






传染病趋势预测模型
时间序列预测模型
前言
时间序列的目的:进行预测,根据已有的时间序列数据预测未来。思路是确定已有的时间序列变化模式,并假定这种模式会延续到未来。不考虑事物发展之间的因果。
时间序列可简化为两部分:趋势和季节性,以及两者之外的随机变动。
时间序列定义
时间序列是事物在不同时间上的相继观察值排列而成的序列。时间序列中的时间可以是可以是年份、季度、月份或其他任何时间形式。
常见时序预测方法

预测方法的分类概念
我们可以将时间序列预测方法分为几个主要类别,包括单变量预测、多变量预测,以及其他一些其它的预测方法。
单变量时间序列预测:
单变量时间序列预测是最常见的预测方法,它只依赖于一个单一的时间序列数据源。这种类型的预测主要关注如何根据过去的数据来预测未来的数据。常见的单变量预测方法包括自回归移动平均模型(ARIMA)、指数平滑模型、随机森林和深度学习模型等。
多变量时间序列预测:
与单变量预测相比,多变量时间序列预测使用两个或更多的相关时间序列来进行预测。这种方法可以帮助我们更好地理解和利用不同变量之间的相互关系。多变量预测方法包括向量自回归模型(VAR)、协整模型和多变量深度学习模型等。
传统时序预测方法
1. 朴素法
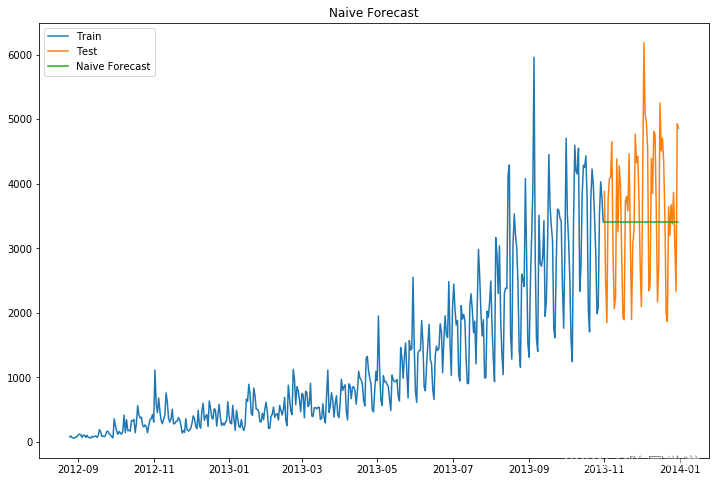
朴素法就是预测值等于实际观察到的最后一个值。它假设数据是平稳且没有趋势性与季节性的。通俗来说就是以后的预测值都等于最后的值。
这种方法很明显适用情况极少,所以我们重点通过这个方法来熟悉一下数据可视化与模型的评价及其相关代码。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")#不显示警告信息
df = pd.read_csv('time_series_data.csv')
df.info()
# 按照天聚合数据
df.Timestamp = pd.to_datetime(df.Datetime,format='%d-%m-%Y %H:%M')
df.index = df.Timestamp
df_ts = df.resample('D').sum()
df_ts
#2012 年 8 月- 2013 年 10 月用作训练数据,2013 年 11 月 – 2013 年 12 月用作测试数据。
train = df_ts['2012-08-25':'2013-10-31']
test = df_ts['2013-11-1':'2013-12-31']
train.tail()
#朴素法
dd = np.asarray(train['Count'])#训练组数据
y_hat = test.copy()#测试组数据
y_hat['naive'] = dd[len(dd) - 1]#预测组数据
#数据可视化
plt.figure(figsize=(12, 8))
plt.plot(train.index, train['Count'], label='Train')
plt.plot(test.index, test['Count'], label='Test')
plt.plot(y_hat.index, y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()
得到预测结果为:
我们可以通过计算均方根误差检验模型准确率。其中均方根误差(RMSE)是各数据偏离真实值的距离平方和的平均数的开方。
#计算均方根误差RMSE
from sklearn.metrics import mean_squared_error
from math import sqrt
# mean_squared_error求均方误差
rmse = sqrt(mean_squared_error(test['Count'], y_hat['naive']))
print(rmse)
得到RMSE=1053,可见朴素法的误差非常大。
2. 简单平均法
预测值等于之前过去所有值的平均。这种方法也不准确,但在某些情况下非常有效。
#简单平均法
y_hat_avg = test.copy()#测试组数据
y_hat_avg['avg_forecast'] = train['Count'].mean()#预测组数据
plt.figure(figsize=(12,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['avg_forecast'], label='Average Forecast')
plt.legend(loc='best')
plt.show()
预测结果为: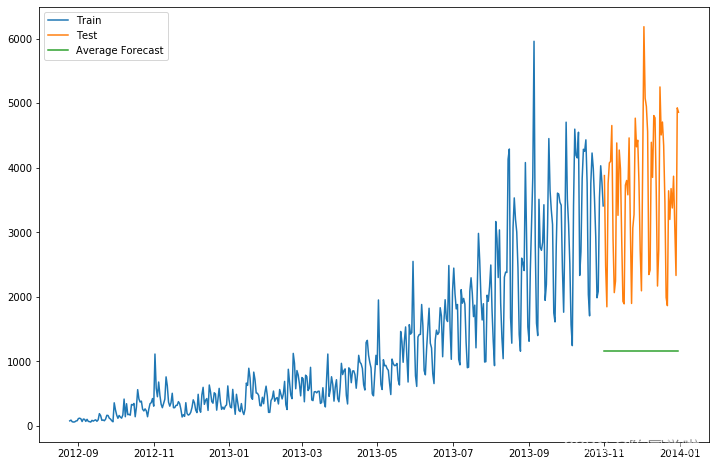
得到RMSE=2637.
