





Self-Attention
说下面的句子是我们要翻译的输入句子:
”The animal didn’t cross the street because it was too tired”
这句话中的“它”指的是什么? 是指街道还是动物? 对人类来说,这是一个简单的问题,但对算法而言却不那么简单。
当模型处理单词“ it”时,自我关注使它可以将“ it”与“ animal”相关联。
在模型处理每个单词(输入序列中的每个位置)时,自我关注使其能够查看输入序列中的其他位置以寻找线索,从而有助于更好地对该单词进行编码。
如果您熟悉RNN,请考虑一下如何通过保持隐藏状态来使RNN将其已处理的先前单词/向量的表示形式与当前正在处理的单词/向量进行合并。 Transformer使用self attention将其他相关单词的“理解”融入到我们当前正在处理的单词中的过程中。

计算 Self-Attention 的 attention
首先,让我们看看如何使用向量来计算自我注意力,然后着眼于如何使用矩阵来实现自我注意力。
计算自我注意力的第一步是从每个编码器的输入向量中创建三个向量(在这种情况下,是每个单词的嵌入)。 因此,对于每个单词,我们创建一个查询向量,一个键向量和一个值向量。 这些向量是通过将嵌入乘以我们在训练过程中训练的三个矩阵而创建的。
请注意,这些新向量的维数小于嵌入向量的维数。 它们的维数为64,而嵌入和编码器输入/输出矢量的维数为512。它们不必较小,这是使多头注意力(大部分)计算保持恒定的体系结构选择。

什么是“query”,“key”和“vector”向量?
它们是抽象,对于计算和思考注意力非常有用。计算自我注意力的第二步是计算score。 假设我们正在计算此示例“Thinking”中第一个单词的self attention。 我们需要根据该单词对输入句子的每个单词score。 score 决定了当我们在某个位置对单词进行编码时,将attention 集中在输入句子的其他部分上的程度。 Score 是是通过将“query”向量和各个单词“key”向量的点积得出的。

第三和第四步是将score除以8(本文中使用的“key”向量的维数的平方根–64。这将导致梯度更稳定。此处可能存在其他可能的值,但这是 默认值),然后通过softmax操作传递结果。 Softmax对分数进行归一化,使它们均为正并加1。

这个softmax score确定每个单词在此位置将被表达多少。 显然,该位置的单词的softmax得分最高,但是 我们也同时需要用attention 去关注其他相关的单词,这要用到multi heads attentions。
第五步是将每个值向量乘以softmax分数(准备将它们相加)。 直觉是保持我们要关注的单词的值完整,并淹没无关的单词(例如,将它们乘以0.001之类的小数字)。
第六步是对加权向量进行求和。 这将在此位置(对于第一个单词)产生自我注意层的输出。

我们可以发送生成的向量到前馈神经网络。 但是,在实际实现中,此计算以矩阵形式进行,以加快处理速度。
Self-Attention 矩阵的计算
第一步是计算“query”和“key”值的矩阵。 为此,我们将嵌入内容打包到矩阵X中,然后将其乘以我们训练过的权重矩阵(WQ,WK,WV)。

最后,由于我们要处理矩阵,因此我们可以将步骤2到6压缩成一个公式,以计算自我注意层的输出。
“multi-headed” attention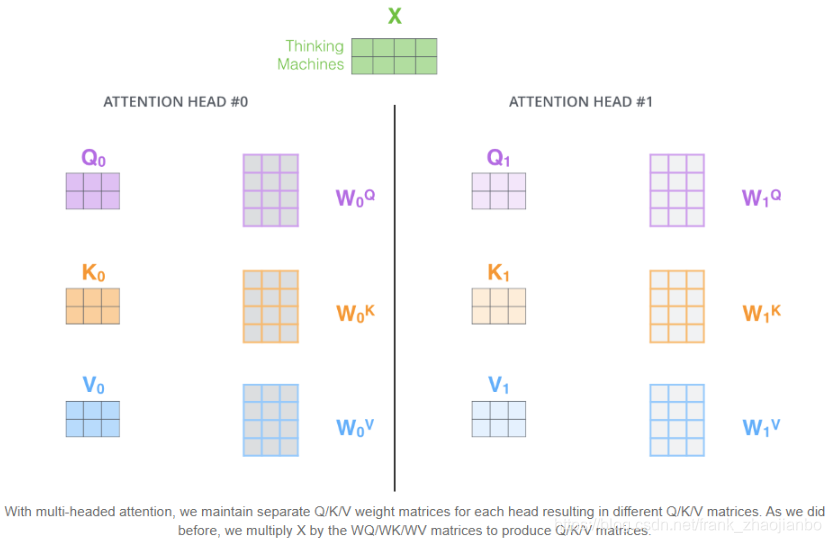
如果我们执行上面概述的相同的自注意力计算,最终将得到2个不同的Z矩阵 
这给我们带来了一些挑战。 前馈层只要有一个矩阵(每个单词一个向量)。 因此,我们需要一种将这2个矩阵压缩为一个矩阵的方法。
我们该怎么做? 我们合并矩阵,然后将它们乘以其他权重矩阵WO。

multi heads attention 的计算过程如下:

