







论文题目:”Killing Two Birds with One Stone: Efficient and Robust Training of Face Recognition CNNs by Partial FC“ -CVPR 2022
代码地址:https://arxiv.org/pdf/2203.15565.pdf
代码地址:https://github.com/deepinsight/insightface/tree/master/recognition/arcface_torch
1.背景
分布式训练的问题:
数据并行:将训练数据划分给每台机器,每个结点拥有完整的模型,然后将每个结点反向传播得到的梯度进行聚合,将聚合后的梯度再分发给各个结点更新参数,缺陷是需要在每个结点间传播梯度信息,因此通信开销会非常大。
模型并行:在人脸识别的场景下,假如 FC 层权重为 W ,d 是特征向量的维度,C 是人脸类别数量,那么其实 W 的第 i 列可以视作第 i 类的类中心。模型并行是将 W 按类别划分给各个结点,假如有 k 个结点,将 C 个类中心划分给每个结点,每个结点拥有 C/k 个类中心。那么需要计算样本的softmax loss时,将每个结点的样本特征先进行all_gather(即将每个结点的所有样本特征汇聚在一起再分发给所有结点)操作,这样每个结点就拥有所有样本特征,然后每个结点计算样本与其拥有的类别中心logit,然后再求指数,即可得到softmax的分母部分和,再对这个部分和进行all_reduce(将每个结点的某个tensor聚合在一起计算一个新的tensor再分配给各个结点),这样每个结点就拥有的完整的softmax的分母,即可计算每个样本的softmax loss。然后因为特征的梯度牵涉到了每个类中心,因此还需要将关于特征的梯度进行all_reduce,然后梯度在各自结点反向传播。这样需要通信的就是一个batch的特征+分母的部分和+特征的梯度。当C 增大时,可以通过增加结点数量 k 保持 C/k 恒定,但是每个结点由于需要保存所有样本,需要存储的logit的数量是 Nk * C/k > = N * C , N 是batch size的大小,而 C 往往是十万、百万的量级,因此随着 C 的增大,单个结点的显存总会捉襟见肘。
数据的问题:
长尾分布(long-taied distribution):即类别数量不平衡,少数类别(称为head class)拥有大部分样本,大多数类别(称为tail class)只有少数样本。这样优化时会更关注负类,tail class的类中心会被远离负类中心,偏离它所代表的类。
类间冲突(inter-class conflict):同一个人被分到了不同类里,例如某人既有一张图片label是0类,也有另一张图片label是1类。这样优化时肯定会发生冲突。
–SST [11] and DCQ [21] directly abandon the FC layer and employ a momentum-updated network to produce class weights. However, the negative class number is constrained to past several hundred steps and two networks need to be maintained in the GPU.
2.方法
既然logits的数量是 N*C ,作者提出的解决单个结点显存问题的方法也很简单,减少 C —— 随机采样类别中心,称为Partial FC。具体来说,先考虑只有单个结点的情况,每次迭代会随机采样 N 个样本(batch),那么只保留这 N 个样本对应的类别中心(称为正类别中心),然后随机采样负类别中心,再计算softmax loss;而对于模型并行的多结点的情况,首先各个结点交换batch样本的信息,保留所有正类别中心,例如第零个结点的数据的类别有1,而类别中心是1、2、3、4,而第一个结点数据的类别是2,那么第零个结点应该保留1、2这两个类别中心,然后再随机采样负类别中心。通过PFC,将减少空间开销,加速训练,同时模型性能也没有显著变化,并且也能改善长尾分布与类间冲突的问题。