3. 移动平均法
有一种数据集,价格在某些时间大幅上升或下降。此时我们用简单平均法,就得使用所有先前数据的平均值,但这是不合理的,因为开始的数据会大幅影响预测情况。因此,我们可以只取近段时期的数据。
这种用某些窗口期计算平均值的预测方法就叫移动平均法。
#移动平均法
y_hat_avg = test.copy()#测试数据
#利用时间窗函数rolling求平均值u
y_hat_avg['moving_avg_forecast'] = train['Count'].rolling(60).mean().iloc[-1]#预测数据
plt.figure(figsize=(16,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['moving_avg_forecast'], label='Moving Average Forecast')
plt.legend(loc='best')
plt.show()
得到预测结果为: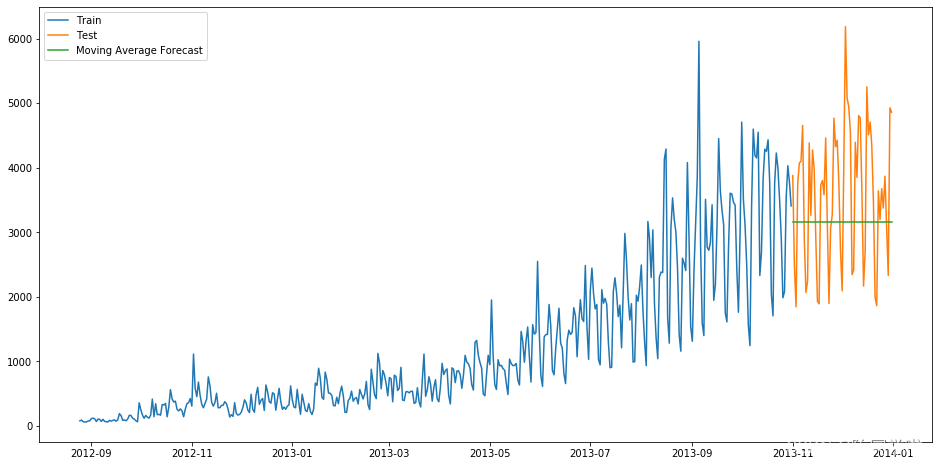
RMSE为1121
4 指数平滑法
在做时序预测时,一个显然的思路是:认为离着预测点越近的点,作用越大。假设随着时间的变化,权重以指数方式下降,年代久远的数据权重将接近于0。
将权重按照指数级进行衰减,这就是指数平滑法的基本思想。
指数平滑法有几种不同形式:一次指数平滑法针对没有趋势和季节性的序列,二次指数平滑法针对有趋势但没有季节性的序列,三次指数平滑法针对有趋势也有季节性的序列。“
所有的指数平滑法都要更新上一时间步长的计算结果,并使用当前时间步长的数据中包含的新信息。它们通过”混合“新信息和旧信息来实现,而相关的新旧信息的权重由一个可调整的参数来控制。
我们可以通过调整平滑系数,决定把多大比例的“随机”变动当成规律性的变动——平滑系数越大,我们认为随机变动中的规律性比例就越高。
4.1 一次指数平滑
一次指数平滑法的递推关系如下:

其中s为时间步长i(第i个时间点)上经过平滑后的值,x则为时间步长i上的实际数据。a的区间是0到1,它控制着新旧信息之间的平衡:当a接近1,只保留当前数据点;当a接近0,只保留前面的平滑值(整个曲线都是平的)。
递推关系式: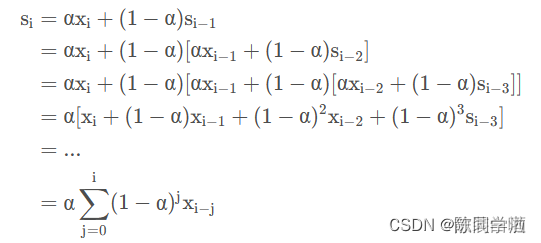
在指数平滑法中,所有先前的观测值都对当前的平滑值产生了影响,但它们所起的作用随着参数 α 幂的增大而逐渐减小。那些相对较早的观测值所起的作用相对较小。同时,称α为记忆衰减因子可能更合适——因为α的值越大,模型对历史数据“遗忘”的就越快。从某种程度来说,指数平滑法就像是拥有无限记忆(平滑窗口足够大)且权值呈指数级递减的移动平均法。一次指数平滑所得的计算结果可以在数据集及范围之外进行扩展,因此也就可以用来进行预测。
预测方式为:

s为最后一个算出来的值。h等于1代表预测的第一个值。
python代码:
#一次指数平滑
from statsmodels.tsa.api import SimpleExpSmoothing
y_hat_avg = test.copy()
fit = SimpleExpSmoothing(np.asarray(train['Count'])).fit(smoothing_level=0.6, optimized=False)
y_hat_avg['SES'] = fit.forecast(len(test))
