










Hydra Attention学习笔记
Hydra Attention:Efficient Attention with Many Heads
Abstract
虽然transformers已经开始在视觉领域的许多任务中占据主导地位,但将它们应用于大型图像在计算上仍然很困难。一个很大的原因是,自我注意力随标记的数量成二次增长,而标记的数量又随图像的大小成二次增长。对于较大的图像(例如,1080p),网络中超过60%的计算都花在创建和应用注意矩阵上。我们通过引入Hydra Attention向解决这个问题迈出了一步,它是视觉transformers(ViTs)的一种非常高效的注意操作。矛盾的是,这种效率来自于将多头注意力发挥到极致:通过使用与特征一样多的注意头,Hydra注意力在标记和特征上都是计算线性的,没有隐藏的常数,这使得它在现有的vitb /16中明显比标准的自我注意快了一个标记计数的因子。此外,Hydra Attention在ImageNet上保持了很高的准确性,在某些情况下,实际上还提高了它。
关键词:Vision Transformers, Attention, Token Efficiency
1 Introduction
由于transformers[32]的通用性和从大量数据中学习的高能力,它在过去几年一直是自然语言处理(NLP)中的主导力量[17,25,6]。现在,随着视觉变形金刚(ViTs)[10]的引入,同样的接管正在视觉领域发生。
然而,与NLP不同的是,在使用BERT[17]的NLP或使用ViT[10]的视觉中可以看到的transformers的纯实例化不是主导计算机视觉任务的力量。取而代之的是更专门的基于视觉的注意架构,如Swin[21]或MViT[11,20]或注意转换的混合,如LeViT[13]。
**这种差异背后的主要原因是效率:专门的视觉转换器可以用更少的计算来更好地执行—通过添加转换层,通过使用视觉特定的局部窗口注意,或者通过使用其他一些方法来廉价地添加视觉归纳偏差。**虽然纯vit可以在规模上表现良好(在ImageNet[38]上有90.45%的top-1),但在将模型应用于多个下游任务所需的大图像时,纯变压器的主要机制——(multihead self-attention)多头自注意[32]——可能成为一个极端的瓶颈。
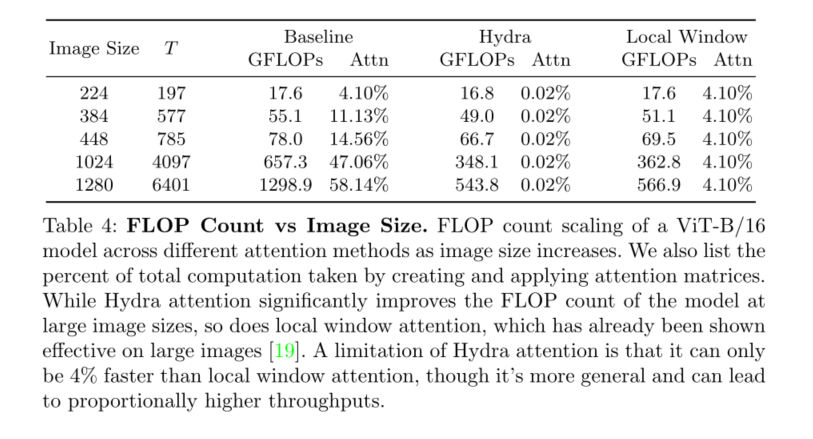
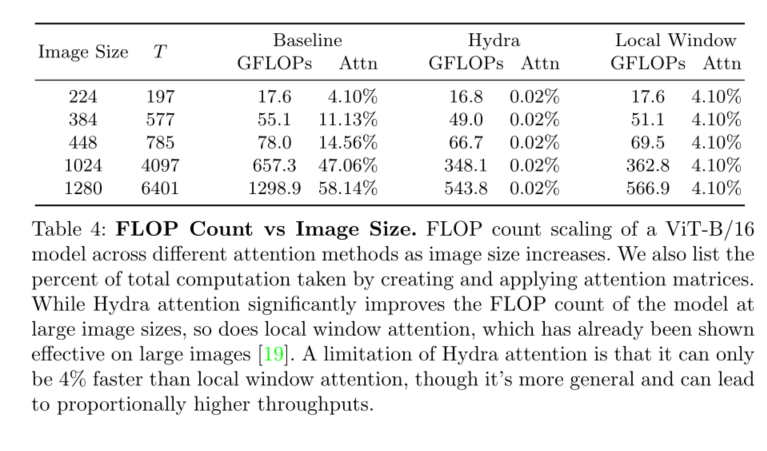
事实上,当在1080p图像上应用一个现有的ViT时,通常用于基准任务,如分割(例如,CityScapes[7]),网络中60%的总计算(见表4)仅仅用于创建和应用自我注意矩阵,相比之下,在224 × 224 ImageNet[9]图像上只有4%。在纯转换器中,这些注意矩阵的计算规模与标记的平方有关,这可能已经非常昂贵(例如NLP中的长句子)。但在ViT中,这个问题因标记按图像大小的平方缩放而进一步复杂化,这意味着图像大小翻倍将使注意力的计算增加16倍。
在NLP领域,已经开发了大量的技术来解决这个问题。一些作品引入了**“线性”注意力**(就标记而言),方法是使用“内核技巧”[5,28,16,24]重新排列计算顺序,或者投影到一个与标记无关的低秩空间[34,5,24],有些同时采用了这两种方法。然而,这些“线性”注意方法中的大多数都是以跨标记的计算来交换跨特征的计算,这使得它们相当昂贵。事实上,最近Flash Attention[8]已经表明io的多线程自我注意的高效实现可以超过大多数这些“线性”注意方法,即使令牌数在数千。
也有一些作品尝试在视觉空间中进行有效的注意,但没有一个作品是在传统的ViT外壳中独自探索的。PolyNL[2]将注意力视为一个有效的三阶多项式,但这还没有在ViT体系结构中进行探索。注意自由变压器[37]有一个AFTSimple变体,它的效率类似,但它在纯ViT中表现很差,需要convs和位置编码的额外支持。我们在标准的DeiT [31] shell中测试了这两种方法(参见表1),发现这两种方法虽然高效,但导致了显著的精度下降。因此,在文献中有一个真正有效、准确和普遍的替代多头自我注意的空间。