softmax loss(cosface、arcface等形式与其基本相同):
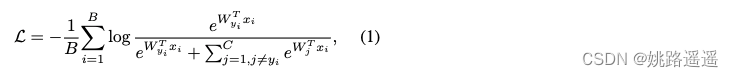
loss关于特征向量 xi 的导数(希望 xi 接近正类别中心W+):
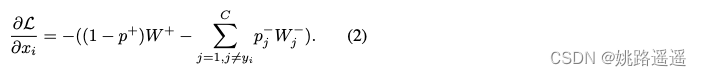
类别中心 Wj 更新公式(希望Wj接近正样本):
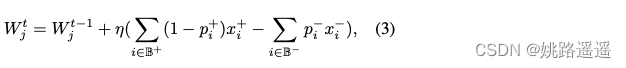
softmax loss 缺点:
1)The first limitation is the gradient confusion under inter-class conflict. (第一个局限是类间冲突下的梯度混淆)
2)The second limitation is that centers of tail classes undergo too many passive updates. (第二个局限是尾部类的中心经历了太多的被动更新)
3)The third limitation is that the storage and calculation of the FC layer can easily exceed current GPU
capabilities.(第三个局限是FC层的存储和计算很容易超过当前GPU的能力)
使用PFC后,公式(2)变为公式(4):
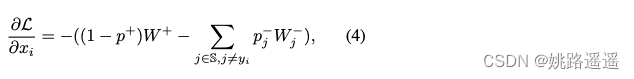
–为什么PFC能缓解长尾分布问题?
如果数据存在长尾分布问题,那么考虑公式(3),对于tail class,正样本数量会非常少甚至为0,因此对应的类别中心 Wj 只会远离负样本,而很难接近正样本,那么长此以往就无法表征正类别中心了。应用了FPC之后,由于每次迭代随机采样负类别中心,那么tail class对应的类别中心被更新的频率也降低了,缓解了上述问题。–为什么PFC能缓解类间冲突问题?
如果发生类间冲突,那么在(2)中负类中心 Wj 可能也能表征正类别中心,(3)中 xi 实际上可能是正样本,那么优化时肯定会发生异常,称为"gradient confusion"。使用了PFC后,概率变小了,(2)和(3)中冲突的负类别中心和负样本被选择的概率就小了,那么类间冲突的问题也能得到缓解。还有一点是应用了PFC能够过滤掉冲突的负类中心。
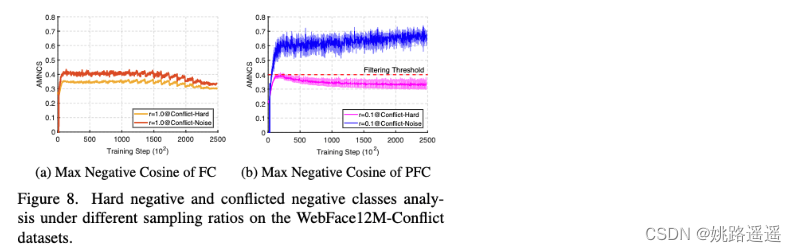
Conflict-Hard指样本与困难负类中心的平均余弦相似度,conflict-Noise指样本与冲突类别中心的余弦相似度,(a)是没有经过负类别中心随机采样的结果,(b)是采样率为 r =0.1 时的实验结果,可以看到此时它们之间有个明显的gap,因此设定合适的阈值就可以过滤掉冲突的负类别中心(文中取0.4)。
模型并行+PFC流程

1.每个结点拥有部分类别中心,如图中每个CPU下拥有14个类别中心。
2.在一次迭代中,每个结点的样本的embedding进行聚合,并分发给各个结点,此时每个结点拥有该次迭代的所有样本的embedding。
3.每个结点将所有样本对应的正类别中心从CPU复制到GPU中,例如第一个结点具有的正类别中心是深红、浅蓝、橙红、浅红这四种,将它们从CPU-1复制到GPU-1中,剩余的位置随机采样负类别中心(图中的深灰色)。
4.计算每个结点的logits(即 wx ) ,结果即图中的有色网格, (i, j) 处的位置表示第 i 个embedding与第 j 个类别中心的内积结果。
5.根据阈值过滤掉冲突的负类别中心,即图中蓝色的叉叉。
6.聚合各个结点的结果。
3.部分实验结果















 88
88











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