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SES'], label='SES')
plt.legend(loc='best')
plt.show()
得到预测结果为:
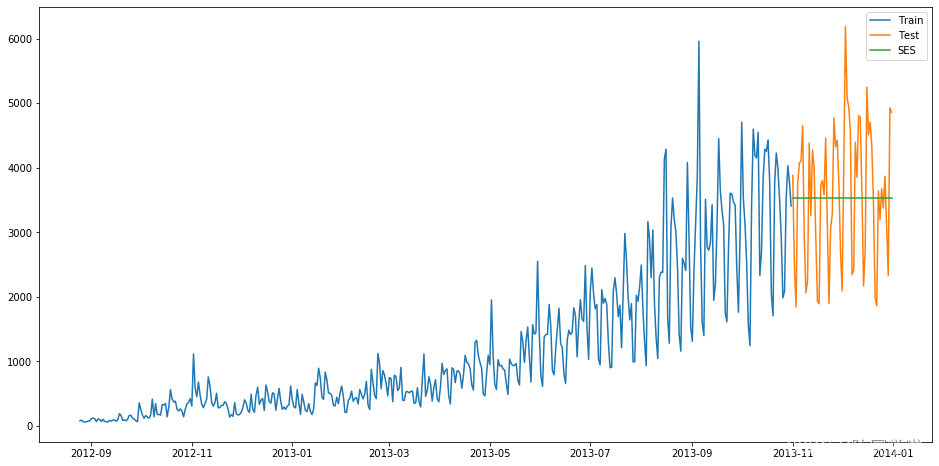
结果为RMSE=1040
4.2 二次指数平滑
二次指数平滑在一次指数平滑的基础上,将趋势作为一个额外考量,保留了趋势的详细信息。我们要保留并更新两个量:平滑后的数据和平滑后的趋势。
公式如下:
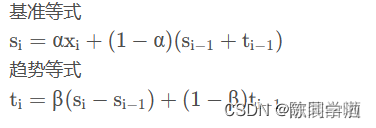
当前趋势告诉我们在上一个时间步长里平滑信号改变了多少。要想使趋势平滑,我们用一次指数平滑法对趋势进行处理,并使用参数 β 。临近的趋势权重大。
若要利用该计算结果进行预测,就取最后那个平滑值,然后每增加一个时间步长就在该平滑值上增加一次最后那个平滑趋势:
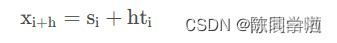
python代码:
from statsmodels.tsa.api import Holt
y_hat_avg = test.copy()
fit = Holt(np.asarray(train['Count'])).fit(smoothing_level=0.3, smoothing_slope=0.1)
y_hat_avg['Holt_linear'] = fit.forecast(len(test))
得到预测结果为:
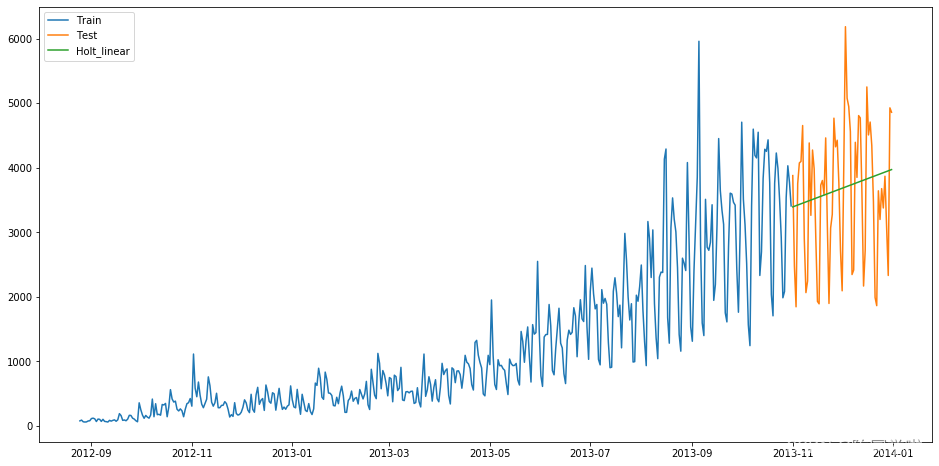 结果为RMSE=1033
结果为RMSE=1033
4.3 三次指数平滑
如果数据集在一定时间段内的固定区间内呈现相似的模式,那么该数据集就具有季节性。二次指数平滑考虑了序列的基数和趋势,三次指数平滑在此基础上添加了一个季节分量。
公式如下:
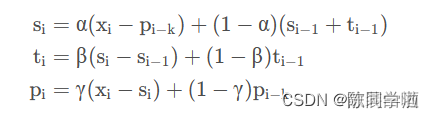
P_i是指“周期性部分”,k为周期的长度,预测公式如下:
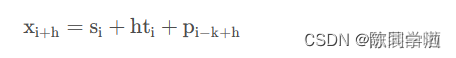
在使用二次平滑模型与三次平滑模型前,我们可以使用sm.tsa.seasonal_decompose分解时间序列,可以得到以下分解图形——从上到下依次是原始数据、趋势数据、周期性数据、随机变量(残差值)。根据分析图形和数据可以确定对应的季节参数。
python代码:
#三次指数平滑
from statsmodels.tsa.api import ExponentialSmoothing
y_hat_avg = test.copy()
fit1 = ExponentialSmoothing(np.asarray(train['Count']), seasonal_periods=7, trend='add', seasonal='add', ).fit()
y_hat_avg['Holt_Winter'] = fit1.forecast(len(test))
得到预测结果为:
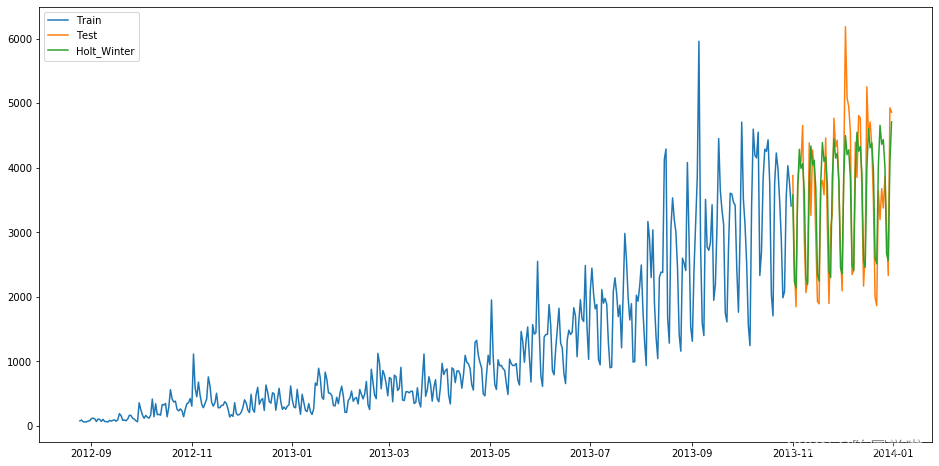
结果RMSE=575,我们可以看到趋势和季节性的预测准确度很高。我们可以通过调整参数优化模型。
5 AR模型
