







✅博主简介:本人擅长数据处理、建模仿真、程序设计、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。
-
数字孪生技术在智慧供热系统中的应用
- 技术背景与目标:
- 依托数字孪生技术,结合城镇供热系统的物理结构和信息融合理念,建立全尺度虚拟数字孪生模型,实现对供热系统的精确、科学管理。
- 数字孪生技术的应用能够提高供热系统的调控精度和响应速度,实现供热过程的动态监控、预测和优化,符合能源结构转型和“双碳”战略目标。
- 数字孪生技术架构:
- 供热设备层:涵盖供热系统的各类设备及其操作状态,包括锅炉、热交换器、泵阀等。
- 监测控制层:负责对供热设备状态的实时监测和数据采集,包括温度、压力、流量等关键参数。
- 智慧决策层:基于实时数据和模型分析结果,进行系统状态评估和决策支持,包括故障预测、负荷调整和能源优化。
- 技术背景与目标:
-
供热系统负荷预测及热网温度传输延迟问题
- 动态供需平衡分析模型:
- 系统建模:利用图论理论对供热系统进行结构机理建模,识别供热系统中的关键组件和相互关系。
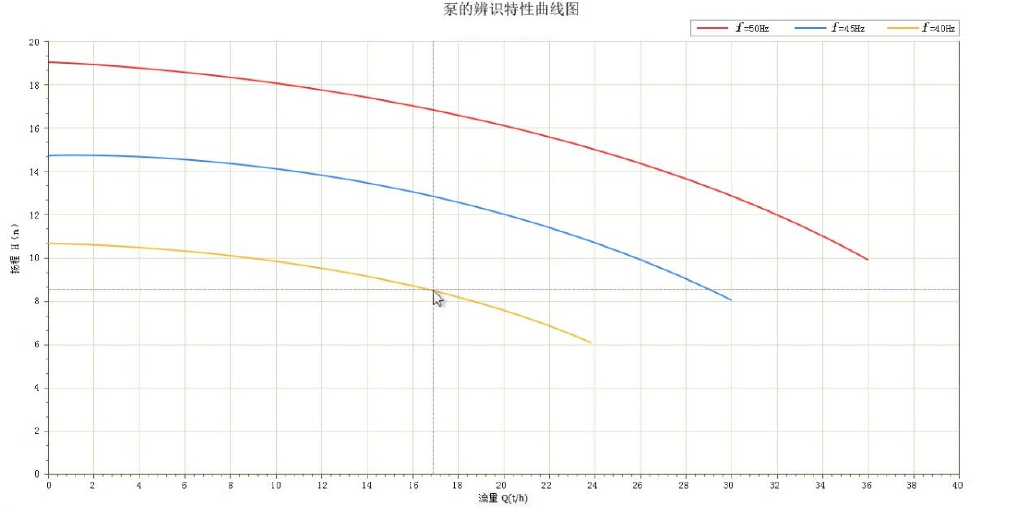
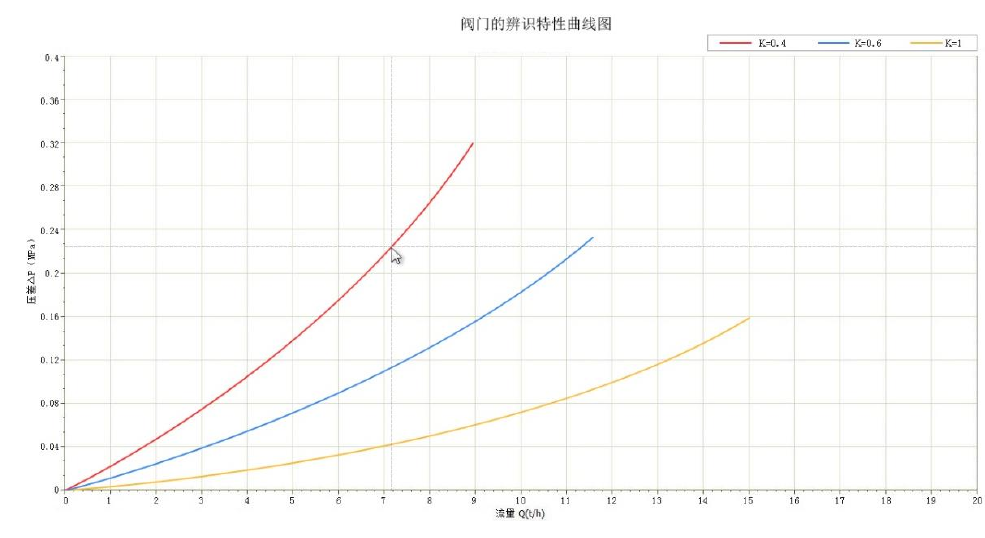
- 参数辨识:通过系统辨识方法修正供热系统管网阻力系数及泵阀特性,提高模型的准确性。
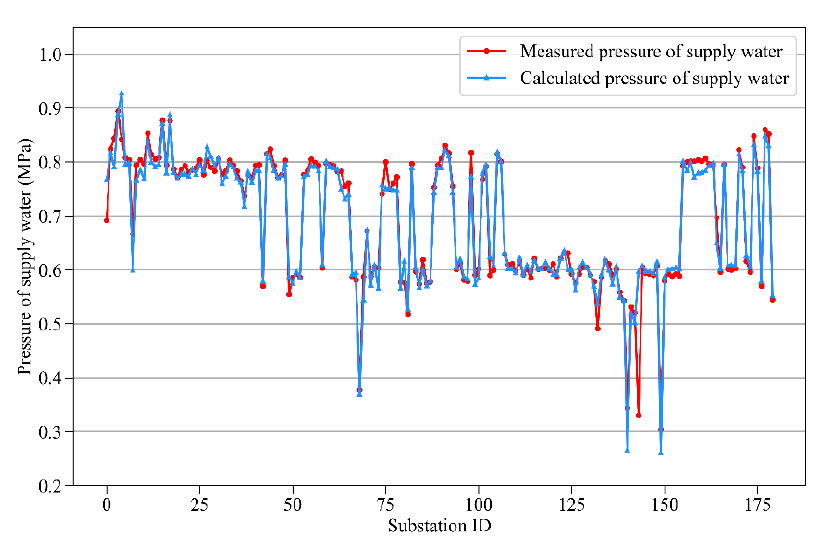
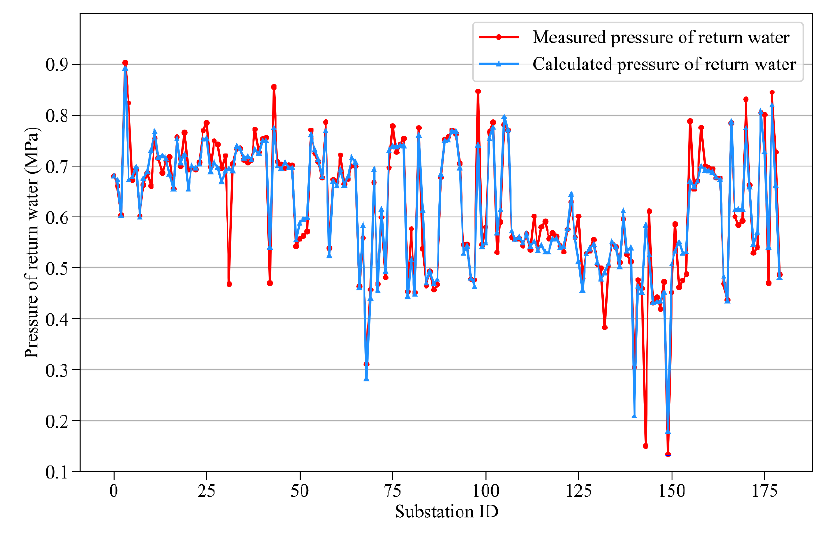
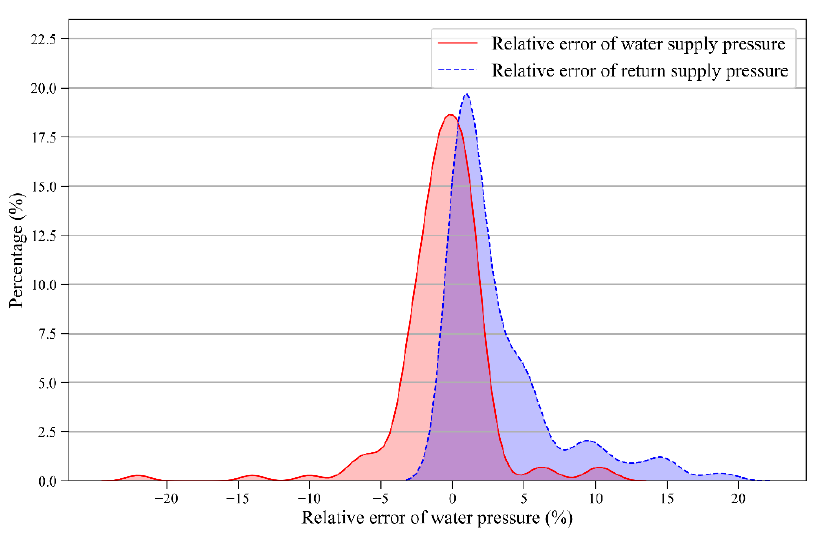
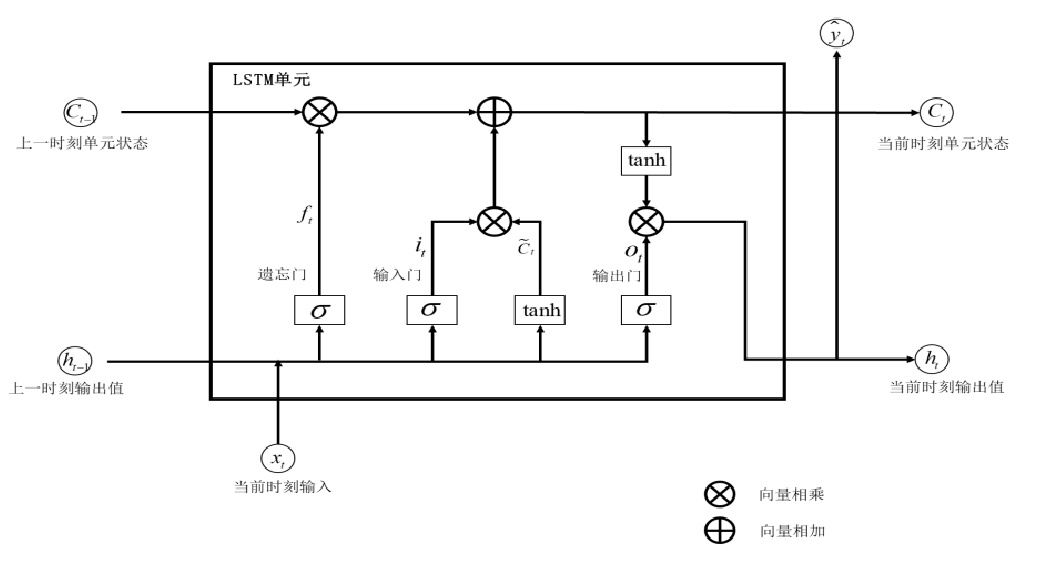
