








一、本文介绍
本文讲解的实战内容是GRU(门控循环单元),本文的实战内容通过时间序列领域最经典的数据集——电力负荷数据集为例,深入的了解GRU的基本原理和框架,GRU是时间序列领域最常见的Cell之一,其相对于LSTM需要的参数量更少结构也更加简单,经常用于复杂的模型的过度单元,本文的讲解内容包括详细的代码讲解,带你一行一行的理解整个项目的流程,从而对整个项目有一个深入的了解,如果你是时间序列领域的新人,这篇文章可以带你入门时间序列领域并对时间序列的流程有一个详细的了解。
预测类型->单元预测、多元预测、长期预测
代码地址->文末提供复制粘贴即可运行的代码块
二、框架原理介绍
1.GRU的基本原理
GRU(门控循环单元)是一种循环神经网络(RNN)的变体,主要用于处理序列数据,它的基本原理可以概括如下:
门控机制:GRU的核心是门控机制,包括更新门(update gate)和重置门(reset gate)。这些门控制着信息的流动,即决定哪些信息应该被保留,哪些应该被遗忘。
更新门:更新门帮助模型决定过去的信息有多少需要保留到当前状态。它是通过当前输入和前一个隐状态计算得出的,用于调节隐状态的更新程度。
重置门:重置门决定了多少过去的信息需要被忘记。它同样依赖于当前输入和前一个隐状态的信息。当重置门接近0时,模型会“忘记”过去的隐状态,只依赖于当前输入。
当前隐状态的计算:利用更新门和重置门的输出,结合前一隐状态和当前输入,GRU计算出当前的隐状态。这个隐状态包含了序列到目前为止的重要信息。
输出:GRU的最终输出通常是在序列的每个时间步上产生的,或者在序列的最后一个时间步产生,取决于具体的应用场景。
总结:GRU相较于传统的RNN,其优势在于能够更有效地处理长序列数据,减轻了梯度消失的问题。同时,它通常比LSTM(长短期记忆网络)更简单,因为它有更少的参数。
1.1GRU的基本框架

上面的图片为一个GRU的基本结构图,解释如下->
- 更新门(z) 在决定是否用新的隐藏状态更新当前隐藏状态时扮演重要角色。
- 重置门(r) 决定是否忽略之前的隐藏状态。
这些部分是GRU的核心组成,它们共同决定了网络如何在序列数据中传递和更新信息,这对于时间序列分析至关重要。
总结:这个 GRU真的是结构太简单了,没什么好讲解的,如果你是时间序列预测的新手这篇文章能够帮助你很好的入门时间序列并且能够对时间序列的整体流程有一个完整的了解,如果你是大神这边文章可能并不能给你带来太多的帮助。
三、数据集介绍
我们本文用到的数据集是官方的ETTh1.csv ,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是 ETTh1.csv 数据集的一些内容:
数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->

四、项目的全部代码
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader
import torch
from torch.utils.data import Dataset
# 随机数种子
np.random.seed(0)
class TimeSeriesDataset(Dataset):
def __init__(self, sequences):
self.sequences = sequences
def __len__(self):
return len(self.sequences)
def __getitem__(self, index):
sequence, label = self.sequences[index]
return torch.Tensor(sequence), torch.Tensor(label)
def calculate_mae(y_true, y_pred):
# 平均绝对误差
mae = np.mean(np.abs(y_true - y_pred))
return mae
"""
数据定义部分
"""
true_data = pd.read_csv('ETTh1.csv') # 填你自己的数据地址,自动选取你最后一列数据为特征列
target = 'OT' # 添加你想要预测的特征列
test_size = 0.15 # 训练集和测试集的尺寸划分
train_size = 0.85 # 训练集和测试集的尺寸划分
pre_len = 4 # 预测未来数据的长度
train_window = 32 # 观测窗口
# 这里加一些数据的预处理, 最后需要的格式是pd.series
true_data = np.array(true_data[target])
# 定义标准化优化器
scaler_train = MinMaxScaler(feature_range=(0, 1))
scaler_test = MinMaxScaler(feature_range=(0, 1))
# 训练集和测试集划分
train_data = true_data[:int(train_size * len(true_data))]
test_data = true_data[-int(test_size * len(true_data)):]
print("训练集尺寸:", len(train_data))
print("测试集尺寸:", len(test_data))