AR(Auto Regressive Model)自回归模型是线性时间序列分析模型中最简单的模型。通过自身前面部分的数据与后面部分的数据之间的相关关系(自相关)来建立回归方程,从而可以进行预测或者分析。服从p阶的自回归方程表达式如下:
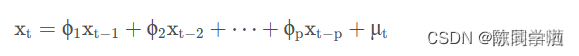
其中μ表示白噪声,是时间序列中的数值的随机波动,但是这些波动会相互抵消,最终是0。p为自回归系数。
所以当只有一个时间记录点时,称为一阶自回归过程,即AR(1)。其表达式为:

利用Python建立AR模型一般会用到我们之后会说到的ARIMA模型(AR模型中的p是ARIMA模型中的参数之一,只要将其他的参数设置为0即为AR模型)。
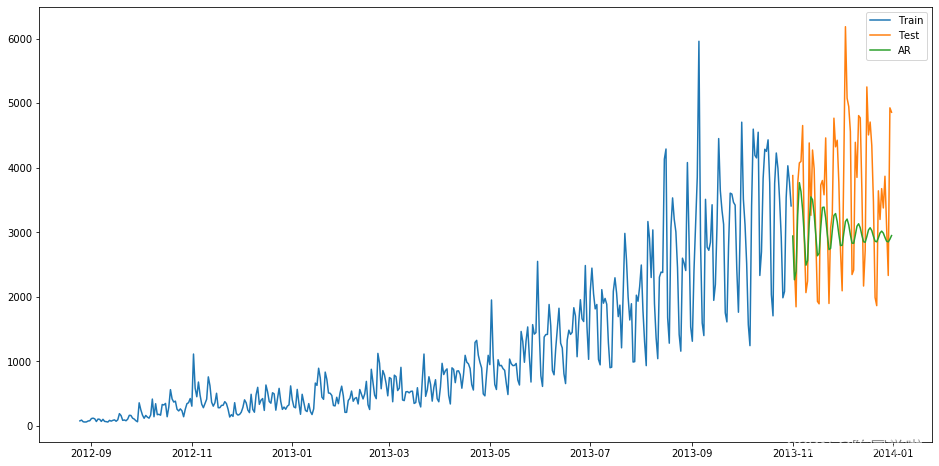
6 MA模型
MA(Moving Average Model)移动平均模型通过将一段时间序列中白噪声(误差)进行加权和,可以得到移动平均方程。如下模型为q阶移动平均过程,表示为MA(q),q是移动平均阶数。
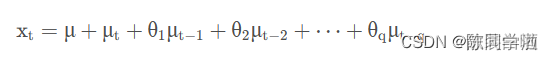
当前时间点的值由前q期的误差来决定,μ为常数项,相当于普通回归中的截距项;μ_t为当前时间点的随机误差。MA模型的核心思想是每一期的随机误差都会影响当期值,把前q期的所有误差加起来就是对t期值的影响。
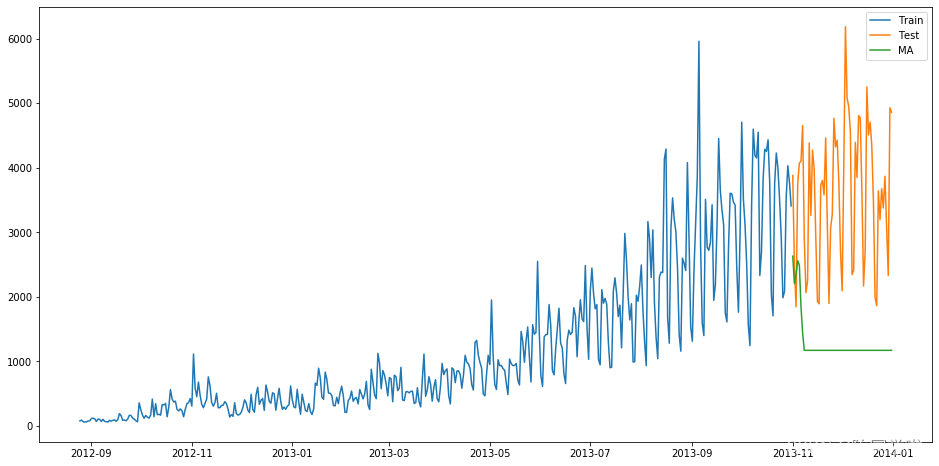
7 ARMA模型
ARMA(Auto Regressive and Moving Average Model)自回归移动平均模型是与自回归和移动平均模型两部分组成。所以可以表示为ARMA(p, q)。p是自回归阶数,q是移动平均阶数。
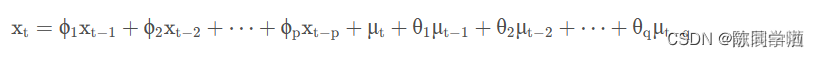
从式子中就可以看出,自回归模型结合了两个模型的特点,其中,AR可以解决当前数据与后期数据之间的关系,MA则可以解决随机变动也就是噪声的问题。
8 ARIMA模型
ARIMA(Auto Regressive Integrate Moving Average Model)差分自回归移动平均模型是在ARMA模型的基础上进行改造的,ARMA模型是针对t期值进行建模的,而ARIMA是针对t期与t-d期之间差值进行建模,我们把这种不同期之间做差称为差分,这里的d是几就是几阶差分。ARIMA模型也是基于平稳的时间序列的或者差分化后是稳定的,另外前面的几种模型都可以看作ARIMA的某种特殊形式。表示为ARIMA(p, d, q)。p为自回归阶数,q为移动平均阶数,d为时间成为平稳时所做的差分次数,也就是Integrate单词的在这里的意思。
具体步骤如下:
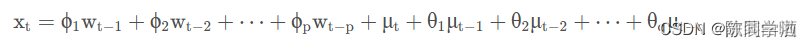
我们可以看到ARIMA模型的形式基本与ARMA的形式是一致的,只不过把x换成了w。
from statsmodels.tsa.arima_model import ARIMA
ts_ARIMA= train['Count'].astype(float)
fit1 = ARIMA(ts_ARIMA, order=(7, 1, 4)).fit()
y_hat_ARIMA = fit1.predict(start="2013-11-1", end="2013-12-31", dynamic=True)
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_ARIMA, label='ARIMA')