例如 这个例子中我们有8个attention heads,第一个attention head的注意力显示 it 和 because 最相关,第二个attention head的注意力显示 it 和 cross 最相关,等等…

multi-heads attention 的代码
这里我们用一个文本2分类的任务融合 attention机制来解释 multi heads attention理论
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torch.autograd import Variable
import random
def set_random_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
set_random_seed(6688)
device = torch.device('cuda' if torch.cuda.is_available else 'cpu')
data_path = 'F:/data/'
from collections import Counter
def build_vocab(sents, max_words=50000):
word_counts = Counter()
for word in sents:
word_counts[word] += 1
itos = [w for w, c in word_counts.most_common(max_words)]
itos = itos + ["UNK"]
stoi = {w: i for i, w in enumerate(itos)}
return itos, stoi
tokenize = lambda x: x.split()
text = open(data_path + 'senti.train.tsv').read()
vob = tokenize(text.lower())
itos, stoi = build_vocab(vob)
itos[0:5]
['1', '0', 'the', ',', 'a']
设计数据集
class Corpus:
def __init__(self, data_path, sort_by_len=False):
self.vocab = vob
self.sort_by_len = sort_by_len
self.train_data, self.train_label = self.tokenize(data_path + 'train.tsv')
self.valid_data, self.valid_label = self.tokenize(data_path + 'dev.tsv')
self.test_data, self.test_label = self.tokenize(data_path + 'test.tsv')
def tokenize(self, text_path):
with open(text_path) as f:
index_data = [] # 索引数据,存储每个样本的单词索引列表
labels = []
for line in f.readlines():
sentence, label = line.split('\t')
index_data.append(
self.sentence_to_index(sentence.lower())
)
labels.append(
int(label[0])
)
if self.sort_by_len: # 为了提升训练速度,可以考虑将样本按照长度排序,这样可以减少padding
index_data = sorted(index_data, key=lambda x: len(x), reverse=True)
return index_data, labels
def sentence_to_index(self, s):
a = []
for w in s.split():
if w in stoi.keys():
a.append(stoi[w])
else:
a.append(stoi["UNK"])
return a
def index_to_sentence(self, x):
return ' '.join([itos[i] for i in x])
corpus = Corpus(data_path, sort_by_len=False)
设计batches
def get_minibatches(text_idx, labels, batch_size=64, sort=False):
if sort:
text_idx_and_labels = sorted(list(zip(text_idx, labels)), key=lambda x: len(x[0]))
else:
text_idx_and_labels = (list(zip(text_idx, labels)))
text_idx_batches = []
label_batches = []
for i in range(0, len(text_idx), batch_size):
text_batch = [t for t, l in text_idx_and_labels[i:i + batch_size]]
label_batch = [l for t, l in text_idx_and_labels[i:i + batch_size]]
text_idx_batches.append(text_batch)
label_batches.append(label_batch)
return text_idx_batches, label_batches
BATCH_SIZE = 256
VOCAB_SIZE = len(itos)
EMBEDDING_SIZE = 256
OUTPUT_SIZE = 1
train_batches, train_label_batches = get_minibatches(corpus.train_data, corpus.train_label, BATCH_SIZE)
dev_batches, dev_label_batches = get_minibatches(corpus.valid_data, corpus.valid_label, BATCH_SIZE)
test_batches, test_label_batches = get_minibatches(corpus.test_data, corpus.test_label, BATCH_SIZE)
设计attention 中的 positional encoding
import math
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
设计attention score 的叉乘操作
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
# Q: [ batch_size ,n_heads ,seq_length ,d_k ]
# K: [ batch_size ,n_heads ,seq_length ,d_k ]
# V: [ batch_size ,n_heads ,seq_length ,d_k ]
# scores: [ batch_size ,n_heads ,seq_length ,seq_length ]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
# Fills elements of self tensor with value where mask is one.
scores.masked_fill_(attn_mask, -1e9)
# attn: [ batch_size ,n_heads ,seq_length,seq_length ]
attn = nn.Softmax(dim=-1)(scores)
# context: [batch_size , n_heads ,seq_length, d_k]
Z = torch.matmul(attn, V)
return Z
设计多头的attention
class MultiHeadAttention(nn.Module):
def __init__(self, embedding_size, d_k, n_heads):
super(MultiHeadAttention, self).__init__()
