






 本文提出了一种在多车辆多基站的车联网场景中,结合NOMA和MEC的系统架构,通过优化任务调度和上行传输功率分配,以减小任务加权时延,提升用户满意度。使用深度强化学习的PPO算法解决MEC任务调度问题,并应用CMA-ES算法进行功率分配。同时,文章包含了PSO模拟代码示例。
本文提出了一种在多车辆多基站的车联网场景中,结合NOMA和MEC的系统架构,通过优化任务调度和上行传输功率分配,以减小任务加权时延,提升用户满意度。使用深度强化学习的PPO算法解决MEC任务调度问题,并应用CMA-ES算法进行功率分配。同时,文章包含了PSO模拟代码示例。
一、内容简介
在多车辆多基站的车联网场景中,考虑了异构的边缘云服务器与远端云服务器资源的联合调度,构建了 NOMA 辅助的 MEC 系统架构和智能服务交付流程,建立了车辆用户任务的通信模型与任务计算模型。
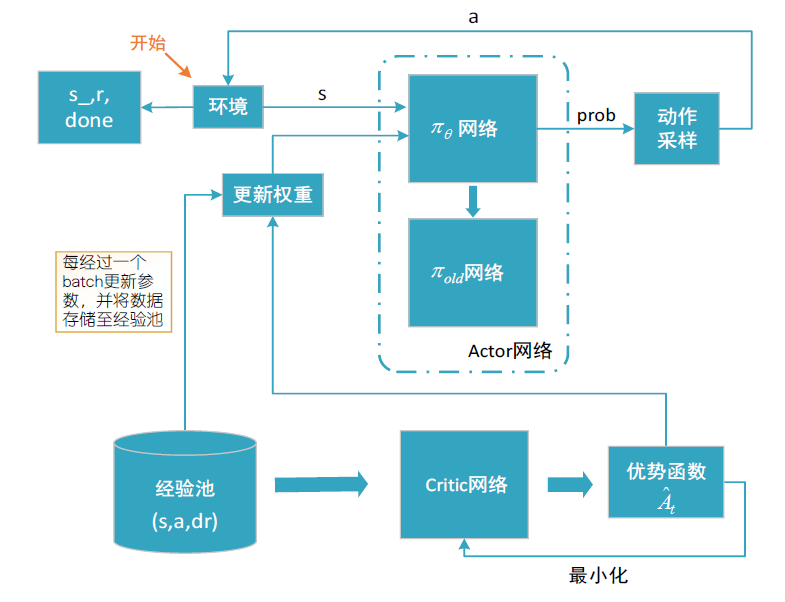
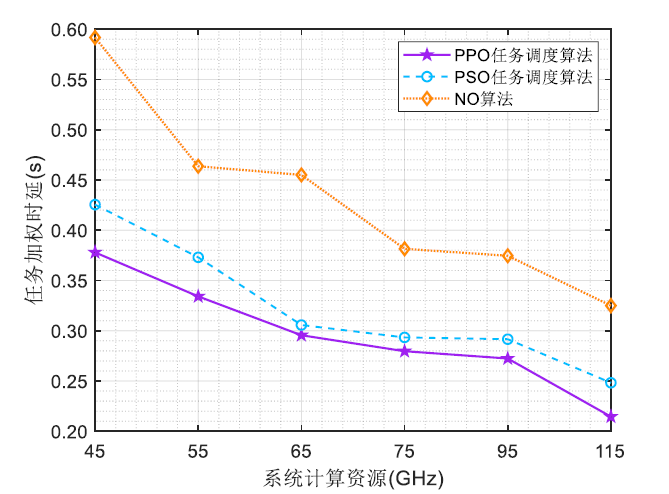
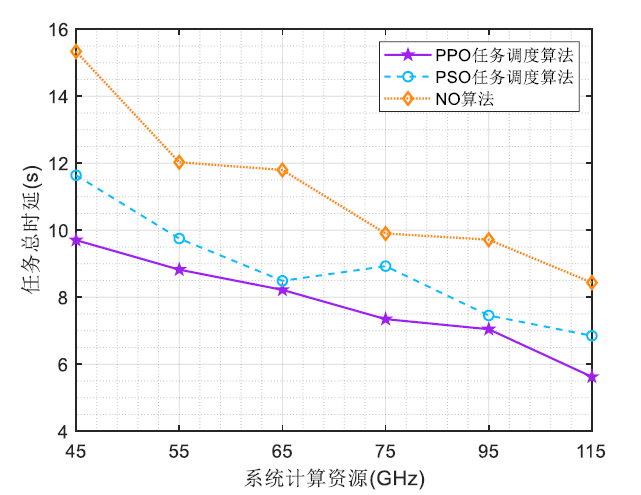
在建立了车联网场景中 MEC 系统的通信和计算模型的基础上,针对 MEC 任务调度问题,建立了以车辆用户的任务加权时延最小化为目标的优化问题模型,旨在从计算资源的分配上提高系统的时延性能,在计算阶段优化车辆用户任务完成时延,提高用户满意度。为了使研究更具一般性,还考虑了边缘服务器的存储资源的有限问题和NOMA 用户集群的分簇问题,将这两个附加问题设定为优化问题的约束条件。针对上述优化问题,本文利用深度强化学习方法,设计了基于 PPO 的任务调度算法。
针对不同 NOMA 簇中车辆用户的功率分配问题,以在上行传输阶段进一步降低车辆用户的任务完成时延,提高用户满意度为目标,建立了功率分配问题模型。在对每个基站下的用户集群进行了 NOMA 分簇的基础上,设计车辆上行传输功率分配策略,提出了基于 CMA-ES 的功率分配算法。
二、部分代码与仿真
package com.clj.demo;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;public class PSO_main {
public static void main(String[] args) {
int instNum = 6; // 最大实例数
int instTypeNum = 3; // 实例类型数
int instBuyOptionNum = 2; // 实例选择数
int strNum = 1000; // 初始化粒子串数
final int MAX_ITERATION = 800;// 迭代次数SAXReader reader = new SAXReader();// 创建SAXReader对象用于读取xml文件
try {
Document doc = reader.read(new File("D:\\homework\\边缘计算\\PSO实现\\xmltest\\Epigenomics_100.xml"));// 读取xml文件,获得Document对象
Element root = doc.getRootElement(); // 获取根元素
List<Element> jobElements = root.elements("job");// 获取根元素下的所有job标签的子元素
final int taskNum = jobElements.size(); // 任务数
final int dimension = 2 * instNum + taskNum + 1; // 每个粒子串的维数
double[][] locats = new double[strNum][dimension]; // 初始化位置粒子串
int[] tasks =new int[taskNum]; // 任务节点名称数组
double[] task_exec = new double[taskNum]; // 每个任务执行时间(在Small类型实例上)数组
int[][] task_depen = new int[taskNum][taskNum]; // 初始化DAG图
for (int i = 0; i < jobElements.size(); i++) { // 初始化顶点表task及任务执行时间表task_exec
tasks[i] = i;
task_exec[i] = Double.parseDouble(jobElements.get(i).attributeValue("runtime"));
