







论文地址:https://arxiv.org/abs/1503.03832
摘要
尽管有一些研究已经在人脸识别领域取得了重大进展[10,14,15,17],但大规模地实施人脸验证和识别仍然是一个严峻的挑战。在本文中,我们提出了FaceNet系统,它可以将人脸图像映射到欧几里得空间(人脸图像->空间向量),两个空间向量之间的距离远近代表了两张人脸图像的相似程度。只要能生成这个空间映射的关系,使用FaceNet将人脸图像转换为特征向量的技术,像人脸识别、人脸验证、人脸聚类等任务都可以轻松完成。
我们的方法是直接使用一个经过训练的深度卷积网络来直接优化特征向量本身(根据不同的损失函数),而不是像以前的深度学习方法那样,优化中间的瓶颈层。训练时,我们使用三元组损失粗略匹配/不匹配人脸图片,这些人脸图片使用一种新颖的在线三元组挖掘的方法生成。(如果每次都是随机选择三元组,模型虽然可以收敛但达不到最好的效果;如果加入困难样本挖掘,即每次都选择最难分辨的三元组进行训练,模型又不能很好收敛;为此提出每次都选取半难(semi-hard)的数据进行训练,让模型可以在收敛的同时又保持良好的性能。)我们有更高的表现效率:每个人脸使用128字节(每个人脸表示成128维向量)就实现了最先进的人脸识别性能。
在LFW数据集上,实现了最高精度:99.63%。在youtobe数据集上实现了95.12%的精确度。在这两个数据集上,我们的系统的错误率与最好的方法相比降低了30%[15]。
我们还介绍了谐波嵌入和谐波三元组损失的概念,它们描述了彼此兼容并允许直接比较的不同版本的面嵌入(由不同的网络产生)。
1 引言
本文提出了一种统一的方法,可以用在人脸验证,人脸识别,人脸聚类任务中。我们的方法是利用深度卷积神经网络学习将图像映射到欧几里得空间(人脸图像->128维的空间向量)。训练网络使得在空间中,向量的L2距离平方表示了人脸的相似程度:同一个人的不同图像在空间中的距离很小,不同人的图像在空间中的距离很大。
一旦这个空间映射生成,上面提到的三个任务就变得很直接。人脸验证:通过设置两个向量之间距离的阈值,区分是否两张人脸图像是否属于同一个人。人脸识别:使用knn分类器。人脸聚类:使用k-means或agglomerative clustering等。
以前基于深度网络的人脸识别方法是在一个已知的人脸身份的数据集上训练分类层,然后采取卷积层的最后一层作为人脸的向量表示。这种间接方法是低效的:一是我们希望最后一层卷积层的特征表示能够表示一些新面孔,二是这个特征表示的尺寸通常非常大(通常1000维度)。最近的一些工作已经使用PCA降低维度,但这是一种线性变换,可以用一层网络轻松学习到。
相比于传统的方法,FaceNet利用基于LMNN的三元组损失函数来训练,可以直接输出一个压缩后的128维度的特征向量。我们的三元组损失函数包含两张同一个人的图像和一张另外一个不同人的图像(anchor,positive,negative)。损失函数的目标是通过距离区分一对正样本和一个负样本。人脸的图像是紧密裁剪的人脸区域,除了执行缩放和平移外,没有经过2D和3D对齐。
选择使用哪个三元组对于性能非常重要,并且受[1]的启发,我们提出了一种新的在线负样本挖掘策略,可确保网络训练时,持续增加三元组难度。 为了提高聚类的准确性,我们还探索了困难正样本的挖掘技术。
如图1的图像。对于之前的人脸验证系统来说非常困难。但是我们的方法可以很容易处理。

图1. 光照和位姿不变性。姿态和光照是人脸识别中长期存在的问题。该图显示了FaceNet在不同的姿势和光照组合下对相同的面孔和不同的人之间的输出距离。距离0.0表示两张脸是相同的,4.0表示相反的光谱,两种不同的身份。可以看到,阈值为1.1将正确地对每一对进行分类。
本文其余部分的概述如下:在第2节中,我们回顾了这一领域的文献;3.1节定义了三元组的损失,3.2节描述了我们新的三个图像的选择和训练过程;在第3.3节中,我们描述了所使用的模型架构。最后,在第4节和第5节中,我们将展示一些嵌入的定量结果,并从定性的角度探讨一些聚类结果。
2 相关工作
与近期使用深度网络解决问题的方法相同[15,17],我们的方法也是靠纯数据驱动,深度网络直接从人脸图像的像素中学习特征表示。我们使用大量带标记的人脸数据集来获得姿态、光照和其他变化条件的不变性而不是其他工程特征。
