







一、强化学习(Reinforcement Learning)
1. 基本概念
强化学习(reinforcement learning),又称再励学习、评价学习,是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。
用于描述和解决智能体(agent)在环境交互过程中通过学习策略以达到回报最大化或实现特定目标的问题。

侧重在线学习并试图在探索-利用(exploration-exploitation)中保持平衡。
强化学习不要求预先给定任何数据,而是通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数。
2. 简介:
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为
目标是使智能体获得最大的奖赏
强化学习不同于连接主义学习中的监督学习,主要表现在教师信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。
由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
3. 基本概念
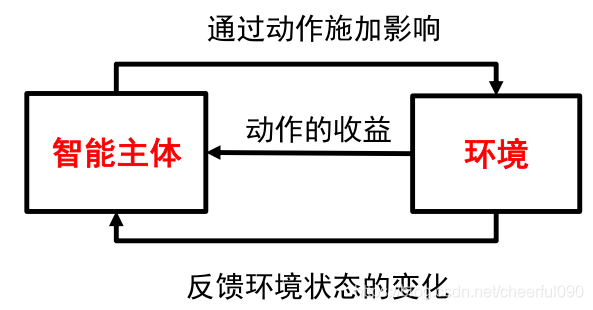
智能主体(agent)
- 按照某种策略(policy),根据当前的状态(state)选择合适的动作(action)
- 状态是指智能主体对环境的一种解释
- 动作反映了智能主体对环境主观能动的影响,动作带来的收益称为奖励(reward)
- 智能主体可能知道也可能不知道环境变化的规律
环境(environment)
- 系统中智能主题以外的部分
- 向智能主体反馈状态和奖励
- 按照一定的规律发生变化
4.特点
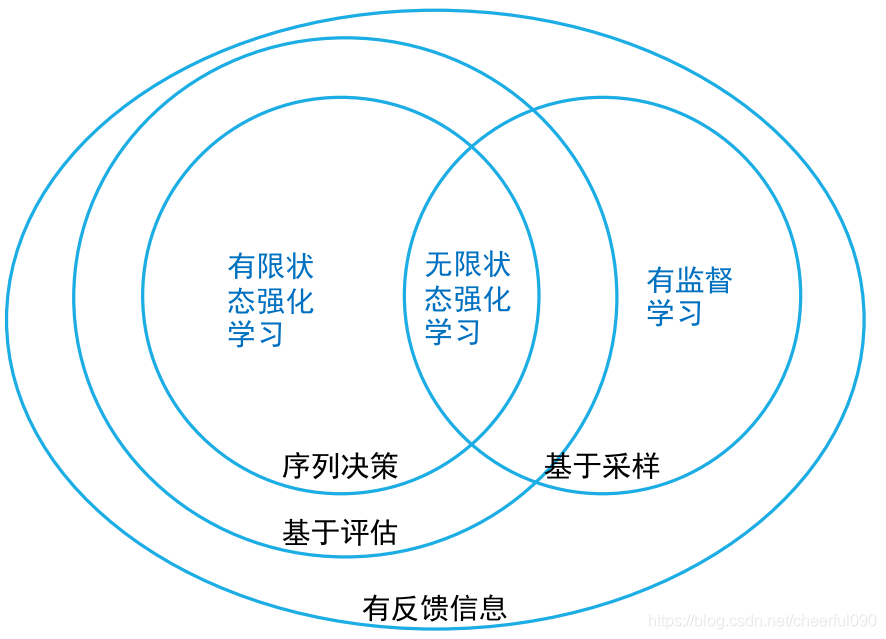
| 有监督学习 | 无监督学习 | 强化学习 | |
|---|---|---|---|
| 学习依据 | 基于监督信息 | 基于对数据结构的假设 | 基于评估(evaluative) |
| 数据过程 | 一次性给定 | 一次性给定 | 在交互中产生(interactive) |
| 决策过程 | 单步(one-hot) | 无 | 序列(sequential ) |
| 学习目标 | 样本到语义标签的映射 | 数据的分布模式 | 选择能够获取最大收益的状态到动作的映射 |
强化学习的特点
- 基于评估:强化学习利用环境评估当前策略,以此为依据进行优化
