







 本文深入讲解了命名实体识别(NER)中的三种主流方法:BILSTM+CRF、IDCNN+CRF及BERT+BILSTM/IDCNN+CRF,并探讨了提升NER效果的策略。
本文深入讲解了命名实体识别(NER)中的三种主流方法:BILSTM+CRF、IDCNN+CRF及BERT+BILSTM/IDCNN+CRF,并探讨了提升NER效果的策略。
命名实体识别(NER)
命名实体识别(Named Entity Recognition,NER),又叫“专名识别”,从语言分析的全过程来看,NER属于词法分析中的未登录词识别的范畴,命名实体识未登录词中数量最多、识别难度最多、对分词效果影响最大的问题。
命名实体一般包括三大类(实体类、时间类和数字类)和7小类(人名、地名、机构名、时间、日期、货币和百分比)。
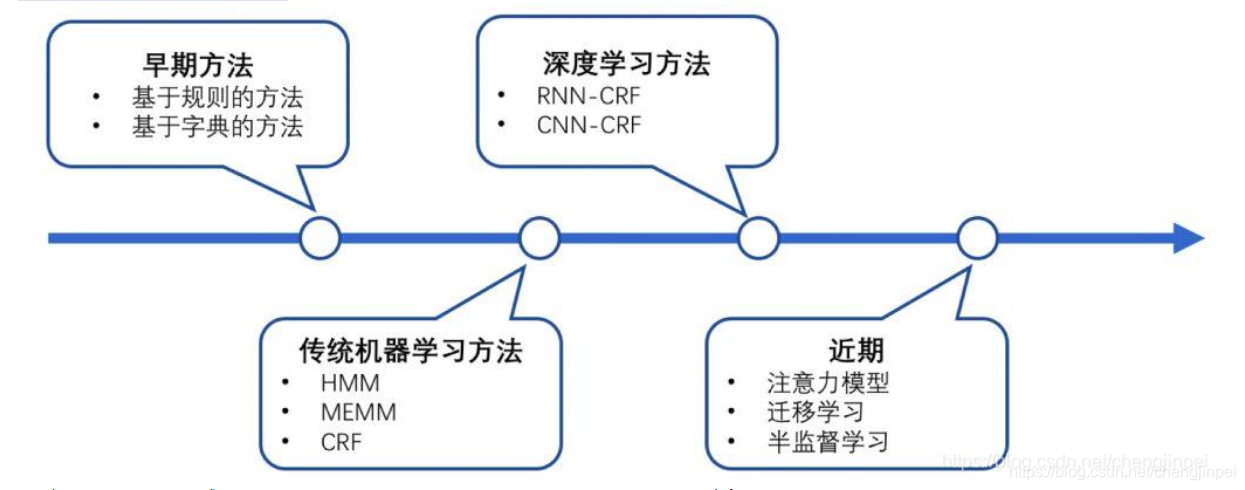
NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示:
目前主流的命名实体识别方法:
- BILSTM+CRF
- IDCNN+CRF
- BERT+BILSTM/IDCNN+CRF
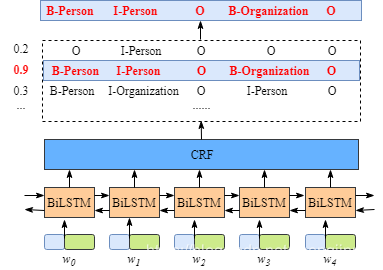
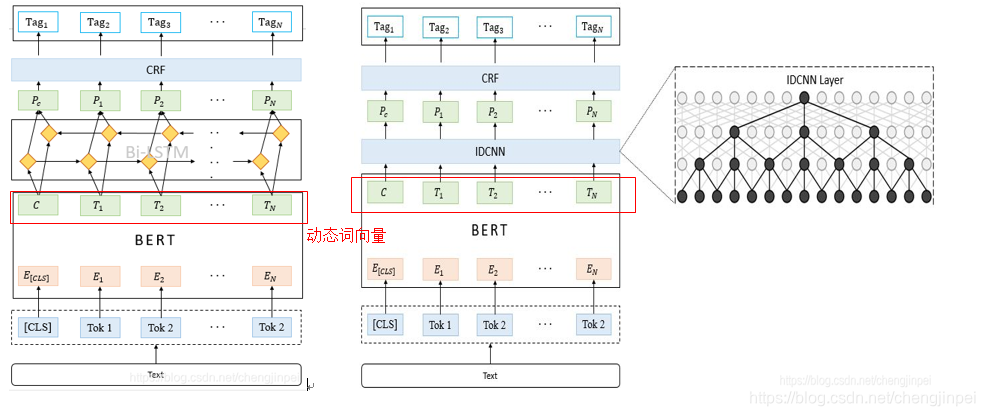
1. BILSTM+CRF
-
BILSTM层的作用
首先BILSTM的输入层为句子中每个单词的表示(包含单词的嵌入和字符的嵌入),其中字符嵌入是随机初始化的,单词的嵌入可以使用现成的预训练词向量,所有的嵌入将在训练过程中进行微调,BILSTM可以学到单词之间的上下文关系,BILSTM层的输出是每个标签的分数,然后将BILSTM层预测的所有分数输入到CRF层中,选择综合预测得分最高的标签序列作为最佳答案。 -
CRF层的作用:
CRF层可以向最终预测的标签添加一些约束,以确保他们是有效的,这些约束可以有CRF曾在训练过程中从训练数据集自动学习。约束的条件可以是:
(1)句子中第一个单词应该是以’B-'或者’O’开头;
(2)在’B-lable,I-lable,…'的模式中,前后单词的lable必须一致,比如’B-PER,I-PER’为合法,‘B-PER,I-ORG’为非法。 -