}
for (int i = 0; i < taskNum; i++) { // 初始化邻接矩阵
for (int j = 0; j < taskNum; j++) {
task_depen[i][j] = 0;
}
}
List<Element> childElements = root.elements("child");// 获取根元素下的所有child标签的子元素
for (int i = 0; i < childElements.size(); i++) {
String vex_str = childElements.get(i).attributeValue("ref");
int vex_int = Integer.parseInt(vex_str.substring(2));
List<Element> parents = childElements.get(i).elements("parent");// 获取child元素下的所有parent标签元素
for (int j = 0; j < parents.size(); j++) {
String vex_parent_str = parents.get(j).attributeValue("ref");
int vex_parent_int = Integer.parseInt(vex_parent_str.substring(2));
task_depen[vex_parent_int][vex_int] = 1;
}
}
double[] task_exec_real = new double[taskNum]; // 每个任务的实际执行时间
double[][] task_time = new double[taskNum][2]; // 每个任务的EST、EFT矩阵int[][] locat_int = new int[strNum][dimension]; // locat_int存决策串
for (int i = 0; i < strNum; i++) {
for (int j = 0; j < dimension; j++) {
locats[i][j] = Math.random();
}
}
double[][] velocity = new double[strNum][dimension];// 初始化速度粒子串
for (int i = 0; i < strNum; i++) {
for (int j = 0; j < dimension; j++) {
velocity[i][j] = -0.5 + Math.random();
}
}// 1.2 处理位置粒子串(将粒子串数值转为整形)
for (int i = 0; i < strNum; ++i) {
for (int j = 0; j < dimension; ++j) {
if (j == 0) {
locat_int[i][j] = (int) Math.round(locats[i][j] * instNum);
if (locat_int[i][j] == 0) {
locat_int[i][j] = 1;
}
} else if (j > 0 && j <= instNum) {
locat_int[i][j] = (int) Math.round(locats[i][j] * instTypeNum);
if (locat_int[i][j] == 0) {
locat_int[i][j] = 1;
}
} else if (j > instNum && j <= instNum * 2) {
locat_int[i][j] = (int) Math.round(locats[i][j] * instBuyOptionNum);
if (locat_int[i][j] == 0) {
locat_int[i][j] = 1;
}
} else {
if (locat_int[i][0] == 1) {
locat_int[i][j] = 1;
} else {
locat_int[i][j] = (int) Math.round(locats[i][j] * instNum);
if (locat_int[i][j] == 0) {
locat_int[i][j] = 1;
}
}
}
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











