







✅博主简介:本人擅长数据处理、建模仿真、程序设计、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。
-
循环流化床技术的发展与研究对象介绍
- 循环流化床(CFB)锅炉技术因其燃烧效率高、污染物排放低等优点得到了广泛应用。在超超临界(USC)参数下,CFB技术的应用进一步提升了燃煤电厂的热效率,减低了二氧化碳排放。
- 本研究选取威赫电厂660MW超超临界CFB锅炉作为研究对象,该锅炉采用屏式过热器结构,但该类型锅炉容易发生超温爆管泄漏故障。针对这一问题,本研究设计了基于机器学习的故障诊断模型,以提高故障检测的准确性和及时性。
-
屏式过热器超温爆管泄漏故障的原因分析
- 屏式过热器的爆管泄漏故障主要由以下原因导致:
- 高温腐蚀:锅炉在超超临界条件下运行,金属管壁温度较高,易受到腐蚀性气体(如SO2、Cl2等)的影响。
- 热应力破坏:频繁的温度波动和不均匀的热分布导致管壁应力集中,最终引发爆管。
- 材质老化和疲劳:长期的高温高压运行导致过热器材料的老化和疲劳损伤,使其易发生泄漏故障。
- 屏式过热器的爆管泄漏故障主要由以下原因导致:
-
故障诊断模型的构建与数据仿真
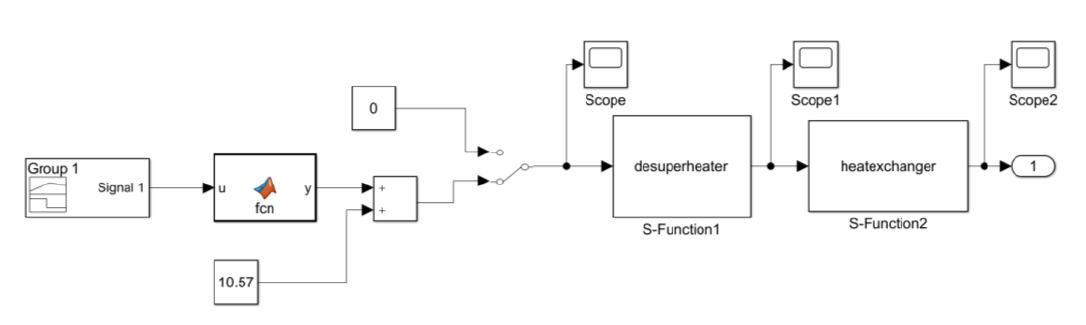
- 研究以屏式过热器及其喷水减温装置的质量守恒、能量守恒和动量守恒方程为理论基础,利用MATLAB/Simulink软件构建了屏式过热器的仿真模型。
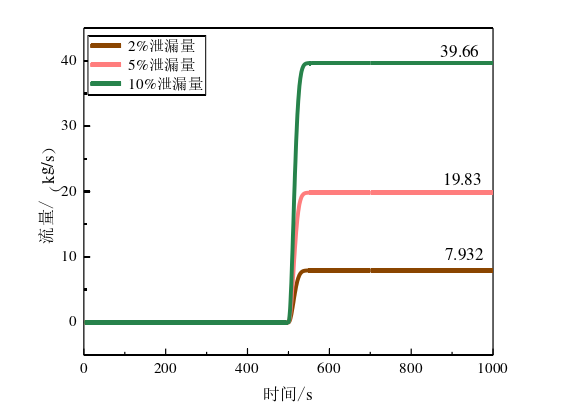
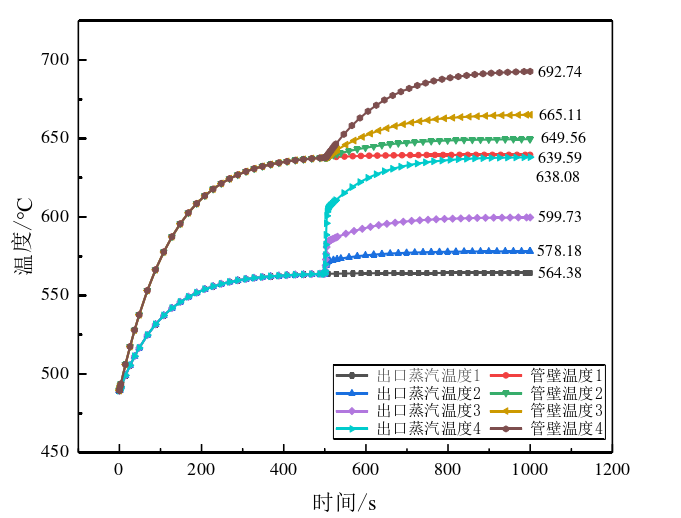
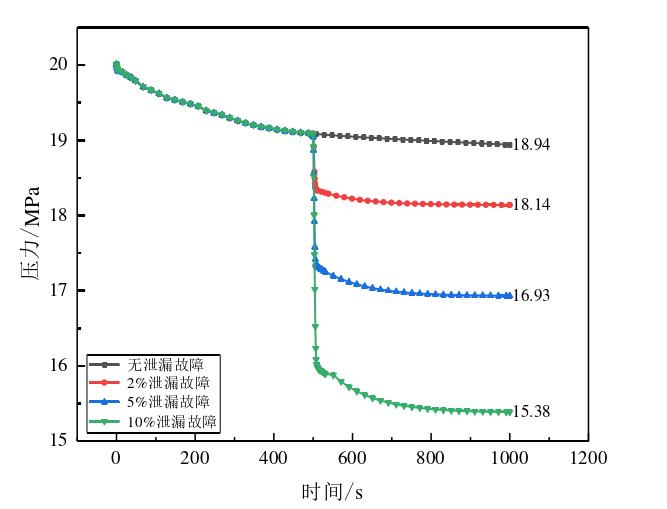
- 在模型中引入不同量级的泄漏量扰动,获得各种泄漏情况下的仿真数据,这些数据将作为故障诊断模型的训练样本数据。具体仿真过程如下:
- 通过调整仿真模型中的泄漏参数,模拟过热器在不同泄漏程度和泄漏位置下的运行状态,生成故障数据集。
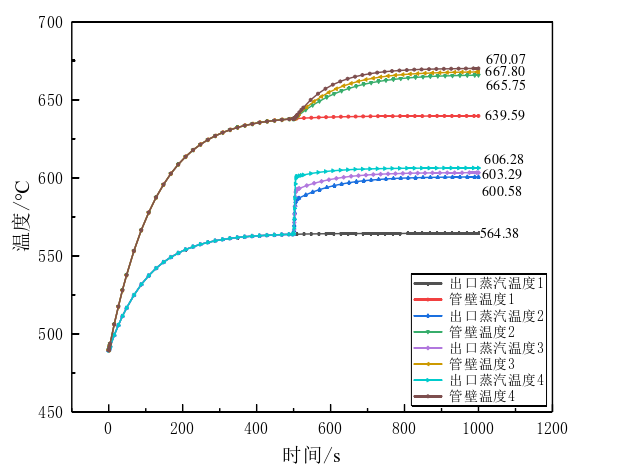
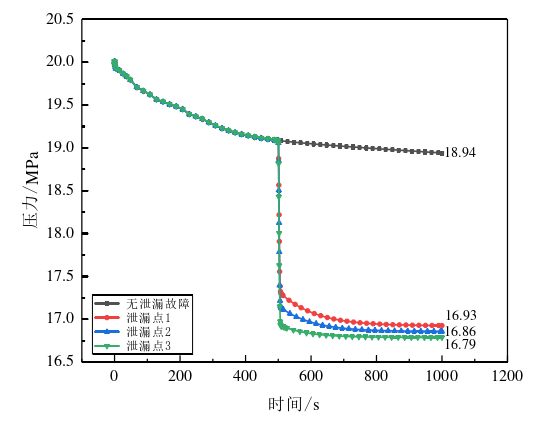
- 采集的故障数据包括出口蒸汽温度、管壁温度、出口压力等关键参数。
-
泄漏故障严重程度分类诊断的机器学习模型设计
- 选取不同泄漏量下的故障数据作为样本数据,并进行数据预处理,包括去噪、归一化等步骤。