plt.legend(loc='best')
plt.show()
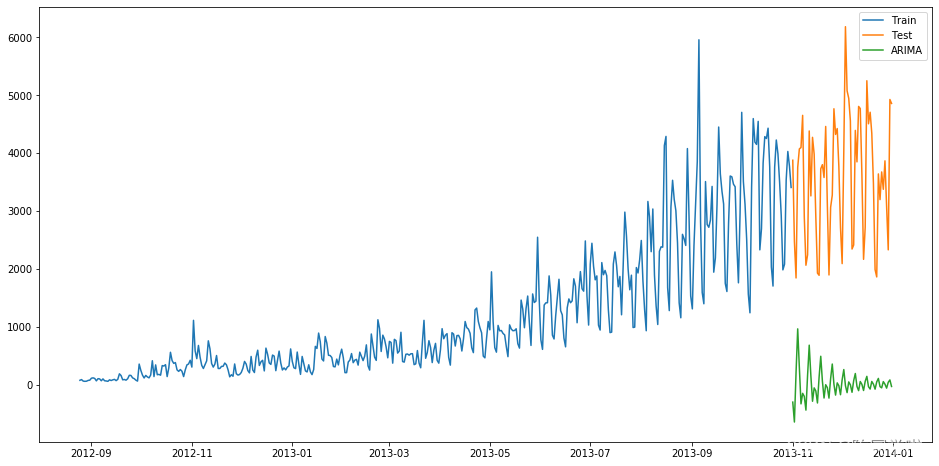
最终RMSE为3723.
ARIMA模型实战案例
时间序列预测模型实战案例(六)深入理解机器学习ARIMA包括差分和相关性分析
9 SARIMA模型
SARIMA季节性自回归移动平均模型模型在ARIMA模型的基础上添加了季节性的影响,结构参数有七个:SARIMA(p,d,q)(P,D,Q,s)
其中p,d,q分别为之前ARIMA模型中我们所说的p:趋势的自回归阶数。d:趋势差分阶数。q:趋势的移动平均阶数。
P:季节性自回归阶数。
D:季节性差分阶数。
Q:季节性移动平均阶数。
s:单个季节性周期的时间步长数。
import statsmodels.api as sm
y_hat_avg = test.copy()
fit1 = sm.tsa.statespace.SARIMAX(train.Count, order=(2, 1, 4), seasonal_order=(0, 1, 1, 7)).fit()
y_hat_avg['SARIMA'] = fit1.predict(start="2013-11-1", end="2013-12-31", dynamic=True)
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SARIMA'], label='SARIMA')
plt.legend(loc='best')
plt.show()
得到预测结果为:
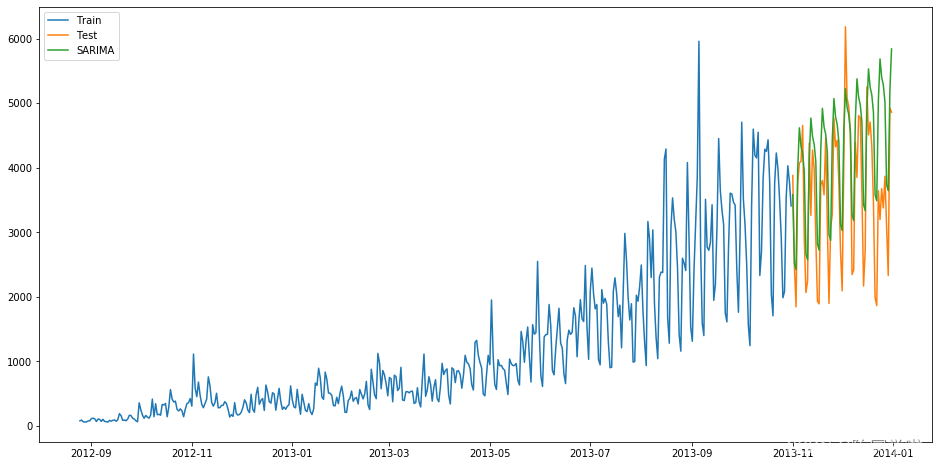
结果RMSE=933
传统时间序列预测模型优缺点
适用范围
根据客观事物发展的这种连续规律性, 运用过去的历史数据, 通过统计分析, 进一步推测市场未来的发展趋势。 时间序列, 在时间序列分析预测法处于核心位置。
优点
一般用 ARMA 模型拟合时间序列, 预测该时间序列未来值。 Daniel 检验平稳性。 自动回归 AR(Auto regressive) 和 移动平均 MA(Moving Average)预测模型。
缺点
当遇到外界发生较大变化, 往往会有较大偏差, 时间序列预测法对于中短期预测的效果要比长期预测的效果好。
深度学习模型
LSTM
时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
GRU
时间序列预测实战(十五)PyTorch实现GRU模型长期预测并可视化结果
机器学习模型
图解机制原理
时间序列预测模型实战案例(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
经典确定性模型:SI, SIS, SIR, SEIR
前言
混合良好的人口,被划分为几个不连贯的阶层;流行病,即控制个人在阶层之间过渡的过程。
经典模型包括以下类别:
S类 易感个体,即那些可能变得具有传染性的人
E类 暴露个体,即那些被感染但尚未具有传染性的人
I类 感染个体,即那些可以传播疾病的人
R类 移除个体,即那些不能再传播疾病的人。
类别的数量取决于模型,但所有模型都包括S类和I类。所有实现的模型都是确定性的,即流行病动力学是由微分方程给出的。因此,人口是封闭的,被视为一个连续体,而流行病的进程在时间上是连续的。每个类都是同质的,具有时间无关的性质,即一个类中的所有个体都是平等的;因此,类之间的转换速率是常数。