# 进行标准化处理
train_data_normalized = scaler_train.fit_transform(train_data.reshape(-1, 1))
test_data_normalized = scaler_test.fit_transform(test_data.reshape(-1, 1))
# 转化为深度学习模型需要的类型Tensor
train_data_normalized = torch.FloatTensor(train_data_normalized)
test_data_normalized = torch.FloatTensor(test_data_normalized)
def create_inout_sequences(input_data, tw, pre_len):
# 创建时间序列数据专用的数据分割器
inout_seq = []
L = len(input_data)
for i in range(L - tw):
train_seq = input_data[i:i + tw]
if (i + tw + 4) > len(input_data):
break
train_label = input_data[i + tw:i + tw + pre_len]
inout_seq.append((train_seq, train_label))
return inout_seq
# 定义训练器的的输入
train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len)
test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len)
# 创建数据集
train_dataset = TimeSeriesDataset(train_inout_seq)
test_dataset = TimeSeriesDataset(test_inout_seq)
# 创建 DataLoader
batch_size = 32 # 你可以根据需要调整批量大小
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
class GRU(nn.Module):
def __init__(self, input_dim=1, hidden_dim=32, num_layers=1, output_dim=1, pre_len= 4):
super(GRU, self).__init__()
self.pre_len = pre_len
self.num_layers = num_layers
self.hidden_dim = hidden_dim
# 替换 LSTM 为 GRU
self.gru = nn.GRU(input_dim, hidden_dim,num_layers=num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.1)
def forward(self, x):
h0_gru = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
out, _ = self.gru(x, h0_gru)
out = self.dropout(out)
# 取最后 pre_len 时间步的输出
out = out[:, -self.pre_len:, :]
out = self.fc(out)
out = self.relu(out)
return out
lstm_model = GRU(input_dim=1, output_dim=1, num_layers=2, hidden_dim=train_window, pre_len=pre_len)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)
epochs = 20
Train = True # 训练还是预测
if Train:
losss = []
lstm_model.train() # 训练模式
for i in range(epochs):
start_time = time.time() # 计算起始时间
for seq, labels in train_loader:
lstm_model.train()
optimizer.zero_grad()
y_pred = lstm_model(seq)
single_loss = loss_function(y_pred, labels)
single_loss.backward()
optimizer.step()
print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
losss.append(single_loss.detach().numpy())
torch.save(lstm_model.state_dict(), 'save_model.pth')
print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")
else:
# 加载模型进行预测
lstm_model.load_state_dict(torch.load('save_model.pth'))
lstm_model.eval() # 评估模式
results = []
