







✅博主简介:本人擅长数据处理、建模仿真、程序设计、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。
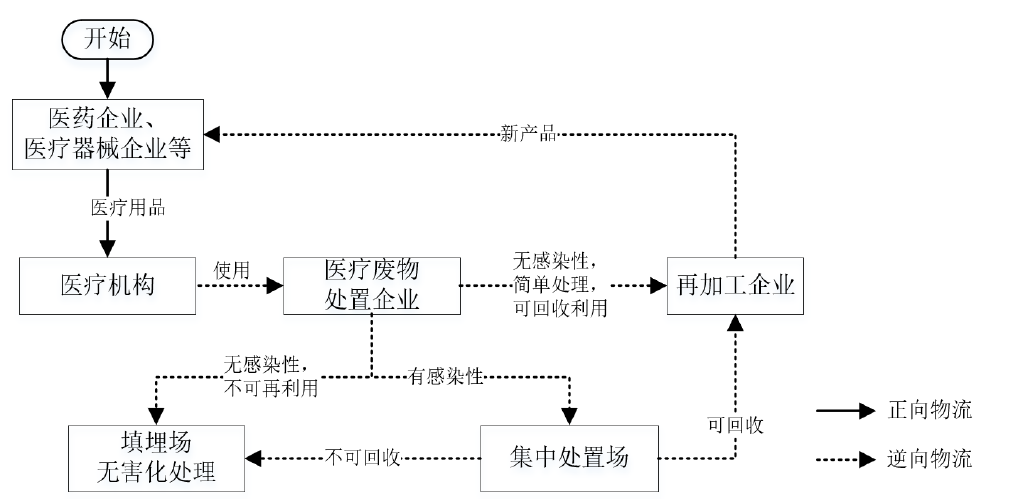
随着城市化进程的加快,医疗废弃物的产生量逐年增加,如何高效、规范地进行医疗废弃物的回收和处置已成为亟待解决的问题。在对我国城市医疗废弃物回收处置现状进行调研和分析后,发现当前存在以下五个主要问题:
- 回收网络不完善:许多地区缺乏系统性的回收网络,导致医疗废弃物的回收效率低下。
- 标准化流程缺失:不同医疗机构在废弃物分类和处置流程上缺乏统一标准,影响了回收质量。
- 运输路径不优化:医疗废弃物的运输路径设计不合理,增加了运输成本和时间。
- 信息共享不足:医疗机构之间信息共享较少,影响了资源的有效利用。
- 监管力度不足:对医疗废弃物的监管措施不够严格,容易导致非法处置现象的发生。
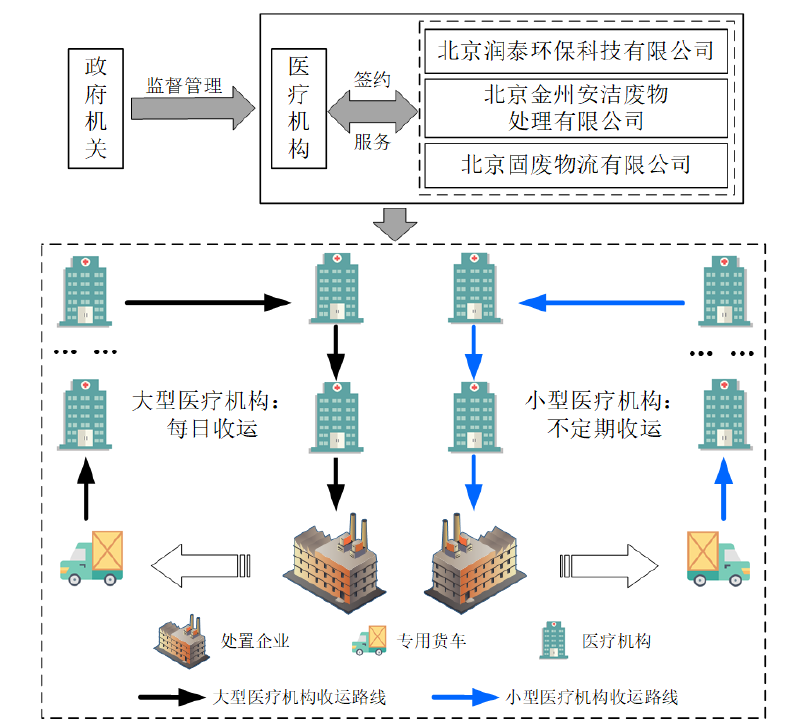
为改善以上问题,本文提出了多项改进方向,并设计出一套适应性强的标准化处置流程,以期在全国范围内推广应用。以北京市为例,重新设计了两种问题场景下的医疗废弃物逆向物流回收网络,并明确了回收网络中各级节点的功能。
2. 回收节点选址与车辆路径问题模型
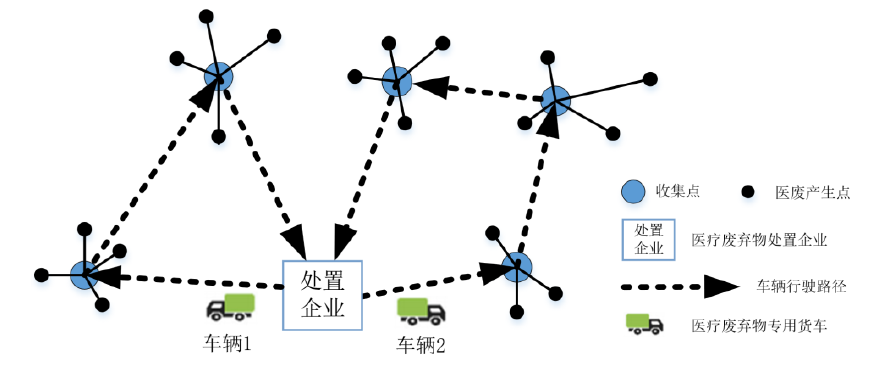
针对医疗废弃物的回收需求,本文建立了两种模型来解决回收节点选址和运输路径优化问题。
2.1 单处置企业回收网络模型
在单处置企业的场景下,构建了带容量与时间窗约束的车辆路径问题(CVRPTW)。该模型的关键要素包括:
- 回收节点选址问题:确定最优的回收节点,以最小化总运输成本。
- 车辆路径规划:优化配送车辆的行驶路径,满足时间窗和载重的限制。
通过数学模型的构建,可以明确各个节点的功能和作用,为后续的运输优化提供理论基础。
2.2 多处置企业回收网络模型
在多家处置企业的场景下,建立了带时间窗的多配送中心车辆路径问题(MDVRPTW)。该模型不仅考虑了多个处置中心的布局,还涵盖了每个配送中心的运输任务。
- 多配送中心的布局:确定多个处置企业的最佳选址,提高整体回收效率。
- 路径优化:设计各配送中心之间的最佳运输路径,以降低运输成本和时间。
在求解这两个模型时,本文采用了遗传算法和改进的蚁群算法相结合的策略,以提高求解效率。
3. 算法设计与求解
针对上述模型,本文分别设计了遗传算法和结合局部搜索策略的改进蚁群算法。这些算法的设计目标是提高求解效率和结果的准确性。
3.1 遗传算法
遗传算法通过模拟自然选择和遗传过程,对回收节点选址和路径问题进行求解。其主要步骤包括:
- 种群初始化:随机生成初始解集,以保证解的多样性。
- 适应度评估:通过计算总成本来评估每个解的优劣。
- 选择操作:采用轮盘赌或锦标赛选择等方法选择适应度高的个体进行繁殖。
- 交叉与变异:通过交叉和变异操作生成新的解,以增加解的多样性。
- 迭代更新:重复进行适应度评估和选择、交叉、变异,直至达到收敛条件。
3.2 改进的蚁群算法
改进的蚁群算法引入了局部搜索策略,以增强搜索效率。其核心包括:
- 信息素更新:根据路径的优劣动态调整信息素浓度,引导蚂蚁选择更优路径。
- 启发式规则:结合距离、时间窗等信息,优化蚂蚁的决策过程。
- 局部搜索:在每次蚂蚁完成路径规划后,进行局部优化,提高路径质量。