在这种程度上,我们引入了Hydra Attention(见图1)。我们的方法源于线性注意中的一种有些矛盾的行为:**对于标准的多头自注意,在模型中添加更多的头可以保持计算量不变。**然而,**在线性注意中改变操作顺序后,增加更多的正面实际上降低了层的计算成本。我们将这一观察结果发挥到了极致,将模型中的正面数量设置为与特征数量相等,**从而创建一个注意力模块,该模块在计算上与标记和特征都是线性的。
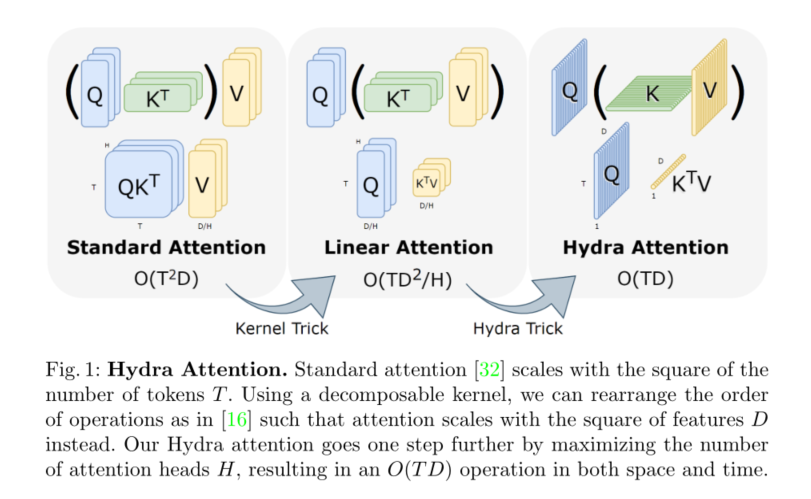
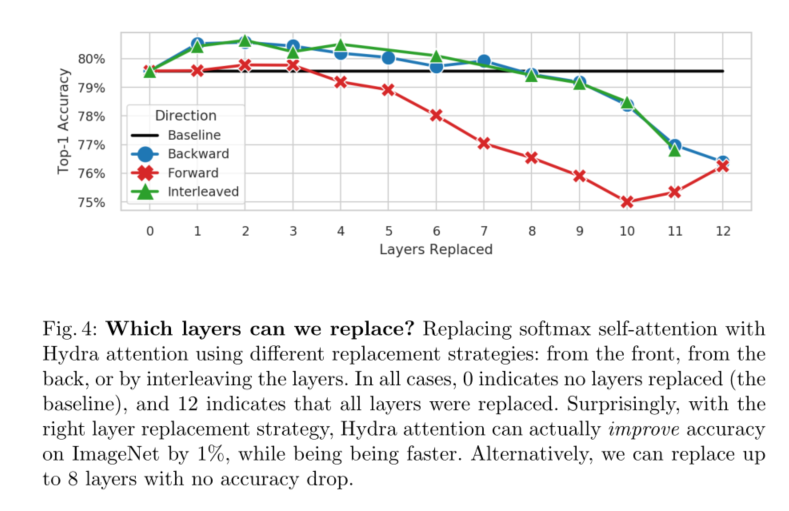
Hydra Attention不仅是先前高效注意工作的一个更通用的公式(见第3.5节),而且当使用正确的内核时,它可以显著地更准确(见表1)。事实上,当与标准多头注意混合时**,Hydra Attention实际上可以提高基线DeiT-B模型的准确性,同时速度更快(见图4)。由于是从多头注意派生而来,**我们的方法保留了注意的几个良好属性。例如可解释性(见图3)和对不同任务的通用性。