reals = []
losss = []
for seq, labels in test_loader:
pred = lstm_model(seq)
mae = calculate_mae(pred.detach().numpy(), np.array(labels)) # MAE误差计算绝对值(预测值 - 真实值)
losss.append(mae)
for j in range(batch_size):
for i in range(pre_len):
reals.append(labels[j][i][0].detach().numpy())
results.append(pred[j][i][0].detach().numpy())
reals = scaler_test.inverse_transform(np.array(reals).reshape(1, -1))[0]
results = scaler_test.inverse_transform(np.array(results).reshape(1, -1))[0]
print("模型预测结果:", results)
print("预测误差MAE:", losss)
plt.figure()
plt.style.use('ggplot')
# 创建折线图
plt.plot(reals, label='real', color='blue') # 实际值
plt.plot(results, label='forecast', color='red', linestyle='--') # 预测值
# 增强视觉效果
plt.grid(True)
plt.title('real vs forecast')
plt.xlabel('time')
plt.ylabel('value')
plt.legend()
plt.savefig('test——results.png')
五、模型代码的详细讲解
整个代码的流程我会从模型的入口参数定义开始进行讲解, 然后顺序讲解在直到模型的结束。
true_data = pd.read_csv('ETTh1.csv') # 填你自己的数据地址,自动选取你最后一列数据为特征列这一步就是读取你的数据了~不给大家讲了主要是csv的格式数据。
target = 'OT' # 添加你想要预测的特征列
test_size = 0.15 # 训练集和测试集的尺寸划分
train_size = 0.85 # 训练集和测试集的尺寸划分
pre_len = 4 # 预测未来数据的长度
train_window = 32 # 观测窗口这一步就是参数定义的部分,讲解我已经再代码里标注了出来,需要说说的就是,pre_len和train_window这两个参数,
其中pre_len就是你预测未来数据的长度,假设你有一百条数据你想知道未来多少条数据的信息就填多少。
train_window是数据的观测窗口,就是你利用多少条数据去预测你定义的pre_len长度。
# 这里加一些数据的预处理, 最后需要的格式是pd.series
true_data = np.array(true_data[target])这是提取出特征列,根据前面你定义的target。
# 定义标准化优化器
scaler_train = MinMaxScaler(feature_range=(0, 1))
scaler_test = MinMaxScaler(feature_range=(0, 1))
# 训练集和测试集划分
train_data = true_data[:int(train_size * len(true_data))]
test_data = true_data[-int(test_size * len(true_data)):]
print("训练集尺寸:", len(train_data))
print("测试集尺寸:", len(test_data))
# 进行标准化处理
train_data_normalized = scaler_train.fit_transform(train_data.reshape(-1, 1))
test_data_normalized = scaler_test.fit_transform(test_data.reshape(-1, 1))
# 转化为深度学习模型需要的类型Tensor
train_data_normalized = torch.FloatTensor(train_data_normalized)
test_data_normalized = torch.FloatTensor(test_data_normalized)这部分是定义优化器,我们的深度学习模型输入一般都是-1到1(虽然这不是必须的,但是如果你不进行标准化处理效果真是天差地别),然后是测试集和训练集的划分,和根据数据进行标准化处理的操作,并且将数据转化为tensor的格式(tensor是我们深度学习特有的数据格式)。
# 定义训练器的的输入
train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len)
test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len)这一部分是重点!!!!!
时间序列的数据和其他领域的不一样他需要滑窗的数据形式,假设我有100条数据,前面定义的滑窗大小是32预测未来数据的长度是4那么他就会用32和4去滑动数据,