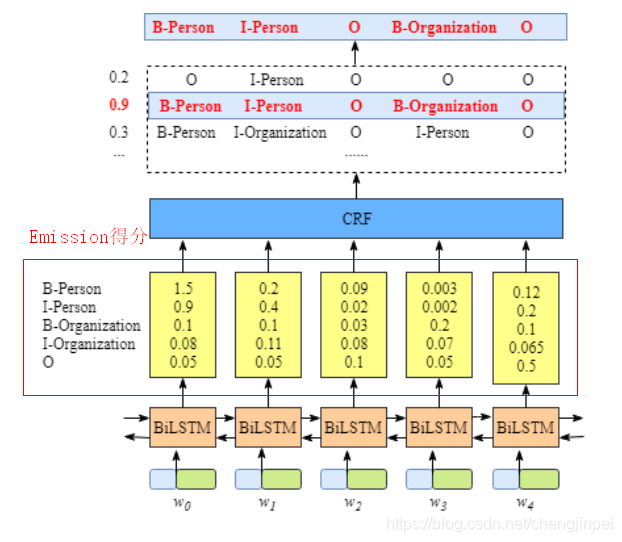
Emission得分和Transition得分
(1)Emission得分
emission分数来自BiLSTM层,表示某个单词预测为各个标签的分数,如下图所示,w0被预测为B-Person的emission分数为1.5,预测为I-person的emission分数为0.9:
(2)Transition得分
Transition得分来自CRF层,是指当前标签转移到下一个标签的分数,如B-person–>I-person的得分为0.9,因此有一个转移得分矩阵,它存储了所有标签之间的所有得分,为了使transition评分矩阵更健壮,我们将添加另外两个标签,START和END。START是指一个句子的开头,而不是第一个单词。END表示句子的结尾。
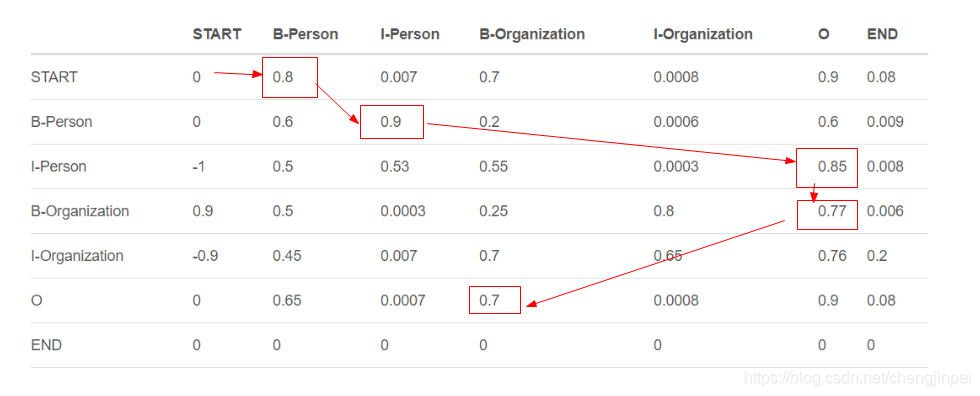
由上述图可知,transition可以学习了一些有用的约束,transition矩阵是BiLSTM-CRF模型的一个参数。在训练模型之前,可以随机初始化矩阵中的所有transition分数。所有的随机分数将在你的训练过程中自动更新。换句话说,CRF层可以自己学习这些约束。我们不需要手动构建矩阵。随着训练迭代次数的增加,分数会逐渐趋于合理。
- CRF损失函数
CRF损失函数由真实路径得分和所有可能路径的总得分组成。在所有可能的路径中,真实路径的得分应该是最高的。
在训练过程中,CRF损失函数只需要两个分数:真实路径的分数和所有可能路径的分数,而且训练的过程中真实路径分数所占的比例会逐渐增加
损失函数定义为:
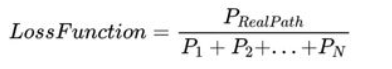
变成log损失:
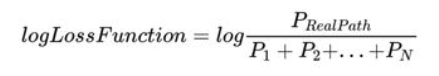
接下来只需要考虑如何计算分母即可,其中每个路径的得分需要计算Emission得分和Transition得分。所有可能路径的得分需要使用到动态规划。首先计算第一个词w0的所有可能路径得分,然后计算w0->w1的总分,最后使用最新的总分计算w0->w1->w2。详细过程这里不再赘述,可以参考这篇文章。