- 交互性:强化学习的数据在与环境的交互产生
- 序列决策过程:智能主体在与环境的交互中需要一系列的决策,这些决策往往是前后关联的
- 注:现实中常见的强化学习问题往往还有奖励滞后,基于采样的评估等特点
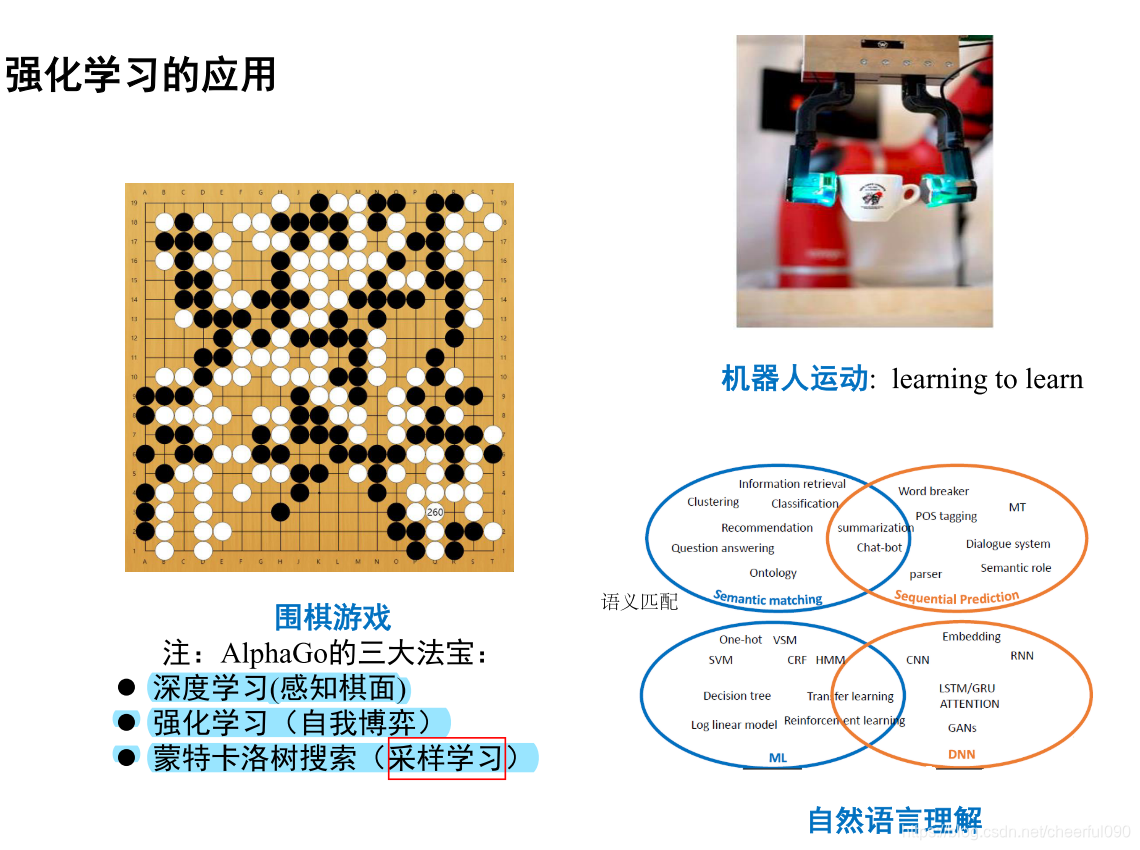
应用
二、遗憾最小化算法(博弈)
1、概述
反事实遗憾算法是一种自我演绎的AI模型。本质是两个AI智能体互相对抗,从头开始学习游戏。事实上在多数情况下,这是一个智能体进行自我对抗,所以它的学习速度会翻倍(重点注意,尽管它本身是和自己玩,但实际上它并没有足够聪明到站在对手的位置理解它上一步的行为。)
与许多最近在AI研究中的重大突破(如AlphaGo)不同,CFR不依赖于神经网络计算概率或特定举措的价值。取代通过自我对局数百万甚至上亿的的方法,它从总结每个操作对特定位置加以考虑的遗憾总量着手。
这个算法令人兴奋的是,随着游戏的进行它将越来越接近游戏的最佳策略,即纳什均衡。它已经在许多游戏和领域证明了自己,最有趣的是扑克特别是无限德州扑克。这是我们目前拥有的最好的扑克AI算法。
2、遗憾匹配
遗憾匹配(RM)是一种寻找最大限度地减少对游戏每个步骤决策遗憾的算法。顾名思义,它从过去的行为学习告知未来决策,通过赞同它后悔以前没有采取的行为。
在这个模式中,既有积极的遗憾和消极的遗憾。当消极遗憾被你定义成你期望的情况:在特别得情况下采取特别行动的遗憾。这意味着如果在这种情况下没有选择这个行为,智能体会做得更好。
积极的遗憾也定义成你期望的: 这是一种智能体可以跟踪导致积极结果的行为的机制。(我个人认为应该被称为别的东西,但这无所谓。)
在智能体在自我对抗的每场游戏后,最新游戏中遇到的负面和积极的遗憾都被添加到所有其他盘游戏中的总结里,并且计算出新的策略。
简而言之,通过概率,它偏好采取过去产生的积极成果的行动并避免采取导致负面结果的行为。
与其他的学习机制一样人类也有遗憾学习机制—我们尝试做一些事情,如果失败并引起消极的情绪反应,我们会记下这种遗憾,并让自己再次尝试。以“Scissors-Paper-Rock(SPR)”游戏为例(就是猜拳),如果我们在对手出布的时候出了石头,我们就后悔没有出剪子。
这种模式在零和游戏中向靠拢纳什均衡,对于那些不熟悉博弈论的人来说,游戏中每个智能体的赢或输完全可以由其他智能体的赢或输来平衡。例如,剪刀,石头,布,是零和游戏。当你打败你的对手时,你赢了+1,他们输了-1,和为零。














 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