在这篇文章中,我们探索两种不同的深度卷积神经网络结构,这两种结构近期在计算机视觉领域取得了很大成功。两者都是深度卷积网络[8,11]。第一个结构是基于ZFNet [22],该模型由多个交错卷积层,非线性激活,局部响应归一化和最大池化层组成。我们额外增加了一些1×1×d卷积层[9]。第二个结构是基于GoogLeNet,该模型获得了2014 ImageNet冠军[16]。该网络使用混合的层,并行运行几个不同的卷积层和池化层,并将它们的输出响应连接起来。 我们发现,这些模型可以将参数数量减少多达20倍,并有可能减少可比性能所需的FLOPS数量。
一些近期人脸验证和识别的工作如下:
[15,17,23]使用了多阶段的复杂系统,将深度卷积网络的输出与PCA相结合以降低维度,并用SVM分类。
[23]Zhenyao等人采用深层网络将脸部“扭曲”成典型的正面视图,然后学习一个CNN对已知身份的脸部进行分类。 对于人脸验证,将深度卷积网络的输出与PCA相结合以降低维度,并用SVM分类。
Taigman等人[17]提出了一种多阶段方法,将人脸对齐到一个通用的3D形状模型。一个经过训练的多类网络可以对超过4000个身份进行人脸识别。作者还试验了一个Siamese network,他们直接优化两个脸部特征之间的L1距离。 他们在LFW上的最佳表现(97.35%)源于三个网络的集成。网络预测的距离结合了非线性的SVM。
Sun等人[14,15]提出了一种紧凑且相对简单的计算网络。他们使用了25个这样的网络,每一个都在不同的人脸patch上操作。作者结合了50个操作(常规和翻转),最终他们在LFW上得到了很好的(99.47%[15])表现。同时使用PCA和联合贝叶斯模型[2],联合贝叶斯模型在嵌入空间中有效对应线性变换的。他们的方法不需要明确的2D/3D对齐。网络的训练结合了分类和验证损失。验证损失类似于我们使用的三元组损失[12,19],因为它最小化了相同身份的面之间的 L 2 L_2 L2距离,并在不同身份的面之间的距离施加了一个边界。主要的区别是只有两个图像进行比较,而三元组的损失导致了相对距离的限制。
我们这里使用的损失函数类似于Wang等人使用[18]对图像进行语义和视觉相似度排序损失函数。
3 方法
FaceNet使用深度卷积网络。我们讨论两种不同的结构:ZFNet [22]和GoogLeNet [16]。网络的细节在3.3部分。
考虑模型的细节,如图2所示。将它看成一个黑盒子,最重要的部分在于整个系统是端到端学习,在最后,使用三元组损失,这直接反映了我们在人脸验证、识别和聚类方面想要达到的目标。也就是说,我们使用 f ( x ) f(x) f(x)把图像x映射到特征空间 R d R^d Rd,计算所有人脸特征向量间的距离平方,这个数值与成像条件无关,同一个人的特征向量间距离小,不同人的特征向量间距离大。
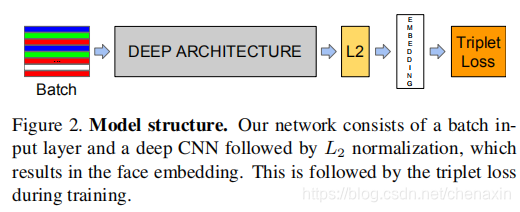
图2.模型结构。我们的网络由一个批处理输入层和一个深度CNN组成,然后进行L2归一化,结果是人脸嵌入。接下来是训练中三联的损失。
虽然我们没有直接与其他loss进行比较,例如在[14]Eq.(2)中使用的正负对的loss,但我们认为三元组loss更适合于人脸验证。其动机是,[14]的损失函数使得同一个人的所有人脸都被映射到特征空间的单一点上。然而,“三元组损失”试图在每对面孔之间建立一个从一个人的脸到所有其他脸的距离。这允许一个人的脸有着一些变化,同时仍然加强了距离,因此对其他身份的区别。
下面的部分描述了这种三元组损失,以及如何有效地大规模学习。
3.1 三元组损失
模型的目的是将图像x映射到d维的欧几里得空间,映射的特征向量为f(x)。此外,训练的时候固定在d维超平面上, ∣ ∣ f ( x ) ∣ ∣ 2 = 1 ||f(x)||_2=1 ∣∣f(x)∣∣2=1,即特征归一化,保证特征不会无限地”远离”。这种损失的灵感来源于是[19]的最近邻分类。在该向量空间内,我们希望保证单个个体的图像 x i a ( a n c h o r ) x_i^a(anchor) xia(anchor)和该个体的其它图像 x i p ( p o s i t i v e ) x_i^p(positive) xip(positive)的距离近,与其他个体的图像 x i n ( n e g a t i v e ) x_i^n(negative) xin(negative)距离远。他们之间的关系如图3。
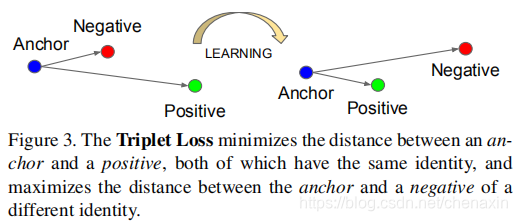
图3.三元组损失使anchor和positive之间的距离最小,两者具有相同的特性,并使anchor和negative之间的距离最大,两者具有不同的特性。
因此,我们有:
∣ ∣ f ( x i a ) − f ( x i p )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