请注意,经典的流行病模型描述的是个体在阶级之间的动态过渡,而不是阶级内部的过程。
人们可以通过几个经典的确定性流行病模型模拟对流行病的评估,而无需生命动力学:
SI – 易感->感染性
SIS – 易感性->感染性->易感性
SIR – 易感->感染性->去除
SEIR – 易感->暴露->感染->移除
传染病模型
SI
SI 模型是最简单的传染病传播模型,把人群分为易感者(S 类)和患病者(I 类)两类,通过 SI 模型可以预测传染病高潮的到来;提高卫生水平、强化防控手段,降低病人的日接触率,可以推迟传染病高潮的到来。
模型方程:

S 代表易感个体,
I 代表感染者。
参数 β 和 γ 分别控制传输速率和恢复速率。
易感人群数量随着感染疾病而减少(即 dS/dt),感染人数因新感染而增加,随着康复而减少(即dI/dt)
SIS
在 SI 模型基础上发展的 SIS 模型考虑患病者可以治愈而变成易感者,SIS 模型表面传染期接触数 σ 是传染病传播和防控的关键指标,决定了疫情终将清零或演变为地方病长期存在。
模型方程:

#SIS model equations
def dySIS(y, t, lamda, mu): # SIS 模型,导数函数
dy_dt = lamda*y*(1-y) - mu*y # di/dt = lamda*i*(1-i)-mu*i
return dy_dt
SIR
在 SI 模型基础上考虑病愈免疫的康复者(R 类)就得到 SIR 模型,通过 SIR 模型也揭示传染期接触数 σ 是传染病传播的阈值,满足 S0>1/σ 才会发生传染病蔓延,由此可以分析各种防控措施,如:提高卫生水平来降低日接触率λ、提高医疗水平来提高日治愈率 μ,通过预防接种达到群体免疫来降低 S0 等。
模型方程:

#SIR model equations
def dySIR(y, t, beta, gamma):
S, I, R = y
dSdt = -beta * S * I
dIdt = beta * S * I - gamma * I
dRdt = gamma * I
return [dSdt, dIdt, dRdt]
SIR Python 代码模拟示例
import numpy as np
from scipy.integrate import odeint
import matplotlib.pyplot as plt
# SIR model equations
def SIR_model(y, t, beta, gamma):
S, I, R = y
dSdt = -beta * S * I
dIdt = beta * S * I - gamma * I
dRdt = gamma * I
return [dSdt, dIdt, dRdt]
""" Initial conditions (such as S0, I0, and R0) are not to be random but I hardcoded them with specific values. These choices are typically made based on the characteristics of the disease being modeled and the context of the simulation. Initial condition are