2. IDCNN+CRF
(1)通用的卷积神经网络(CNN)
通用CNN结构通常包括 输入层(input layer)、卷积计算层(conv)、激励层(Relu)、池化层(pooling)、全连接层(FC)。CNN网络相对于LSTM网络可以实现并行计算,因此训练速度更快,但是CNN的中pooling层在增大感受野的同时会损失一部分信息。
(2)膨胀(空洞)卷积神经网络(Dilated CNN)
膨胀卷积的好处是不做pooling损失信息的情况下,增大了感受野,让每个卷积输出都包含较大的信息。该网络在图像需要全局信息或者自然语言处理中需要较长的sequence信息依赖的问题,都能得到很好的应用。
缺点:
- 会丢失局部信息
- 虽然说看的比较远,但是有时候远距离之间的信息之间是不相关的
(3)Dilation CNN解析
Dilation CNN在语音合成的WaveNet、机器翻译的ByteNet的网络中都有用到。Dilation CNN原始论文中的说明图如下:
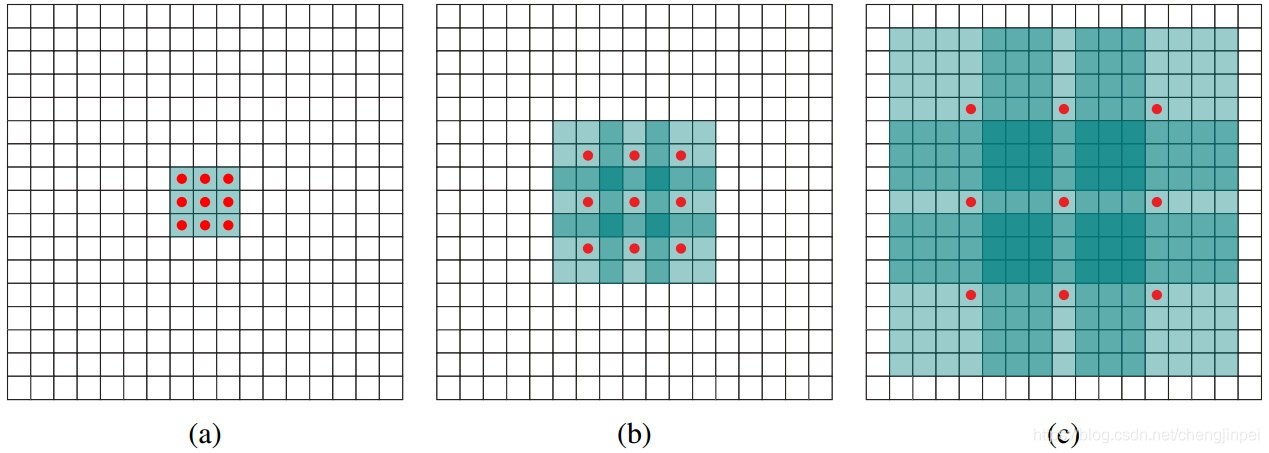
a)图(a)是一个卷积核为3x3,dilation为1的Dilated CNN,和普通卷积神经网络一样,其感受野为3x3
b)图(b)是一个卷积核为3x3,dilation为2的Dilated CNN,此时的感受野变成7x7,但是图中只有9个红点和3x3的卷积核发生卷积操作,其余的点略过(图中9个红色的点的权重不为0,其余全为0),增加dilation参数,感受从3x3变成了7x7。
c)图(c)是一个卷积核为3x3,dilation为4的Dilated CNN,此时的感受野为15x15。
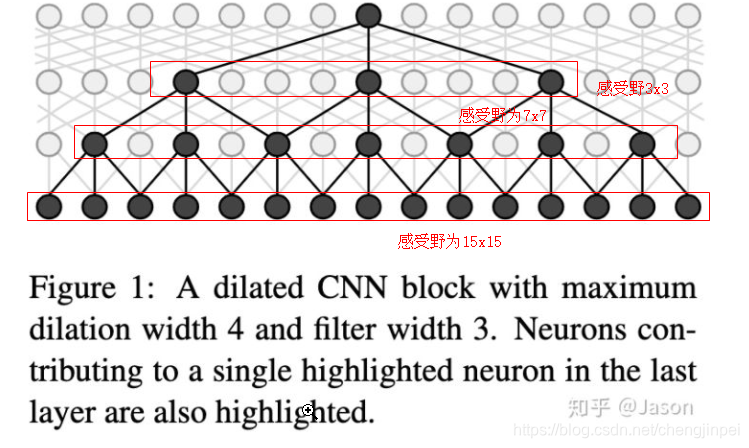
对于传统的CNN来说,3层3x3的卷积加起来,stride为1的话,感受野只能达到(kernel-1)*layer+1 = 7,而dilation CNN的感受野呈指数级别的增长。
(4)IDCNN+CRF
原论文中提出的IDCNN模型是4个结构相同的Dilated CNN模块拼接(concat)在一起,每个模块里是dilation width为1,1,2的三层CNN。IDCNN对输入句子的每一个字生成一个logits,之后和BILSTM模型输出logits之后完全一样,后面喂入CRF层。
