






 本文讲述了通过Python实现对英文和中文文本文件的词频统计,包括单词抽取、频次计算和前10个高频词的输出。实验内容涉及列表、字典、循环结构以及jieba库在中文处理中的应用,旨在提升学生的编程技能和文本处理理解。
本文讲述了通过Python实现对英文和中文文本文件的词频统计,包括单词抽取、频次计算和前10个高频词的输出。实验内容涉及列表、字典、循环结构以及jieba库在中文处理中的应用,旨在提升学生的编程技能和文本处理理解。
一、实验综述
1、实验目的及要求
实验目的:
通过该实验,使学生掌握列表、字典、函数的使用方式,能够熟练运用for循环语句、while循环语句和if判断语句来进行词语处理,实现英文或中文单词分解,并掌握格式化输出的相关方法。
实验要求1(和实验2,二选一):
1、实现对英文文本文件的读取(moby_dick.txt);
2、实现对英文文本文件的单词抽取;
3、实现对英文文本文件中出现频次最高的前10个单词的抽取,并降序输出(包含频次);
4、(选做)实现对英文文本文件中出现频次最高的前10个名词的抽取,并降序输出(需要对单词进行筛选);
实验要求2:
1、实现对中文文本文件的读取(三国演义.txt);
2、实现对中文文本文件的单词抽取;
3、实现对中文文本文件中出现频次最高的前10个词语的抽取,并降序输出(包含频次);
4、(选做)实现对中文文本文件中出现频次最高的前10个人物的抽取,并降序输出;(提示:该实验需要安装jieba库, 安装命令: pip install -U jieba --user)
请独立完成该实验。
实验报告写作要点:
写出整个实验的的基本步骤,辅以相应文字说明,并提交相应的源代码.py文件。将创建的程序运行结果截图,分析讨论实验过程中的心得与体会。
2、实验仪器、设备或软件
笔记本电脑,Pycharm
二、实验过程(实验步骤、记录、数据、分析)
实验要求1
(一)实现对英文文本文件的读取(moby_dick.txt);
1.打开文件,读取文本内容,放入文件的地址(在字符串前加上R表示该字符串是非转义的原始字符串)

2. 将字母全部转化为小写,去掉特殊的符号
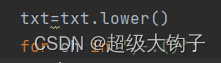
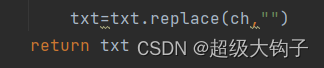
3.把特殊符号替换为空格,便于后序操作:
(二)实现对中文文本文件的单词抽取;
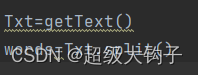
4.读取修改后的文件,split()函数,对字符串进行切片,并返回分割后的字符串列表
5.创建并遍历字典中的单词:
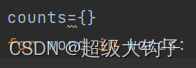
6.统计单词出现的频次:
![]()
(三)实现对英文文本文件中出现频次最高的前10个单词的抽取,并降序输出(包含频次):
7.对返回的列表排序:

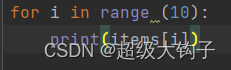
8. 对英文文本文件中出现频次最高的前10个单词的抽取,并降序输出:
代码内容:
def getText():
txt=open(R'C:\Users\85415\Desktop\1005404853-002\moby_dick.txt').read()
txt=txt.lower()
for ch in ',-.()':
txt=txt.replace(ch,"")
return txt
Txt=getText()
words=Txt.split()
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range (10):
print(items[i])
三、结论
1.实验结果
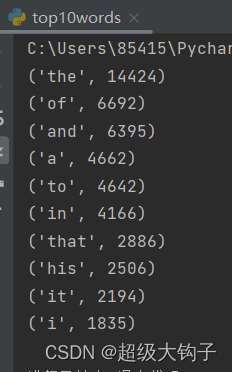
2.分析与讨论:
本次实验实现了词频统计功能。对英文文本文件进行读取,使用了列表,字典等的容器,for循环,replace函数,split函数对文本进行分解抽取,对英文单词进行分解,统计单词出现的频次,最后排序并格式化输出前10个单词。
通过本次实验,我对文本文件的处理有了更深刻的认识,深化了对字典,列表等容器的理解。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