通过对Solomon Benchmark标准算例的测试,验证了所设计算法的有效性与可靠性。
4. 数据收集与实例分析
为实现以上模型与算法的有效应用,本文全面采集了北京市西城区的医疗机构相关数据。相比以往研究仅收集大型医院数据,本文涵盖了443个大、中、小、微型医疗机构的详细信息,数据规模更大,具有更强的实际指导意义。
在数据收集过程中,重点关注以下几个方面:
- 医疗机构的地理位置:精确定位各医疗机构的位置,以便于后续的回收节点选址。
- 医疗废弃物产生量:根据各医疗机构的业务规模与类别,估算其医疗废弃物的产生量。
- 处置需求:分析各医疗机构的废弃物处理需求,为运输路径规划提供依据。
利用这些数据,对回收节点选址问题、CVRPTW和MDVRPTW模型进行实例验证,得出了一套可操作的方案。
5. 结果与讨论
通过对北京市西城区医疗机构的回收节点选址与路径规划的实例分析,本文得到了以下几项结果:
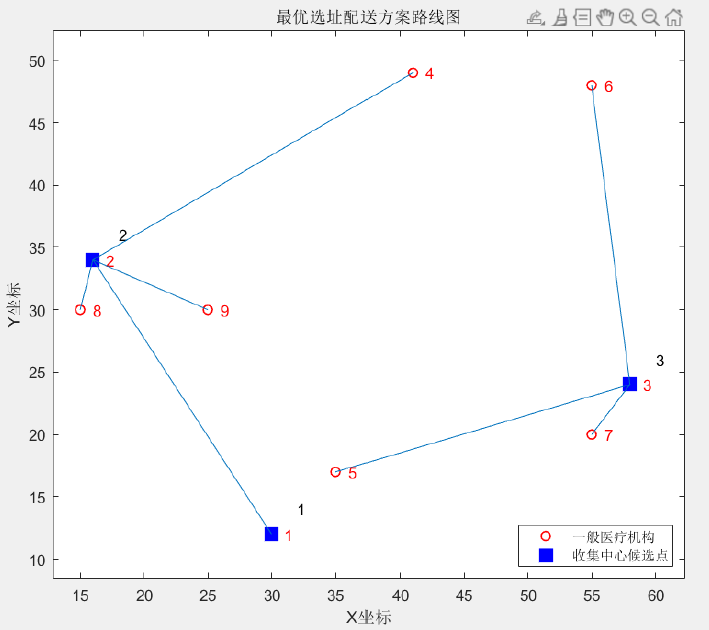
- 回收节点选址方案:针对西城区医疗机构的分布特点,提出了合理的充电站与回收节点选址方案,以优化资源配置和提高回收效率。
- 运输路径规划方案:设计了针对不同医疗机构的运输路径,最大限度地减少了运输成本和时间,确保及时满足医疗废弃物的回收需求。
- 可操作性与灵活性:根据实际情况的变化,提供了灵活的路径调整建议,以应对动态环境下的需求变化。
function medical_waste_collection
% 参数设置
numNodes = 10; % 医疗机构数量
numVehicles = 3; % 车辆数量
maxCapacity = 50; % 车辆最大载重
timeWindows = [0, 120; 30, 150; 60, 180; 90, 210]; % 各节点的时间窗
demands = randi([1, 15], numNodes, 1); % 随机生成需求量
% 随机生成节点位置
locations = rand(numNodes, 2) * 100;
% 初始化种群
population = initializePopulation(numNodes, numVehicles);
% 遗传算法主循环
for iter = 1:100
% 适应度计算
fitness = evaluateFitness(population, locations, demands, maxCapacity, timeWindows);
% 选择操作
selected = selection(population, fitness);
% 交叉与变异
offspring = crossover(selected);
offspring = mutation(offspring);
% 更新种群
population = [selected; offspring];
population = unique(population, 'rows'); % 保持唯一性
end
% 最优解输出
bestSolution = population(1, :);
fprintf('Optimal Collection Nodes: %s\n', mat2str(bestSolution));
end
function population = initializePopulation(numNodes, numVehicles)
% 随机初始化种群
