






附录A:分割任何事物的模型和任务细节
图像编码器。 通常,图像编码器可以是任何输出 C×H×W 图像映射的网络。受可扩展性和强大的预训练的启发,我们使用MAE[47]预训练的视觉Transformer(ViT)[33],具有最小的适应性来处理高分辨率输入,特别是具有14×14窗口注意力和四个等距全局注意力块的ViT-H/16[62]。图像编码器的输出是输入图像的 1/16 倍映射。由于我们的运行时目标是实时处理每个提示,因此我们可以提供大量的图像编码器FLOP,因为每个图像只计算一次FLOP,而不是每个提示。
根据实践(例如,[40]),我们使用1024×1024的输入分辨率,该分辨率是通过重新缩放图像并填充短边获得的。因此,图像映射是64×64。为了降低通道维度,在[62]之后,我们使用1×1卷积来获得256个通道,然后使用3×3卷积来获得同样具有256个通道的特征。每个卷积之后都进行归一化操作[4]。
提示编码器。 稀疏提示被映射到256维矢量嵌入,如下所示。一个点被表示为该点的位置的位置编码[95]和指示该点是在前景中还是在背景中的映射的总和。方框由映射对表示:(1)其左上角的位置编码与表示“左上角”的学习映射相加;以及(2)相同的结构,但使用学习嵌入表示“右下角”。最后,为了表示自由形式的文本,我们使用CLIP[82]中的文本编码器(通常可以使用任何文本编码器)。我们在本节剩余部分重点讨论几何提示,并在附录D.5中深入讨论文本提示。
密集提示(即掩码)与图像具有空间对应关系。 我们以比输入图像低 4 倍的分辨率输入掩膜,然后分别使用输出通道 4 和 16 的两个 2×2、步长为2的 卷积再缩小 4 倍。 最终的 1×1 卷积将通道维度映射到 256。每一层都由 GELU 激活 [50] 和归一化层分开。然后逐元素添加掩膜和图像映射。如果没有掩膜提示,则向每个图像映射位置添加表示“无掩膜”的学习映射。
轻量级掩膜解码器。 该模块有效地将图像映射和一组提示映射映射到输出掩码。为了组合这些输入,我们从Transformer分割模型[14,20]中获得灵感,并修改了标准Transformer解码器[103]。
我们的解码器设计如图14所示。每个解码器层执行4个步骤:(1)对令牌(tokens)的自关注,(2)从令牌(tokens)(作为查询)到图像映射的交叉关注,(3)逐点MLP更新每个令牌(tokens),以及(4)从图像映射(作为查询的)到令牌(tokens)的交叉关注。最后一步使用提示信息更新图像映射。在交叉注意期间,图像映射被视为一组64^2 256维向量。每个自/交叉注意力和MLP在训练时都有一个残差连接[49]、归一化和0.1的丢弃[93]。下一个解码器层从上一层获取更新的令牌(tokens)和更新的图像映射。我们使用两层解码器。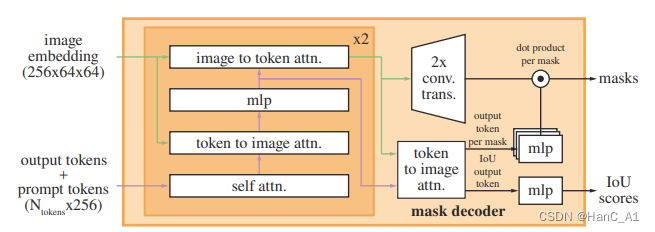
图14:轻量级掩膜解码器的详细信息。两层解码器通过交叉注意力来更新图像映射和提示令牌(tokens)。然后,图像映射被放大,从中更新的输出令牌(tokens)被用来动态预测掩膜。(为图清晰起见,未进行说明:在每个关注层,位置编码都被添加到图像映射中,整个原始提示令牌(tokens)(包括位置编码)被重新添加到令牌(tokens)查询和密钥中。)
为了确保解码器能够访问关键的几何信息,无论何时位置编码参与到注意层中,都会将其添加到图像映射中。此外,当整个原始提示令牌(tokens)(包括它们的位置编码)参与注意力层时,它们都会被重新添加到更新的令牌(tokens)中。这允许对提示令牌(tokens)的几何位置和类型有很强的依赖性。
在运行解码器后,我们用两个转置的卷积层将更新的图像映射上采样4倍(现在它相对于输入图像缩小了4倍)。然后,令牌(tokens)再次参与图像映射,并且我们将更新的输出令牌(tokens)映射传递给小的3层MLP,该MLP输出与放大图像映射的通道维度匹配的向量。最后,我们预测了在放大图像映射和MLP的输出之间具有空间逐点乘积的掩膜。
Transformer 使用256的映射维度。Transformer MLP块具有2048的大内部尺寸,但MLP仅应用于相对较少(很少大于20)的提示令牌(tokens)。然而,在我们有64×64图像映射的交叉关注层中,为了提高计算效率,我们将查询、键和值的通道维度降低了2倍至128。所有注意力层使用8个头。
用于放大输出图像映射的转置卷积为 2×2,步长为 2,输出通道维度为 64 和 32,并具有 GELU 激活。 它们由归一化层分开。