# self.W_Q.weight: [ n_heads*d_k, EMBEDDING_SIZE ]
self.W_Q = nn.Linear(EMBEDDING_SIZE, n_heads * d_k)
# self.W_K.weight: [ n_heads*d_k, EMBEDDING_SIZE ]
self.W_K = nn.Linear(EMBEDDING_SIZE, n_heads * d_k)
# self.W_V.weight: [ n_heads*d_k, EMBEDDING_SIZE ]
self.W_V = nn.Linear(EMBEDDING_SIZE, n_heads * d_k)
self.n_heads = n_heads
self.d_model = embedding_size
self.d_k = d_k
def forward(self, Q, attn_mask):
# q: [batch_size,seq_length, EMBEDDING_SIZE]
# residual, batch_size = Q, Q.size(0)
batch_size = Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
# q_s: [batch_size, n_heads, seq_length, d_k]
q_s = self.W_Q(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1,2)
# k_s: [batch_size, n_heads, seq_length, d_k]
k_s = self.W_K(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1,2)
# v_s: [batch_size, n_heads, seq_length, d_k]
v_s = self.W_V(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1,2)
attn_mask = attn_mask.eq(0)
# attn_mask : [batch_size, n_heads, seq_length, seq_length]
attn_mask = attn_mask.unsqueeze(1).unsqueeze(3).repeat(1, self.n_heads, 1, k_s.size(2))
# Z : [batch_size, n_heads, seq_length, d_k]
Z = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
# Z : [batch_size , seq_length , n_heads * d_k]
Z = Z.transpose(1, 2).contiguous().view(batch_size, -1, self.d_k * self.n_heads)
# output : [batch_size , seq_length , embedding_size]
output = nn.Linear(self.d_k * self.n_heads, self.d_model).to(device)(Z)
return output
设置 attention的头数量 以及 q k v的维度
d_k = 4 # dimension of K(=Q), V
heads_num = 2
class Encoder(nn.Module):
def __init__(self, vocab_size, embedding_size, output_size, dropout_p=0.5):
super(Encoder, self).__init__()
self.embed = nn.Embedding(vocab_size, embedding_size)
initrange = 0.1
self.embed.weight.data.uniform_(-initrange, initrange)
self.embed_words = nn.Embedding(vocab_size, embedding_size)
self.linear = nn.Linear(embedding_size, output_size)
self.dropout = nn.Dropout(dropout_p)
self.attentions = MultiHeadAttention(embedding_size, d_k, heads_num)
self.Pos = PositionalEncoding(embedding_size, dropout_p, max_len=5000)
设计attention 加权平均模型
class WordAVGModel(nn.Module):
def __init__(self, vocab_size, embedding_size, output_size, dropout_p=0.5):
super(WordAVGModel, self).__init__()
self.embedding_size = embedding_size
self.output_size = output_size
self.encoder = Encoder(vocab_size, embedding_size, output_size, dropout_p)
def forward(self, text, mask):
# text: [batch_size * max_seq_len] mask: [batch_size * max_seq_len]
# embedded: [batch_size, max_seq_len, embedding_size]
embedded = self.encoder.embed(text)
# embedded: [batch_size, max_seq_len, embedding_size]
#embedded = self.encoder.Pos(embedded)
# embedded: [batch_size, max_seq_len, embedding_size]
embedded = self.encoder.dropout(embedded)
# enc_inputs to same Q,K,V 为模型加入 multi-heads attention
# a_ts: [batch_size , max_seq_len , embedding_size]
a_ts = self.encoder.attentions(embedded,mask)
# a_t: [batch_size , max_seq_len]
a_t = torch.sum(a_ts,2)
# a_t: [batch_size , max_seq_len]
a_t = torch.softmax(a_t, dim=1)
# h_self: [batch_size ,embedding_size]
h_self = torch.bmm(a_t.unsqueeze(1), embedded).squeeze()
# mask: [batch_size, max_seq_len, 1], 1 represents word, 0 represents padding
mask = mask.float().unsqueeze(2)
# embedded: [batch_size, max_seq_len, embedding_size]
embedded = embedded * mask
# h_av: [batch_size, embedding_size]
h_av = embedded.sum(1) / (mask.sum(1) + 1e-9) # 防止mask.sum为0,那么不能除以零。
# out: [batch_size, output_size]
out = self.encoder.linear(h_self)
#out = self.encoder.linear(h_self + h_av)
return out
model = WordAVGModel(vocab_size=VOCAB_SIZE,
embedding_size=EMBEDDING_SIZE,
output_size=OUTPUT_SIZE,
dropout_p=0.5)
optimizer = torch.optim.Adam(model.parameters())
crit = nn.BCEWithLogitsLoss()