set such that S0 = 99%, which indicates the proportion of susceptible individuals when the simulation starts. I0 is set to 1%, which indicates proportion of infected individuals to be 1% when the simulation starts. R0 is set to 0% which is expected that there are are no recovered individuals when the simulations start. """
S0 = 0.99
I0 = 0.01
R0 = 0.00
y0 = [S0, I0, R0]
# Parameters
# β (beta) is transmission rate and I chose 30%. γ (gamma) is set to 1%
beta = 0.3
gamma = 0.1
# Time vector
t = np.linspace(0, 200, 200)
# Simulate for 200 days
# Solve the SIR model equations using odeint()
solution = odeint(SIR_model, y0, t, args=(beta, gamma))
# Extract results
S, I, R = solution.T
# Plot the results
plt.figure(figsize=(10, 6))
plt.plot(t, S, label='Susceptible')
plt.plot(t, I, label='Infected')
plt.plot(t, R, label='Recovered')
plt.xlabel('Time (days)')
plt.ylabel('Proportion of Population')
plt.title('SIR Model Simulation')
plt.legend()
plt.grid(True)
plt.show()

SEIR
传染病大多具有潜伏期(incubation period),也叫隐蔽期,是指从被病原体侵入肌体到最早临床症状出现的一段时间。在潜伏期的后期一般具有传染性。不同的传染病的潜伏期长短不同,从短至数小时到长达数年,但同一种传染病有固定的(平均)潜伏期。例如,流感的潜伏期为 1~3天,冠状病毒感染的潜伏期为4~7天,新型冠状病毒肺炎传染病(COVID-19)的潜伏期为1-14天
(* 来自:新型冠状病毒肺炎诊疗方案试行第八版,潜伏时间 1~14天,多为3~7天,在潜伏期具有传染性),肺结核的潜伏期从数周到数十年。
SEIR 模型考虑存在易感者(Susceptible)、暴露者(Exposed)、患病者(Infectious)和康复者(Recovered)四类人群,适用于具有潜伏期、治愈后获得终身免疫的传染病。易感者(S 类)被感染后成为潜伏者(E类),随后发病成为患病者(I 类),治愈后成为康复者(R类)。这种情况更为复杂,也更为接近实际情况。
模型方程:

#SEIR model equations
def dySEIR(y, t, lamda, delta, mu):
s, e, i = y