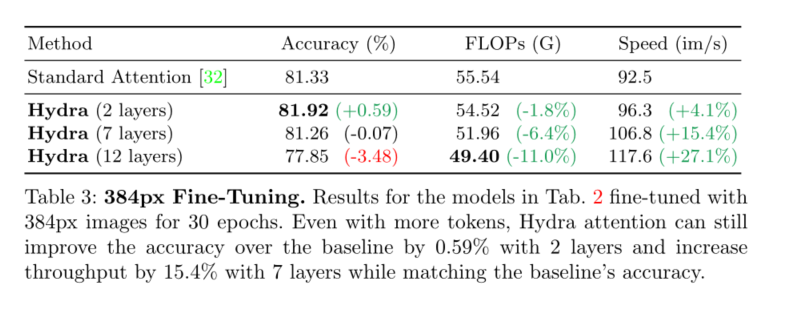
然而,虽然Hydra Attention对于大图像是通用的和有效的,在本文中我们只关注使用DeiT-B[31]的ImageNet[9]分类,它传统上使用较小的224 × 224和384 × 384图像。虽然效率的提高没有这么大(基于图像大小的10-27%),但其他有效的注意方法(如[372,2])在这种情况下已经遭受了巨大的准确性下降(见表1),而Hydra注意则没有。我们希望Hydra Attention在未来能够成为拥有大量代币的普通纯变形金刚的垫脚石。
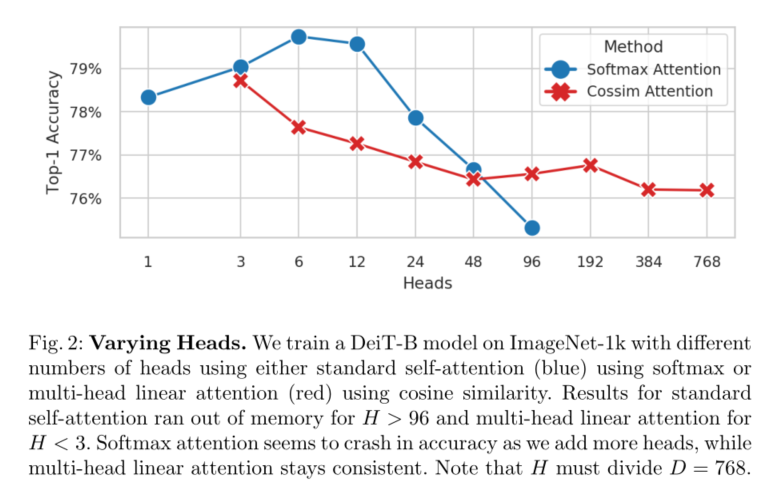
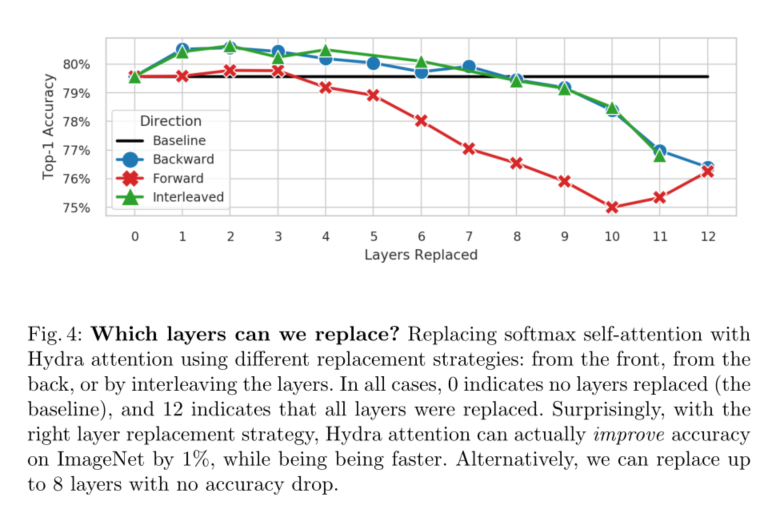
我们的贡献如下:我们进行了一项研究,以验证变压器可以有多少个头部(图2),发现12是softmax注意的极限,但在正确的核下,任何数字都是可行的**。然后,我们利用这一观察结果,通过增加多头自注意中的多头数量,为纯变压器引入九头蛇注意(第3节)**。然后,我们从数学上分析了Hydra Attention的动作(第3.4节),并介绍了一种方法来可视化它的焦点(图3)。最后,我们发现,通过用Hydra Attention替换特定的注意层(图4),我们可以提高1%的精度或匹配基线的精度,同时使用ImageNet-1k[9]上的DeiT-B[31]生成一个严格更快的模型。
2 Related Work
在本文中,我们的目标是通过消除多头自注意中的令牌平方计算瓶颈来加快变压器的推理时间。
Efficient Attention
Multihead Self-Attention[32]是一个众所周知的慢操作,已经有大量的工作试图解决它在不同领域的计算缺陷。
在自然语言处理中,一些工作用可分解核函数近似注意[5,28,16,24]。这种“核心技巧”允许他们根据特征而不是标记重新排序矩阵乘法。其中一些方法更进一步,通过向低秩空间的投影来降低矩阵乘法的维数[34,5,24]。然而,这些“线性”注意方法用跨标记的计算来交换跨特征的计算,这可能会使它们变得昂贵。事实上,在本文的领域(ImageNet分类)中,没有足够的标记来证明这些方法的正确性,而且它们中的大多数产生了一个较慢的模型。即使有成千上万的令牌,Flash Attention[8]已经表明,多线程自我注意的io感知实现实际上可以超过这些方法中最快的速度。
**但重新排序操作并不是加快注意力的唯一方法。**事实上,最常见的“线性化”视觉注意的方法是使用局部窗口注意(如[21,3,19])。这在计算上确实与令牌的数量是线性的,但是局部窗口注意可能很难计算(特别是在Swin[21]的情况下),这只有在密集的、空间有序的模态(如图像和视频)时才可能实现。
相反,我们的目标是产生一种线性注意方法,它是有效的、计算速度快的,并且可以跨越几种不同的模式。