3. BERT+BILSTM/IDCNN+CRF
在预训练模型BERT未出现之前,BILSTM-CRF就是一种比较流行的命名实体识别框架,这里将BERT的token向量(即含有上下文信息的词向量)喂到BILSTM/IDCNN中,BILSTM可以进一步提取特征,CRF可以更好的学习到标签之间的约束关系.
一些提升命名实体识别效果方法:
笔者认为提升命名实体识别的效果从输入到输出的角度来说可以分为以下几个部分:
- 输入层:增加词向量或数据特征、数据增强。例如在BERT模型本身使用字符级别的embedding,我们可以将词级别的embedding融入到BERT模型中。发表于ACL2021会议上的ChieseBERT模型就是融合了多种特征(char embedding+glyph embedding+pingyin embedding),感兴趣可以参考文章
- 修改模型的结构或者增加模型的结构:文献[1]提出了添加了GCN结构来捕捉字词间的依赖关系。文献[2]提出了一种基于Lattice LSTM网络的命名实体框架。此类方法有很多,如果感兴趣的话可以参考文章.
- 模型的后处理:比如添加一下规则,例如姓名实体的识别可以添加百家姓词典,地点识别可以添加地理位置词典等
- 其他方法:如可以使用MRC实体的分类的结果与BERT+CRF的模型的实体结果进行配对,将CRF的类别用在MRC的结果上。
参考文献
[1] Cetoli A , Bragaglia S , O’Harney A D , et al. Graph Convolutional Networks for Named Entity Recognition[J]. Context Scout.
[2] Yue Z , Jie Y . Chinese NER Using Lattice LSTM[C]// The 56th Annual Meeting of the Association for Computational Linguistics (ACL). 2018.

















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









