





1 模型:AI 应用的核心
在深入探讨 LangChain 的组件之前,我们先来理解一下大语言模型(LLM)的基础知识。
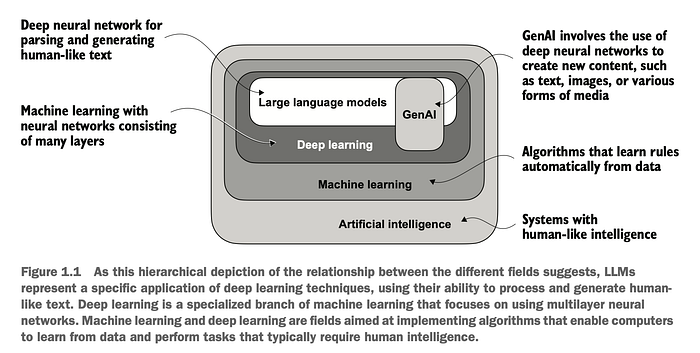
1.1 从 AI 到生成式 AI
为了更好地理解 LLM 的定位,我们先退一步看看更广阔的 AI 领域。
- 人工智能 (AI):构建能够执行智能(如感知、推理和决策)任务的系统的广阔领域。
- 机器学习 (ML):AI 的一个子领域,专注于创建从数据中学习的算法。
- 深度学习 (DL):ML 的一个分支,使用多层神经网络从原始数据中自动学习模式。
- 生成式 AI:一种 AI 形式(通常基于深度学习),用于创建内容——如文本、图像或音频。LLM 就是其典型代表。
1.1.1 什么是大语言模型 (LLM)?
大语言模型 (LLM) 是一种经过训练的深度神经网络,用于理解、生成和响应类人文本。这些模型通常在包含大量公共互联网数据的海量数据集上进行训练,使用一个简单而强大的目标:预测序列中的下一个词。
LLM 中的“大”体现在两个方面:
- 训练数据量巨大,通常达到数万亿个词元(token,即单词和子词)。
- 参数数量庞大——模型的内部权重——范围从数十亿到数千亿不等。
尽管训练任务只是简单的下一个词预测,但 LLM 在摘要、代码生成、翻译和开放式对话等任务中展现出了非凡的能力。
1.1.2 背后的架构:Transformer
现代 LLM 建立在 Transformer 架构之上,该架构在 2017 年的里程碑式论文《Attention Is All You Need》中提出。Transformer 的核心创新是注意力机制,它允许模型在做出预测时有选择地关注输入的相关部分。
这种架构使得在更多数据上训练更大的模型成为可能,同时比 RNN 或 LSTM 等先前方法能更好地捕捉语言的细微差别和结构。
现在我们对 AI、机器学习、深度学习和生成式 AI 之间的区别有了更清晰的认识,接下来让我们进入 LangChain 的第一个核心组件。
1.2 语言模型
广义上讲,LangChain 中的模型分为两类:语言模型(Language Models)和嵌入模型(Embedding Models)。
LangChain 同时支持闭源模型(如 OpenAI 的 GPT-4 或 Anthropic 的 Claude)和开源替代方案(如 LLaMA、Mistral、Hugging Face 和 Falcon),允许你根据应用需求和基础设施选择最合适的工具。
语言模型可以进一步分为两种类型:LLM(大语言模型)和聊天模型(Chat Models)。
此时,你可能会疑惑——LLM 和聊天模型不是一回事吗?这是个常见问题,虽然它们密切相关,但在结构和用法上存在关键差异。
1.2.1 LLM 与 聊天模型
- LLM (传统文本补全模型):它们是用于原始文本生成的通用模型。LangChain 中的 LLM 遵循简单的“文本输入,文本输出”接口。它们设计用于传统的补全式交互:你提供一个提示(prompt),模型返回一个文本响应。
from langchain.llms import OpenAI
llm = OpenAI()
response = llm.predict("The capital of France is")
# Output: "Paris, which is located in the north-central part of the country..."
-
聊天模型 (面向对话的模型):这些模型专门为多轮对话进行了微调。它们不仅仅接收一个文本提示,而是期望一个消息列表,每条消息通常带有“用户”、“助手”和“系统”等角色。
这使得它们非常适合:
- 构建交互式聊天机器人。
- 客户支持自动化。
- 任何需要来回对话的应用。
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="What's the capital of France?")
]
response = chat.predict_messages(messages)
# Output: AIMessage object with content and metadata
在 LangChain 中,两者都被视为“模型”,但它们的接口可能略有不同,主要区别在于你如何构建输入。
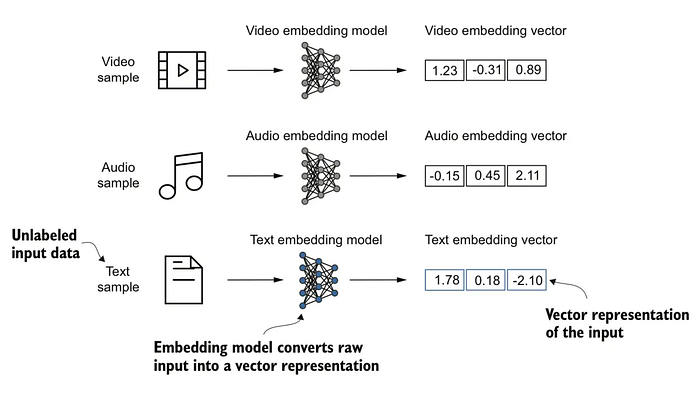
1.2.2 嵌入模型
嵌入模型是一种机器学习模型,它将数据(如文本、图像或音频)转换为一种紧凑的数值格式,称为嵌入(embeddings)。这些嵌入是向量(即数字列表),在一个连续的低维空间中捕获输入数据的语义含义或上下文。
这使得机器可以基于语义(而不仅仅是精确的单词或数值)来比较、搜索、聚类或分类信息变得容易得多。
想象一下用数字而不是文字来描述水果:
- 苹果 → [8, 5, 7] (甜度、大小、颜色)
- 香蕉 → [9, 7, 4]
- 柠檬 → [3, 5, 9]
这些数值向量可以轻松看出哪些水果相似,即使它们的名称或描述不同。
1.2.3 与各种 LLM 提供商的接口
LangChain 被设计成模型无关的(model-agnostic),这意味着它开箱即用地支持广泛的闭源和开源语言模型。
这使得在 OpenAI、Anthropic、Google 的 Gemini,甚至通过 Hugging Face 托管的开源模型或像 Ollama 这样的本地服务器之间切换变得非常容易——所有这些都通过统一的接口实现。
使用 Google Gemini
from langchain.chat_models import ChatGoogleGenerativeAI
model = ChatGoogleGenerativeAI(model="gemini-2.0-flash")
response = model.invoke("Write a short haiku about the moon.")
print(response.content)
切换到 OpenAI GPT-4
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model='gpt-4', temperature=1.5, max_completion_tokens=10)
result = model.invoke("Write a 5 line poem on cricket")
print(result.content)
使用 Anthropic Claude
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model='claude-3-5-sonnet-20241022')
result = model.invoke('What is the capit 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