ds_dt = - lamda*s*i # ds/dt = -lamda*s*i
de_dt = lamda*s*i - delta*e # de/dt = lamda*s*i - delta*e
di_dt = delta*e - mu*i # di/dt = delta*e - mu*i
return np.array([ds_dt,de_dt,di_dt])
SEIR Python 代码模拟示例
import numpy as np
from scipy.integrate import odeint
import matplotlib.pyplot as plt
# SEIR model equations
def SEIR_model(y, t, beta, sigma, gamma):
S, E, I, R = y
dSdt = -beta * S * I
dEdt = beta * S * I - sigma * E
dIdt = sigma * E - gamma * I
dRdt = gamma * I
return [dSdt, dEdt, dIdt, dRdt]
# Initial conditions
S0 = 0.99
E0 = 0.01
I0 = 0.00
R0 = 0.00
y0 = [S0, E0, I0, R0]
# Parameters
beta = 0.3
sigma = 0.1
gamma = 0.05
# Time vector
t = np.linspace(0, 200, 200)
# Solve the SEIR model equations
solution = odeint(SEIR_model, y0, t, args=(beta, sigma, gamma))
# Extract results
S, E, I, R = solution.T
# Plot the results
plt.figure(figsize=(10, 6))
plt.plot(t, S, label='Susceptible')
plt.plot(t, E, label='Exposed')
plt.plot(t, I, label='Infected')
plt.plot(t, R, label='Recovered')
plt.xlabel('Time (days)')
plt.ylabel('Proportion of Population')
plt.title('SEIR Model Simulation')
plt.legend()
plt.grid(True)
plt.show()

补充参考文章
15种时间序列预测方法总结(包含多种方法代码实现)
数学建模系列-预测模型(三)时间序列预测模型
time_series_ARIMA.ipynb
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较
时序预测模型汇总
时间序列预测模型实战案例(六)深入理解机器学习ARIMA包括差分和相关性分析
MATLAB|SEIRS|通过经典确定性模型模拟流行病:SI,SIS,SIR,SIRS,SEIR,SEIR,SEIRS
使用 Python 模拟传染病传播:SIR 和 SEIR 模型
数学建模:新冠疫情 SEIR模型

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