- 热力站负荷预测:使用长短期记忆网络(LSTM)算法预测热力站的热负荷,并结合滑动时间窗口和均值计算方法预测温度延迟响应时间。
- 基于数字孪生的预测性调控流程:
- 热力站运行工况预测模型:结合室温监测数据及温度传输延迟特性,建立准确的供热系统运行状态预测模型。
- 动态供需平衡分析:考虑室温与目标室温之间的偏差,建立衍生工况模型,扩展热力站负荷预测模型的样本空间,实现精准的热负荷预测和动态平衡分析。
- 动态供需平衡分析模型:
-
实时优化调度方法
- 模型预测控制(MPC)框架:
- 优化调度框架:基于数字孪生模型,建立供热系统的实时优化调度框架,包括实时数据采集、模型预测和优化调度。
- 实时优化模型:在供热系统的实时优化调度中,传统的数值求解方法存在局限性,因此引入深度强化学习方法,优化热负荷分配和调控策略。
- 深度强化学习应用:
- 智能负荷分配:采用深度强化学习算法对热力站负荷进行智能优化,提升热负荷的分配效率和系统的整体性能。
- 模型预测控制流程:在实时优化调度的基础上,结合实际供热系统的特点,提出基于模型预测控制的实时优化调度流程,实现供热系统的按需精准调控。
- 模型预测控制(MPC)框架:
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
data = pd.read_csv('heating_system_data.csv') # 假设的数据文件
X = data[['Steam_Temp', 'Wall_Temp', 'Outlet_Pressure']]
y_load = data['Heat_Load']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_load, test_size=0.3, random_state=42)
# 构建LSTM模型
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(X_train.shape[1],)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.2)
# 预测热负荷
y_pred = model.predict(X_test)
# 计算预测误差
mse = mean_squared_error(y_test, y_pred)
print(f"预测均方误差: {mse}")
# 深度强化学习框架示例
# 伪代码示例,实际应用中需根据具体需求设计强化学习算法
import gym
from stable_baselines3 import PPO
# 创建强化学习环境
env = gym.make('HeatingSystem-v0')
# 创建PPO模型
model_rl = PPO('MlpPolicy', env, verbose=1)
# 训练强化学习模型
model_rl.learn(total_timesteps=10000)
# 使用模型进行实时优化
obs = env.reset()
for _ in range(1000):
action, _states = model_rl.predict(obs)
obs, rewards, done, info = env.step(action)
if done:
obs = env.reset()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











