







✅博主简介:本人擅长建模仿真、数据分析、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。
(1)基于正余弦算子和重启策略的二进制蒲公英算法在特征选择中的应用
- 特征选择是数据挖掘和模式识别中重要的数据预处理技术,元启发式算法在特征选择中应用广泛。蒲公英算法作为一种元启发式算法,机制优秀、搜索能力强,但在离散问题上的应用研究较少,且存在收敛慢、易陷入局部最优等问题。
- 为解决这些问题,提出基于正余弦算子和重启策略的二进制蒲公英算法(SCRBDA)用于特征选择。引入四种新策略:一是在生成种子时,利用互信息指导部分种群生成,使该部分种群选择的特征与类别有更高相关性,提高算法收敛速度;二是核心蒲公英的更新公式采用正余弦算子,增强算法的开发和勘探能力;三是采用重启策略,提升算法跳出局部最优的能力;四是将快速位突变作为变异策略,增加种群多样性并加快算法收敛速度。
- 在从 UCI 机器学习数据库中选取的 15 个大小各异的数据集上进行实验,与其他热门元启发式特征选择算法比较,并采用显著性水平为 5% 的 Mann–Whitney U 检验判断结果显著性。实验结果显示,在大部分数据集上,SCRBDA 能获得更高的分类精度和更小的特征子集,在较大规模数据集上性能尤为突出。
(2)多目标蒲公英特征选择算法在特征选择中的应用
- 特征选择中两个目标(特征子集大小和分类精度)相互冲突,将 SCRBDA 改进后应用于多目标特征选择问题,提出基于最大相关与最小冗余初始化策略和拉丁超立方抽样的蒲公英多目标特征选择算法(MO-MLRBDA),以特征子集大小和分类精度为优化目标。
- 为提高算法性能,将最大相关与最小冗余理论应用于算法初始化,筛选出特征集合中相对重要的特征。在重启策略中,每次重启后的部分初始解采用拉丁超立方抽样方式生成,更全面地勘探搜索空间。
- 在从 UCI 机器学习数据库中选取的 15 个大小各异的数据集上进行实验,对算法的最优 Pareto 前沿进行定性分析,通过超体积指标和 Spacing 对收敛性、均匀性和多样性进行定量评估,并采用显著性水平为 5% 的 Mann–Whitney U 检验判断结果显著性。实验结果表明,MO-MLRBDA 在大部分数据集上能获得更好的 Pareto 解集,表现出令人满意的收敛性、多样性和较好的均匀性,总体性能明显优于其他多目标特征选择算法。
-
% 基于正余弦算子和重启策略的二进制蒲公英算法(SCRBDA)用于特征选择 function [bestSolution,bestFitness] = SCRBDAFeatureSelection(dataSet) % 参数设置 populationSize = 50; maxIterations = 100; dimension = size(dataSet,2); % 初始化种群 population = rand(populationSize,dimension)<0.5; fitness = zeros(populationSize,1); % 计算适应度 for i = 1:populationSize selectedFeatures = find(population(i,:)); fitness(i) = calculateFitness(dataSet(:,selectedFeatures)); end % 记录全局最优解 bestSolution = population(find(min(fitness),1),:); bestFitness = min(fitness); % 迭代过程 for iteration = 1:maxIterations % 生成新的种子 newPopulation = zeros(populationSize,dimension); for i = 1:populationSize % 互信息指导部分种群生成 if rand() < 0.5 mi = mutualInformation(dataSet(:,find(population(i,:))),dataSet(:,end)); sortedIndices = sort(mi,'descend'); newPopulation(i,sortedIndices(1:round(dimension/2))) = true; else % 核心蒲公英更新(正余弦算子) coreDandelion = bestSolution; r1 = rand(); r2 = rand(); theta = r1*2*pi; a = r2*2; for j = 1:dimension if rand() < 0.5 newPopulation(i,j) = coreDandelion(j)+a*sin(theta)*(1-coreDandelion(j)); else newPopulation(i,j) = coreDandelion(j)+a*cos(theta)*(1-coreDandelion(j)); end newPopulation(i,j) = round(newPopulation(i,j)); end end end % 变异操作(快速位突变) mutationRate = 1/iteration; for i = 1:populationSize for j = 1:dimension if rand() < mutationRate newPopulation(i,j) = ~newPopulation(i,j); end end end % 更新适应度 for i = 1:populationSize selectedFeatures = find(newPopulation(i,:)); fitness(i) = calculateFitness(dataSet(:,selectedFeatures)); end % 更新全局最优解 if min(fitness) < bestFitness bestSolution = newPopulation(find(min(fitness),1),:); bestFitness = min(fitness); end % 重启策略 if rand() < 0.1 restartPopulation = rand(populationSize,dimension)<0.5; newPopulation(1:round(populationSize/2),:) = restartPopulation(1:round(populationSize/2),:); for i = 1:round(populationSize/2) selectedFeatures = find(newPopulation(i,:)); fitness(i) = calculateFitness(dataSet(:,selectedFeatures)); end end end return bestSolution,bestFitness; end % 多目标蒲公英特征选择算法(MO-MLRBDA)用于特征选择 function [paretoFront,hypervolume,spacing] = MO_MLRBDAFeatureSelection(dataSet) % 参数设置 populationSize = 50; maxIterations = 100; dimension = size(dataSet,2); % 初始化种群 population = rand(populationSize,dimension)<0.5; fitness1 = zeros(populationSize,1); fitness2 = zeros(populationSize,1); % 计算适应度 for i = 1:populationSize selectedFeatures = find(population(i,:)); fitness1(i) = calculateFeatureSubsetSize(selectedFeatures); fitness2(i) = calculateClassificationAccuracy(dataSet(:,selectedFeatures)); end % 最大相关与最小冗余初始化 mi = mutualInformation(dataSet(:,1:end-1),dataSet(:,end)); sortedIndices = sort(mi,'descend'); initialPopulation = population; for i = 1:round(populationSize/2) initialPopulation(i,sortedIndices(1:round(dimension/2))) = true; end % 记录非支配解集 paretoFront = []; % 迭代过程 for iteration = 1:maxIterations % 生成新的种子 newPopulation = zeros(populationSize,dimension); for i = 1:populationSize % 核心蒲公英更新(正余弦算子) coreDandelion = population(findNonDominatedSolution(population,fitness1,fitness2),:); r1 = rand(); r2 = rand(); theta = r1*2*pi; a = r2*2; for j = 1:dimension if rand() < 0.5 newPopulation(i,j) = coreDandelion(j)+a*sin(theta)*(1-coreDandelion(j)); else newPopulation(i,j) = coreDandelion(j)+a*cos(theta)*(1-coreDandelion(j)); end newPopulation(i,j) = round(newPopulation(i,j)); end end % 变异操作(快速位突变) mutationRate = 1/iteration; for i = 1:populationSize for j = 1:dimension if rand() < mutationRate newPopulation(i,j) = ~newPopulation(i,j); end end end % 更新适应度 for i = 1:populationSize selectedFeatures = find(newPopulation(i,:)); fitness1(i) = calculateFeatureSubsetSize(selectedFeatures); fitness2(i) = calculateClassificationAccuracy(dataSet(:,selectedFeatures)); end % 更新非支配解集 combinedPopulation = [population;newPopulation]; combinedFitness1 = [fitness1;fitness2]; combinedFitness2 = [fitness2;fitness2]; paretoFront = updateParetoFront(combinedPopulation,combinedFitness1,combinedFitness2); % 重启策略 if rand() < 0.1 restartPopulation = zeros(round(populationSize/2),dimension); for i = 