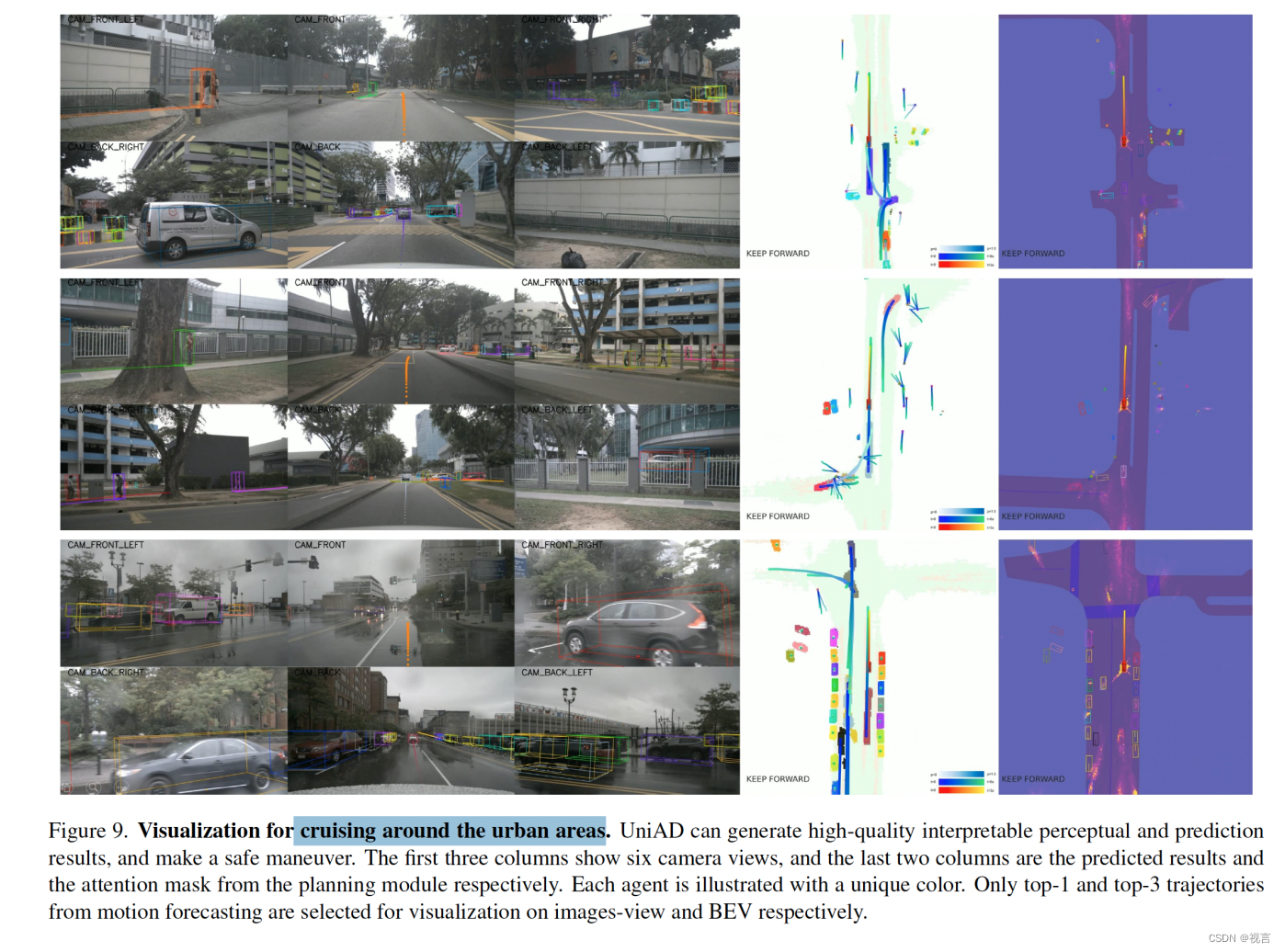
市区巡航场景:
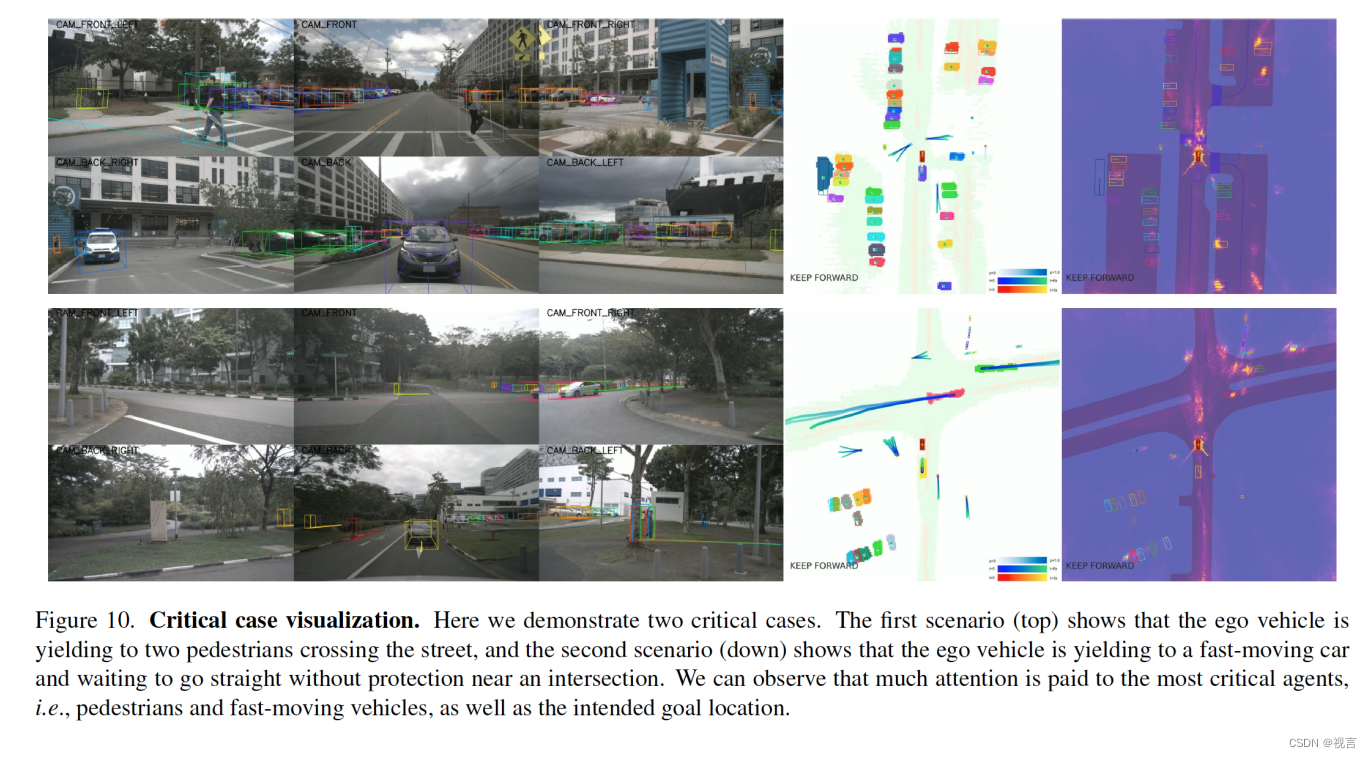
临界情况:
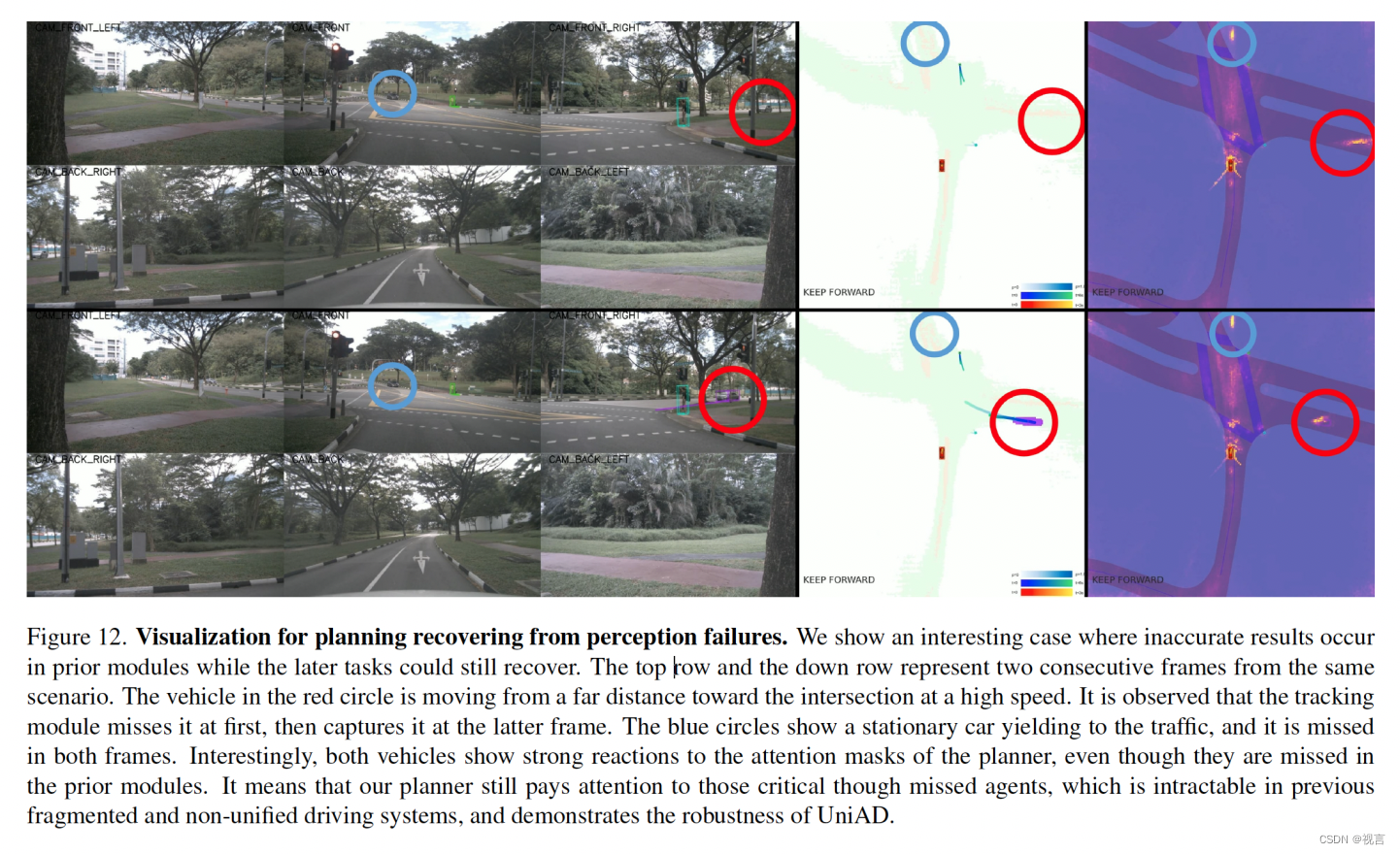
避障场景:

展示plan-oriented潜力:
Badcase:

Conclusion
planning-oriented pipeline设计;详细的子模块必要性分析;query-based设计连接各节点并促进环境中agent交互。
缺陷:
1.太耗计算资源和显存
2.如何轻量化开发有待研究
3.如何嵌入更多任务,例如depth估计、行为预测等。
4.需要实时加入导航信息
5.没有考虑红绿灯信息、交通标志、地面标识等
future展望


application demos
国内场景演示
拥堵路段跟车:

弯曲道路结构规划:

附录


















 9198
9198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









