




 本文深入介绍了Logistic回归算法,包括Sigmoid函数定义、梯度上升优化算法实现、随机梯度上升算法及其改进版本,并展示了如何绘制决策边界。
本文深入介绍了Logistic回归算法,包括Sigmoid函数定义、梯度上升优化算法实现、随机梯度上升算法及其改进版本,并展示了如何绘制决策边界。
简介
Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,一般使用梯度上升算法。
对于有n个属性的train数据集(X1,X2,...Xn),我们寻找一组回归系数(W0,W1,W2,...,Wn)使得函数:
sigmoid(W0+W1*X1+W2*X2+...+Wn*Xn)
最佳拟合train数据集的labels。
算法描述
初始化回归系数(一般初始化为1)
Repeat(N):
计算数据集的梯度
使用alpha*gradient更新回归系数
返回回归系数
Logistic回归梯度上升优化算法
#定义sigmoid函数
def sigmoid(inX):
return 1.0/(1+exp(-inX))
#梯度上升优化算法
def gradAscent(dataMatIn , classLabels , iterNum):
dataMatrix = mat(dataMatIn)
labelMat = mat(classLabels).transpose()
m,n = shape(dataMatrix)
alpha = 0.001
weights = ones((n,1))
for k in range(iterNum):
h = sigmoid(dataMatrix*weights)
error = (labelMat - h)
weights = weights + alpha*dataMatrix.transpose()*error
return weights特别说明一下,dataMatIn是原dataSet去掉最后一列(即labels),然后在第一列加入一列1之后的矩阵。
这是因为我们的回归参数中有一个常数项W0,这样统一之后就可以直接在矩阵dataMatIn上进行操作。
随机梯度上升算法
def stocGradAscent(dataMatrix , classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights可以看到,随机梯度上升算法与梯度上升算法在代码上很相似,但也有一些区别:
1.梯度上升算法的变量h和误差error都是向量;而随机梯度上升算法中,它们都是数值
2.随机梯度上升算法没有矩阵转换的过程,所有变量数据都是numpy数组。
改进的随机梯度上升算法
def stocGradAscent1(dataMatrix, classLabels, numIter = 150):
m,n = shape(dataMatrix)
weights = ones(n)
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4 / (1.0+j+i) + 0.01#alpha每次迭代时需要调整
randIndex = int(random.uniform(0,len(dataIndex)))#随机选取更新
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha*error*dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights随机梯度上升和改进的随机梯度上升算法的dataMatrix传入的都是array类型的参数。
画出决策边界
def plotBestFit(weights):
dataMat , labelMat = loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = [];ycord1 = []
xcord2 = [];ycord2 = []
for i in range(n):
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c = 'red' , marker='s')
ax.scatter(xcord2, ycord2, s=30, c = 'green')
x = arange(0,2.0,0.1)
#g(X) = W0 + W1*X1 +W2*X2,图中的X,Y分别表示X1,X2
y = (-weights[0] - weights[1] * x) / weights[2]
ax.plot(x,y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()结果测试
数据(来源于西瓜书)
0.697,0.46,1
0.774,0.376,1
0.634,0.264,1
0.608,0.318,1
0.556,0.215,1
0.403,0.237,1
0.481,0.149,1
0.437,0.211,1
0.666,0.091,0
0.639,0.161,0
0.657,0.198,0
0.593,0.042,0
0.719,0.103,0测试
dataMat , labelMat = loadDataSet()
weights1 = stocGradAscent1(array(dataMat),labelMat,20000)
plotBestFit(weights1)
weights2 = gradAscent(dataMat , labelMat , 20000)
plotBestFit(weights2.getA())运行结果
梯度上升算法迭代20000次
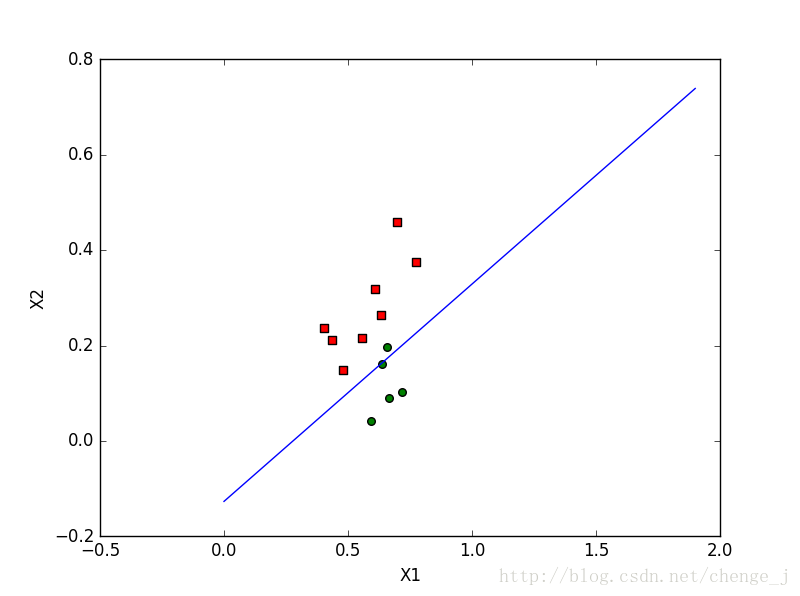
改进的随机梯度上升算法迭代20000次
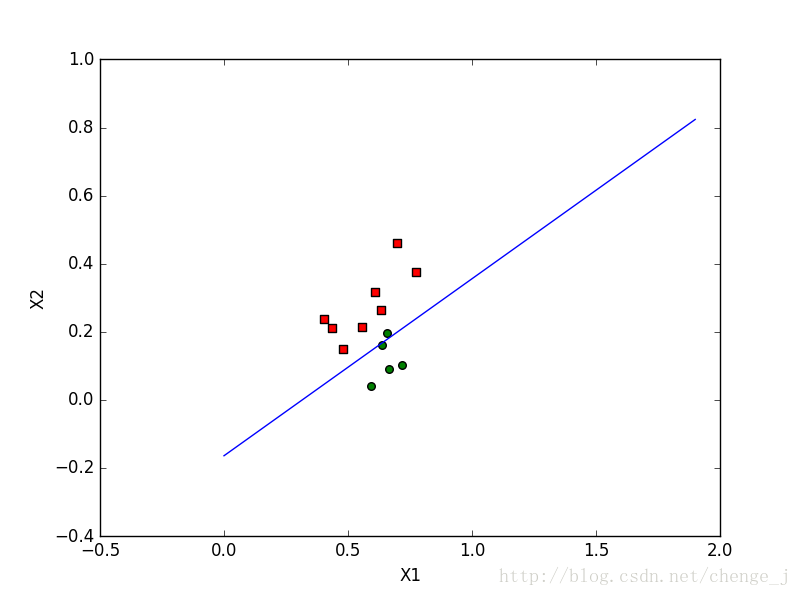
注:本文主要内容来源于Peter Harrington所著的《机器学习实战》

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