Efficient Transformers
更换注意模块并不是加快变压器推理时间的唯一方法。事实上,根据任务和令牌的数量,其他有效的转换器方法可能更可取。例如,在ImageNet[9]分类中,注意力只占总网络计算的4%,这意味着如果只修改注意力,4%是可获得的最大加速。
有几种有效的视觉转换器将对流和注意力混合在一起,以创造一个更有效的最终产品,如LeViT [13], MobileViT [22], Mobile-Former[4]和L VT[35]。所有这些都是图像的有效策略,我们将它们视为相邻的技术。其他针对视觉的注意论文,如[37,2],除了使用高效注意外,还使用了卷积,因此很难区分这种改进是来自注意方法还是卷积的引入。
在本文中,我们没有对底层ViT体系结构做任何修改,只是将多头自注意替换为Hydra Attention,以便清楚地隔离其对性能的影响。
Multihead Attention
多头注意依赖于增加多头注意中使用的头的数量。有趣的是,自从在[32]中引入,用于多头注意的头的数量还没有深入研究。已经有一些关于修剪注意头的研究[33,23],然而所有的研究都是朝着减少注意头的数量的方向进行的。事实上,即使使用viti - g([38]中探索的最大的ViT模型),作者也只使用了16个注意力头。因此,我们在图2中进行了自己的研究。
3 Hydra Attention
标准的多头自注意[32]随图像中标记的数量呈二次增长。更具体地说,如果T是令牌的数量,D是特征维度的数量,那么创建和应用注意矩阵都是 O ( T 2 D ) O(T^2D) O(T2D)。当T很大时(就像大图像的情况一样),这就产生了一个问题,因为这种操作在计算上很快就变得不可行的。
3.1 The Kernel Trick
正如第二节所讨论的,许多著作[5,28,16,24]已经试图通过引入“线性”注意来解决这个问题。给定查询Q、键K和 R T × D R^{T ×D} RT×D中的值V,标准的softmax自我注意计算为
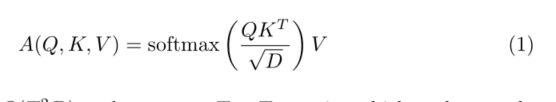
计算 Q K T QK^T QKT是 O ( T 2 D ) O(T^2D) O(T2D),并创建一个T × T矩阵,该矩阵随T的缩放很差。和[16]一样,我们可以通过将softmax(·)作为Q和k之间的成对相似度来推广这个操作。也就是说,对于某些相似函数sim(·),我们可以这样写
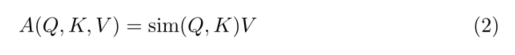
这里放原文