所以我们的到数据是多少呢就是100 - 32 - 4 =54条数据(每条数据包含32条观测数据和4个标签数据),这里必须理解大家这是时间序列的基础,他是不能够直接用Dataloader进行数据加载的。
# 创建数据集
train_dataset = TimeSeriesDataset(train_inout_seq)
test_dataset = TimeSeriesDataset(test_inout_seq)
# 创建 DataLoader
batch_size = 32 # 你可以根据需要调整批量大小
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
这部分是创建数据集和Dataloader数据加载器,利用Dataloader的好处是可以避免内存爆炸,但是我们时间序列的数据一般都不大不会有这种情况。
class GRU(nn.Module):
def __init__(self, input_dim=1, hidden_dim=32, num_layers=1, output_dim=1, pre_len= 4):
super(GRU, self).__init__()
self.pre_len = pre_len
self.num_layers = num_layers
self.hidden_dim = hidden_dim
# 替换 LSTM 为 GRU
self.gru = nn.GRU(input_dim, hidden_dim,num_layers=num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.1)
def forward(self, x):
h0_gru = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)
out, _ = self.gru(x, h0_gru)
out = self.dropout(out)
# 取最后 pre_len 时间步的输出
out = out[:, -self.pre_len:, :]
out = self.fc(out)
out = self.relu(out)
return out
这是模型的内部,就是一个简单的gru模型,我来说一下其中的通道数情况,我们输入的X是三维的分别是[batch_size, train_window, target数量], 这是我们输入x的情况,经过gru进行处理我们添加了一个dropout避免过拟合,然后取出了你想要预测长度的步长数据,最后经过全连接层进行一个结果输出,大家有兴趣建议还是debug一下我这么讲你是不能理解的,最好还是实际动手debug看一下其中的通道数变化情况。
lstm_model = GRU(input_dim=1, output_dim=1, num_layers=2, hidden_dim=train_window, pre_len=pre_len)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)
epochs = 20
Train = True # 训练还是预测
这里实例化了我们的模型,定义了MSE损失函数,和优化器Adam和训练轮次,其中的Train是来判断是否进行训练。
if Train:
losss = []
lstm_model.train() # 训练模式
for i in range(epochs):
start_time = time.time() # 计算起始时间
for seq, labels in train_loader:
lstm_model.train()
optimizer.zero_grad()
y_pred = lstm_model(seq)
single_loss = loss_function(y_pred, labels)
single_loss.backward()
optimizer.step()
print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
losss.append(single_loss.detach().numpy())
torch.save(lstm_model.state_dict(), 'save_model.pth')
print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")如果Train为True则开始训练执行上面的代码,这是一个标准pytorch框架下的训练过程就不给大家 说了,如果不能理解的话大家可以去补补基础,或者评论区问我我在给大家讲讲。
else:
# 加载模型进行预测
lstm_model.load_state_dict(torch.load('save_model.pth'))
lstm_model.eval() # 评估模式
results = []
reals = []
losss = []
for seq, labels in test_loader:
pred = lstm_model(seq)
mae = calculate_mae(pred.detach().numpy(), np.array(labels)) # MAE误差计算绝对值(预测值 - 真实值)
losss.append(mae)