model = model.to(device)
def binary_accuracy(preds, y):
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float()
acc = correct.sum() / len(correct)
return acc
def train(model, text_idxs, labels, optimizer, crit):
epoch_loss, epoch_acc = 0., 0.
model.train()
total_len = 0.
for text, label in zip(text_idxs, labels):
text = [torch.tensor(x).long().to(device) for x in (text)]
label = [torch.tensor(label).long().to(device)]
lengths = torch.tensor([len(x) for x in text]).long().to(device)
text = nn.utils.rnn.pad_sequence(text, batch_first=True)
mask = (text != 0).float().to(device)
# 在之后的训练中因为还要进行pack_padded_sequence操作,所以在这里按照长度降序排列
lengths, perm_index = lengths.sort(descending=True)
text = text[perm_index]
label = label[0][perm_index]
preds = model(text, mask).squeeze() # [batch_size, sent_length]
loss = crit(preds, label.float())
acc = binary_accuracy(preds, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item() * len(label)
epoch_acc += acc.item() * len(label)
total_len += len(label)
return epoch_loss / total_len, epoch_acc / total_len
def evaluate(model, text_idxs, labels, crit):
epoch_loss, epoch_acc = 0., 0.
model.train()
total_len = 0.
for text, label in zip(text_idxs, labels):
text = [torch.tensor(x).long().to(device) for x in (text)]
label = [torch.tensor(label).long().to(device)]
lengths = torch.tensor([len(x) for x in text]).long().to(device)
text = nn.utils.rnn.pad_sequence(text, batch_first=True)
mask = (text != 0).float().to(device)
pad_attn_mask = mask.eq(0).unsqueeze(1)
# 在之后的训练中因为还要进行pack_padded_sequence操作,所以在这里按照长度降序排列
lengths, perm_index = lengths.sort(descending=True)
text = text[perm_index]
label = label[0][perm_index]
with torch.no_grad():
preds = model(text, mask).squeeze() # [batch_size, sent_length]
loss = crit(preds, label.float())
acc = binary_accuracy(preds, label)
epoch_loss += loss.item() * len(label)
epoch_acc += acc.item() * len(label)
total_len += len(label)
return epoch_loss / total_len, epoch_acc / total_len
训练模型
N_EPOCHS = 30
best_valid_acc = 0.
record = 0
for epoch in range(N_EPOCHS):
train_loss, train_acc = train(model, train_batches, train_label_batches, optimizer, crit)
valid_loss, valid_acc = evaluate(model, dev_batches, dev_label_batches, crit)
if valid_acc > best_valid_acc:
record = 0
best_valid_acc = valid_acc
torch.save(model.state_dict(), "wordavg-model-Adam.pth")
else:
record += 1
if record > 30:
print("early stopping at epoch", epoch)
break
if epoch % 5 == 0:
print("Epoch", epoch, "Train Loss", train_loss, "Train Acc", train_acc)
print("Epoch", epoch, "Valid Loss", valid_loss, "Valid Acc", valid_acc)
Epoch 0 Train Loss 0.6855089499452708 Train Acc 0.5557145779421909
Epoch 0 Valid Loss 0.6951910366705798 Valid Acc 0.5091743135671003
Epoch 5 Train Loss 0.5996944122435344 Train Acc 0.7028215090279393
Epoch 5 Valid Loss 0.5999153551705386 Valid Acc 0.7075688084331128
Epoch 10 Train Loss 0.4333473568592937 Train Acc 0.8600490696955205
Epoch 10 Valid Loss 0.4965302976993246 Valid Acc 0.7694954188591844
Epoch 15 Train Loss 0.32046079018673657 Train Acc 0.914127990246989
Epoch 15 Valid Loss 0.46561843430230376 Valid Acc 0.7970183519048428
Epoch 20 Train Loss 0.24862328401142725 Train Acc 0.9407074219169999
Epoch 20 Valid Loss 0.4701578086669292 Valid Acc 0.7935779838387026
Epoch 25 Train Loss 0.20012277661322134 Train Acc 0.9533837661619349
Epoch 25 Valid Loss 0.4839585598455657 Valid Acc 0.7970183535453377
预测test
model.load_state_dict(torch.load("wordavg-model-Adam.pth"))
test_loss, test_acc = evaluate(model, test_batches, test_label_batches, crit)
print("Test Loss", test_loss, "Test Acc", test_acc)
Test Loss 0.4726336712957672 Test Acc 0.7935200437027828















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