3.2 Multi-Head Attention
尽管与T是线性的,但Eq. 4中的结果仍然是不可取的:D通常很大(≥768),因此创建D × D矩阵并执行 O ( T D 2 ) O(TD^2) O(TD2)操作仍然非常昂贵。然而,Eq. 1到Eq. 4假设我们创建了一个注意矩阵,因此有一个“头”。
在实践中,大多数视觉转换器使用H头(通常在6到16之间),每个头创建并应用自己的注意矩阵。在[32]之后,每个头操作它们各自来自Q、K和V的D/H特征子集。因此,式1变成
放原文

3.3 Adding Heads
给定Eq. 8,我们向网络中添加的正面越多,多头线性注意就变得越快。这就引出了一个问题,到底我们可以合理地加多少个正面?大多数的变压器使用6到16个正面[32,17,10,38]取决于特征的数量D,但如果你增加正面的数量超过这个数量会发生什么?
为了找到答案,我们在ImageNet-1k[9]上训练DeiT-B[31],并使用带有softmax的标准多头自注意(Eq. 5, MSA)或带有余弦相似度的多头线性注意(Eq. 7, MLA)改变头部H的数量,绘制结果如图2所示。从内存使用情况来看,当H > 96时MSA内存耗尽,当H < 3时MLA内存耗尽。
在性能方面,MSA坦克的精度H > 12,余弦相似度的MLA的精度保持相当一致,一直到H = 768。令人惊讶的是,在这么多正面的情况下,H等于D,这意味着每个正面只有一个标量特征可以处理!
3.4 The Hydra Trick
如图2所示,只要相似度函数sim(x, y)不是softmax, H任意放大都是可行的。为了利用这一点,我们引入了“hydra trick”,即设置H = D:

此外,虽然Eq. 10的推导来自于多头注意,但它实际上最终执行了一些非常不同的事情:它首先创建了一个全局特征向量 ∑ t = 1 T ϕ ( K ) t ⊙ V t \sum_{t=1}^{T} \phi(K)^{t} \odot V^{t} ∑t=1Tϕ(K)t⊙Vt,该特征向量在图像中的所有标记之间聚集信息。然后每个φ (Q)对每 个输出令牌的这个全局特性的重要性进行gate。因此,Hydra注意力通过一个全局瓶颈混合信息,而不是像标准的自我注意那样进行显式的令牌到令牌混合。
这导致计算复杂度为
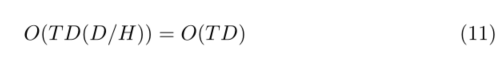
留给我们的是一个高效的标记混合模块,它与模型中的标记和特征的数量都是线性的,并且不像其他线性注意方法(如[5,34,16])那样有额外的常数。请注意,该技术的空间复杂度也是O(TD),这对于实际速度非常重要,因为许多操作都是io限制的(参见[8])。
3.5 Relation to Other Works
在文献中还有其他一些O(TD)注意候选:AttentionFree Transformer[37] (特别是after - simple)和PolyNL[2]。在本节中,我们将探讨在Eq. 10中描述的九头蛇注意力如何与每一个相关。
AFT-Simple [37] is described as
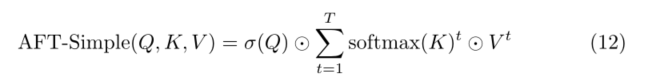

4 Experiments

5 Conclusion and Future Directions
本文介绍了一种多头高效注意模块Hydra Attention。我们表明Hydra注意优于表1中的其他O(T D)注意方法,甚至可以与传统的多头自注意协同工作,以提高图4中基线DeiT-B模型的准确性。然而,尽管Hydra注意力在ImageNet分类上表现良好(表2、表3),但它真正的加速潜力在于更大的图像(表4)。
我们已经迈出了第一步,表明Hydra注意力可以发挥作用,并希望未来的工作可以探索它在其他更token密集的领域的使用,如检测、分割或视频。此外,Hydra注意是一种通用技术,它不对标记之间的关系做任何假设,因此它可以被应用于进一步提高标记稀疏应用的速度,如掩模预训练[14,12,30]或标记修剪[26,18,36]。我们希望Hydra的关注可以被用来作为未来更强大,更高效,更通用的变压器的一步。















 3251
3251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