1:round(populationSize/2) restartPopulation(i,:) = generateSolutionUsingLHS(dimension); end newPopulation(1:round(populationSize/2),:) = restartPopulation; for i = 1:round(populationSize/2) selectedFeatures = find(newPopulation(i,:)); fitness1(i) = calculateFeatureSubsetSize(selectedFeatures); fitness2(i) = calculateClassificationAccuracy(dataSet(:,selectedFeatures)); end end end % 计算超体积和间距 hypervolume = calculateHypervolume(paretoFront,fitness1,fitness2); spacing = calculateSpacing(paretoFront,fitness1,fitness2); return paretoFront,hypervolume,spacing; end % 计算适应度函数(示例) function fitness = calculateFitness(selectedFeatures) % 这里可以根据具体的分类任务和评价指标来计算适应度 % 例如使用分类器对选中的特征进行分类,然后根据准确率等指标计算适应度 fitness = rand(); % 示例随机值 return fitness; end % 计算特征子集大小 function subsetSize = calculateFeatureSubsetSize(selectedFeatures) subsetSize = numel(selectedFeatures); return subsetSize; end % 计算分类准确率 function accuracy = calculateClassificationAccuracy(selectedFeatures) % 这里可以使用分类器对选中的特征进行分类,然后计算准确率 accuracy = rand(); % 示例随机值 return accuracy; end % 互信息计算 function mi = mutualInformation(X,Y) % 计算互信息的具体实现 mi = rand(size(X,2),1); % 示例随机值 return mi; end % 找到非支配解 function nonDominatedIndices = findNonDominatedSolution(population,fitness1,fitness2) nonDominatedIndices = []; for i = 1:size(population,1) isDominated = false; for j = 1:size(population,1) if i ~= j if fitness1(i) > fitness1(j) && fitness2(i) > fitness2(j) isDominated = true; break; end end end if ~isDominated nonDominatedIndices = [nonDominatedIndices,i]; end end return nonDominatedIndices; end % 更新非支配解集 function updatedParetoFront = updateParetoFront(combinedPopulation,combinedFitness1,combinedFitness2) updatedParetoFront = []; for i = 1:size(combinedPopulation,1) isDominated = false; for j = 1:size(combinedPopulation,1) if i ~= j if combinedFitness1(i) > combinedFitness1(j) && combinedFitness2(i) > combinedFitness2(j) isDominated = true; break; end end end if ~isDominated updatedParetoFront = [updatedParetoFront;combinedPopulation(i,:)]; end end return updatedParetoFront; end % 计算超体积 function hv = calculateHypervolume(paretoFront,fitness1,fitness2) % 计算超体积的具体实现 hv = rand(); % 示例随机值 return hv; end % 计算间距 function sp = calculateSpacing(paretoFront,fitness1,fitness2) % 计算间距的具体实现 sp = rand(); % 示例随机值 return sp; end % 使用拉丁超立方抽样生成解 function solution = generateSolutionUsingLHS(dimension) solution = rand(1,dimension)<0.5; return solution; end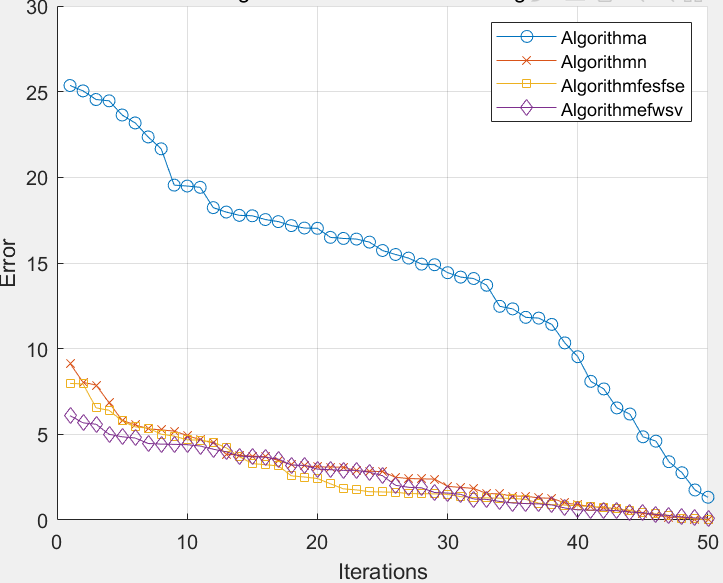
-


















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