使模型具有模糊意识。 如上所述,单个输入提示可能是模糊的,因为它对应于多个有效掩膜,并且模型将学习在这些掩膜上进行平均。我们通过一个简单的修改来解决这个问题:我们使用少量输出令牌(tokens )并同时预测多个掩膜,而不是预测单个掩膜。默认情况下,我们预测三个掩膜,因为我们观察到三层(整体、部分和子部分)通常足以描述嵌套掩膜。在训练过程中,我们计算真值和每个预测掩膜之间的损失(稍后描述),但仅从最低损失进行反向传播。这是一种常见的技术,用于具有多个输出的模型[15,45,64]。为了在应用程序中使用,我们希望对预测的掩膜进行排序,因此我们添加了一个小头(对额外的输出令牌(tokens )进行操作),用于估计每个预测掩膜与其覆盖的对象之间的IoU。
多个提示的歧义要少得多,三个输出掩膜通常会变得相似。
为了最大限度地减少训练中退化损失的计算,并确保单个无模糊掩膜接收规则梯度信号,我们只在给出多个提示时预测单个掩码。这是通过为额外的掩膜预测添加第四个输出标记(token)来实现的。第四个掩膜从不为单个提示返回,并且是为多个提示返回的唯一掩膜。
损失。 我们用 focal损失[65]和dice损失[73]的线性组合来监督掩膜预测, focal损失与dice损失的比例为20:1[20,14]。与 [20, 14] 不同,我们观察到在每个解码器层之后进行辅助深度监督是没有帮助的。利用IoU预测和具有真值掩膜的预测掩膜的IoU之间的均方误差损失来训练IoU预测头。它以1.0的恒定比例因子添加到掩膜损耗中。
训练算法。 根据最近的方法[92,37],我们在训练期间模拟交互式分割设置。首先,以相同的概率为目标掩膜随机选择前景点或边界框。点是从真值掩膜中均匀采样的。方框被视为真值的边界框,在每个坐标中添加随机噪声,标准偏差等于方框边长的10%,最大为20个像素。这种噪声分布是实例分割和交互式分割等应用程序之间的合理折中,实例分割在目标对象周围产生一个紧密的框,而交互式分割用户可以绘制一个松散的框。
在根据该第一个提示进行预测之后,从先前掩膜预测和真值之间的误差区域中均匀地选择后续点。如果误差区域分别是假阴性或假阳性,则每个新点都是前景或背景。我们还提供了上一次迭代的掩膜预测,作为我们模型的额外提示。为了给下一次迭代提供最大的信息,我们提供了无阈值掩膜,而不是二值化掩膜。当返回多个掩膜时,传递到下一次迭代并用于采样下一个点的掩膜是具有最高预测IoU的掩膜。
我们发现,在8个迭代采样点之后(我们已经测试了多达16个),回报递减。
此外,为了鼓励模型从提供的掩膜中受益,我们还使用了两次以上迭代,其中没有对额外的点进行采样。
这些迭代中的一个被随机插入到8个迭代采样点中,另一个总是在最后。这总共给出了11次迭代:一次采样的初始输入提示,8个迭代采样点,以及两次迭代,其中没有新的外部信息提供给模型,因此它可以学习完善自己的掩膜预测。我们注意到,使用相对大量的迭代是可能的,因为我们的轻量级掩码解码器需要不到图像编码器计算的1%,因此,每次迭代只增加很小的开销。这与之前的交互式方法不同,以前的交互式方法每次优化器更新只执行一个或几个交互式步骤[70,9,37,92]。
训练方法。 我们使用AdamW[68]优化器(β1=0.9,β2=0.999)和线性学习率warmup[42]进行250次迭代,并使用逐步学习率衰减方法。 warmup后的初始学习率(lr)为8e−4。我们训练90k次迭代(~2个SA-1B epoch),并在60k次迭代时将lr降低10倍,在86666次迭代时再次降低。批处理大小为256个图像。为了正则化SAM,我们将权重衰减(wd)设置为0.1,并以0.4的速率下降[53](dp)。我们使用0.8的逐层学习率衰减[5](ld)。未应用数据扩充。我们从MAE[47]预训练的ViT-H初始化SAM。由于图像编码器和1024×1024的输入大小较大,我们将训练分布在256个GPU上。为了限制GPU内存的使用,我们使用每个GPU最多64个随机采样的掩膜进行训练。此外,我们发现,对SA-1B掩模进行轻度滤波,丢弃覆盖图像90%以上的掩膜,可以从质量上改善结果。
对于消融和其他训练变化(例如,文本到掩膜,附录D.5),我们偏离了上面的默认设置,如下所示。
当仅使用来自第一和第二数据引擎阶段的数据进行训练时,我们用尺度范围为[0.1,2.0]的大规模抖动[40]来增加输入。直观地说,当训练数据更加有限时,数据扩充可能会有所帮助。为了训练ViT-B和ViT-L,我们使用180k次迭代,批量大小为128,分布在128个GPU中。对于ViT-B/L,我们分别设置lr=8e−4/4e−4、ld=0.6/0.8、wd=0.1和dp=0.6/0.4。















04-07
 1810
1810
1810
03-27
764
764
04-18
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