- 以屏式过热器出口蒸汽温度、管壁温度以及出口压力作为输入变量,建立随机森林分类模型,对屏式过热器的泄漏故障严重程度进行分类诊断。
- 随机森林模型设计:
- 利用多颗决策树对输入样本进行训练,每棵决策树从样本数据中随机抽取部分数据和特征进行训练,以增加模型的鲁棒性。
- 通过集成学习方法,将所有决策树的分类结果进行投票表决,从而确定最终的故障严重程度分类。
- 模型训练与验证:
- 利用仿真生成的故障数据集进行模型训练,并使用交叉验证方法评估模型的准确率、召回率和F1分数等性能指标。
模型:
泄漏故障定位模型的优化与性能分析
- 选取不同泄漏点下的故障数据作为样本数据并进行预处理,以屏式过热器的特征参数为输入变量,分别采用未经优化的支持向量机(SVM)模型和基于稀疏自适应算法(SSA)优化的SVM模型对屏式过热器爆管泄漏故障的泄漏点进行预测。
- 未经优化的SVM泄漏故障定位模型:
- 使用标准SVM模型对故障数据进行训练,将不同泄漏点数据作为分类任务的输出。
- 模型性能受参数选择影响较大,且在样本不均衡情况下,容易出现欠拟合或过拟合问题。
- SSA优化SVM模型:
- 利用稀疏自适应算法(SSA)优化SVM的超参数,包括核函数参数和惩罚因子,以提高模型的泛化能力和定位精度。
- 性能指标比较:
- 对比分析未经优化的SVM模型与SSA优化SVM模型在不同测试数据集上的故障定位准确率、定位时间和计算复杂度。结果表明,SSA优化的SVM模型具有更高的准确率和稳定性,尤其在复杂故障模式下表现出更优的诊断性能。
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score
from sklearn.model_selection import train_test_split, GridSearchCV
# 读取故障数据
data = pd.read_csv('fault_data.csv') # 假设的故障数据文件
X = data[['Steam_Temp', 'Wall_Temp', 'Outlet_Pressure']] # 输入特征
y_severity = data['Fault_Severity'] # 故障严重程度标签
y_location = data['Leakage_Location'] # 泄漏点位置标签
# 分割数据集
X_train, X_test, y_train_severity, y_test_severity = train_test_split(X, y_severity, test_size=0.3, random_state=42)
X_train_loc, X_test_loc, y_train_loc, y_test_loc = train_test_split(X, y_location, test_size=0.3, random_state=42)
# 随机森林分类模型:故障严重程度诊断
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train_severity)
severity_predictions = rf_model.predict(X_test)
print("随机森林分类报告:\n", classification_report(y_test_severity, severity_predictions))
# SVM模型:故障定位
svm_model = SVC(kernel='rbf')
svm_model.fit(X_train_loc, y_train_loc)
location_predictions = svm_model.predict(X_test_loc)
print("未经优化的SVM分类报告:\n", classification_report(y_test_loc, location_predictions))
# SSA优化SVM模型
param_grid = {'C': [0.1, 1, 10], 'gamma': [1, 0.1, 0.01]}
grid_search = GridSearchCV(SVC(kernel='rbf'), param_grid, refit=True, verbose=3)
grid_search.fit(X_train_loc, y_train_loc)
optimized_svm_model = grid_search.best_estimator_
optimized_location_predictions = optimized_svm_model.predict(X_test_loc)
print("SSA优化SVM分类报告:\n", classification_report(y_test_loc, optimized_location_predictions))



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











