






上篇:AI改善生物多样性-1
Conservation planning within a reinforcement learning framework
在模型中,通过 RL 在预定义的政策目标下优化保护政策(例如,最小化生物多样性的丧失或最大限度地扩大保护区的范围)。
CAPTAIN:
- Actions:monitoring action & protecting action
- Reward: 定义了模拟的最优性标准,并且可以量化在模拟评估的整个时间范围内没有灭绝的物种的累积值
如果Reward在所有物种中权重相等,则 RL 算法将最小化整体物种灭绝。也可以将Reward设置为保护区里的数量,这样算法就会最大化里面个体的数量,而不考虑哪个物种。
预算:
成本: 为时间段,c为个体
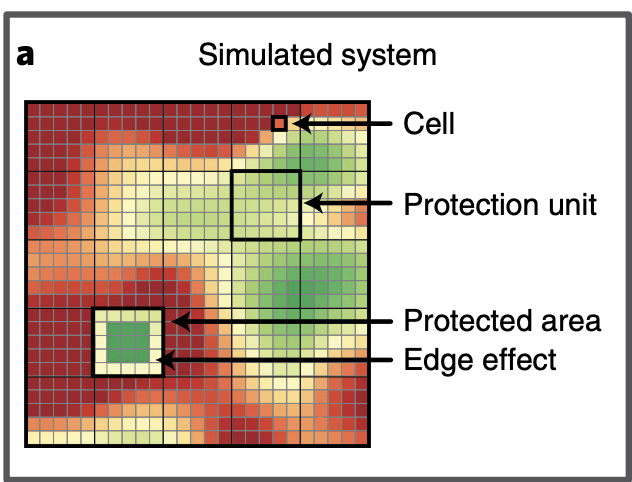
监控和保护动作的粒度是基于可能包含一个或多个单元的空间单元,其定义为保护单元(protection units)。保护单元是相邻的、不重叠的大小相等的区域,区域成本可以以里面单元的成本累加得到。
action(监控)收集每个保护单元内有关系统的状态,其中包括物种丰度和地理分布:

为定义特征抽取结果,每个单元返回的抽取特征取决于监控,是预定的monitoring
决定的。预定的monitoring策略还决定了在模拟中的时间频率,为每个单元抽取的特征,如果在预算允许的情况下,是 protecting action
的依据。特征包括在其他未受保护的数量、稀有物种的数量、预算的剩余。
不假设物种特异性对干扰的敏感性是已知特征,这个作为参数来学习。
protecting action选择一个保护单元并将包含的单元中的干扰重置为极低水平,受保护的单位也不受未来人为干扰增加的影响,但并不能防止该单位的气候变化。该模型是负面边缘效应(例如,边缘比中心更容易受到极端天气的影响)。且保护一个已经遭受生物多样性丧失的地区可能不会恢复其原有的生物多样性水平
protecting action的成本又选择的区域所有的个体累积成本组成,且必须有预算约束。
Policy definition and optimization algorithm
定义优化问题:随机控制问题
protection policy 是 probabilistic policy,产出的是概率数组
monitoring policy 是固定的
Protection policy预测网络

至此,迭代结束
项目地址:Captain
论文地址:https://www.nature.com/articles/s41893-022-00851-6.pdf















 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