population = randi([1, numNodes], 10, numVehicles); % 10个个体
end
function fitness = evaluateFitness(population, locations, demands, maxCapacity, timeWindows)
% 计算适应度
fitness = zeros(size(population, 1), 1);
for i = 1:size(population, 1)
% 计算成本
totalCost = calculateTotalCost(population(i, :), locations, demands, maxCapacity, timeWindows);
fitness(i) = 1 / (1 + totalCost); % 适应度越高越好
end
end
function totalCost = calculateTotalCost(nodeIndices, locations, demands, maxCapacity, timeWindows)
% 计算总成本
totalCost = 0;
for idx = nodeIndices
distance = pdist2(locations(idx, :), locations); % 计算距离
totalCost = totalCost + sum(distance) + sum(demands(idx)); % 假设按距离和需求计算成本
end
end
function selected = selection(population, fitness)
% 选择操作
probabilities = fitness / sum(fitness);
selectedIndices = randsample(size(population, 1), size(population, 1), true, probabilities);
selected = population(selectedIndices, :);
end
function offspring = crossover(selected)
% 交叉操作
offspring = [];
for i = 1:2:size(selected, 1)-1
parent1 = selected(i, :);
parent2 = selected(i+1, :);
% 简单交叉操作
child = unique([parent1(1:end/2), parent2(end/2+1:end)]);
offspring = [offspring; child];
end
end
function mutated = mutation(offspring)
% 变异操作
mutated = offspring;
for i = 1:size(offspring, 1)
if rand < 0.1 % 10%概率变异
mutationPoint = randi([1, size(offspring, 2)]);
mutated(i, mutationPoint) = randi([1, size(offspring, 2)]); % 随机变更一个节点
end
end
end



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