for j in range(batch_size):
for i in range(pre_len):
reals.append(labels[j][i][0].detach().numpy())
results.append(pred[j][i][0].detach().numpy())如果Train为False时候则开始进行评估模式我们利用test的数据集进行测试评估训练模型,
reals = scaler_test.inverse_transform(np.array(reals).reshape(1, -1))[0]
results = scaler_test.inverse_transform(np.array(results).reshape(1, -1))[0]
print("模型预测结果:", results)
print("预测误差MAE:", losss)
plt.figure()
plt.style.use('ggplot')
# 创建折线图
plt.plot(reals, label='real', color='blue') # 实际值
plt.plot(results, label='forecast', color='red', linestyle='--') # 预测值
# 增强视觉效果
plt.grid(True)
plt.title('real vs forecast')
plt.xlabel('time')
plt.ylabel('value')
plt.legend()
plt.savefig('test——results.png')这一部分是我们预测值和真实值之间的对比,来确定我们预测的好坏,后面的结果分析会有展示。
六、模型的训练和预测
上面我把大多数的代码都讲了一便大家应该对整个过程有一个大致的了解下面来大家进行训练看看模型的结果。
6.1模型的训练
我们将我前面提供的全部代码块复制粘贴到随便一个.py的文件内然后将数据集和特征数填写进去,就可以开始训练模型了。
训练的过程中控制台会输出训练结果和损失,可以看到刚开始我们的损失非常的大,到训练结束之后我们的损失如下会变的非常小。
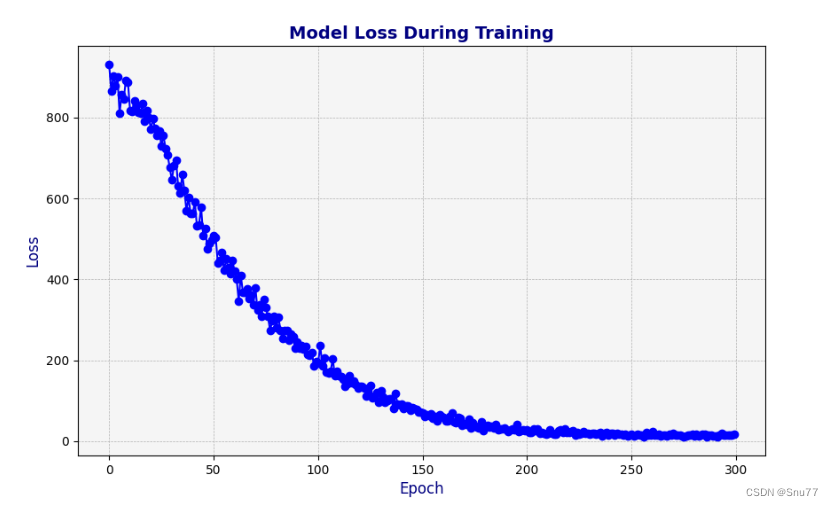
可以看到我们的模型损失只有0.010.5901一个批次下可以说模型的拟合效果是非常的好,我们下面来看一下模型的损失图像,可以看到我们模型拟合速度比较一般在20个epoch左右在完全拟合。
6.2模型的评估
经过训练之后我们可以开始进行模型的评估了。
6.2.1结果展示
下面的图片是模型的评估结果,其中评估数据大概有800条左右,评估了大概八百条数据,结果只能说太一般了。
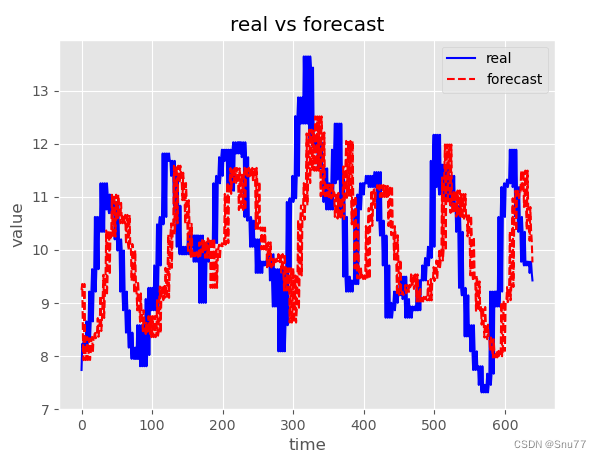
6.2.2结果分析
这个模型结果只能说在意料之中,大家看其中的图像可以看到明显的数据滞后性,这一问题我在前面利用过ARIMA-LSTM进行解决进行了完美的解决,大家有兴趣可以去回去评估一下,这单个GRU模型结果在这样只能说是正常的情况。
全文总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解,其中有数据分析的讲解就是我前面提到的如何设置参数的分析博客,最后希望大家订阅我的专栏,本专栏均分文章均分98,并且免费阅读。
概念理解
数据分析
时间序列预测中的数据分析->周期性、相关性、滞后性、趋势性、离群值等特性的分析方法
机器学习——难度等级(⭐⭐)
时间序列预测实战(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
深度学习——难度等级(⭐⭐⭐⭐)
时间序列预测实战(五)基于Bi-LSTM横向搭配LSTM进行回归问题解决
时间序列预测实战(七)(TPA-LSTM)结合TPA注意力机制的LSTM实现多元预测
时间序列预测实战(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
时间序列预测实战(十一)用SCINet实现滚动预测功能(附代码+数据集+原理介绍)
时间序列预测实战(十二)DLinear模型实现滚动长期预测并可视化预测结果
Transformer——难度等级(⭐⭐⭐⭐)
时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
时间序列预测模型实战案例(一)深度学习华为MTS-Mixers模型
时间序列预测实战(十三)定制化数据集FNet模型实现滚动长期预测并可视化结果
时间序列预测实战(十四)Transformer模型实现长期预测并可视化结果(附代码+数据集+原理介绍)
个人创新模型——难度等级(⭐⭐⭐⭐⭐)
时间序列预测实战(十)(CNN-GRU-LSTM)通过堆叠CNN、GRU、LSTM实现多元预测和单元预测
传统的时间序列预测模型(⭐⭐)
时间序列预测实战(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
时间序列预测实战(六)深入理解ARIMA包括差分和相关性分析
融合模型——难度等级(⭐⭐⭐)
时间序列预测实战(九)PyTorch实现融合移动平均和LSTM-ARIMA进行长期预测




















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











