






“ 大模型就相当于厨师,参数就相当于调料。”
不过那个讲的比较抽象,这里就用一个更形象的例子来解释一下大模型的参数到底是什么,以及训练的原理。
01.大模型和厨师
从我们使用者的角度来说,大模型就是一个黑盒,它需要输入,然后给出一个输出。
如下图就是大模型的黑盒模型:
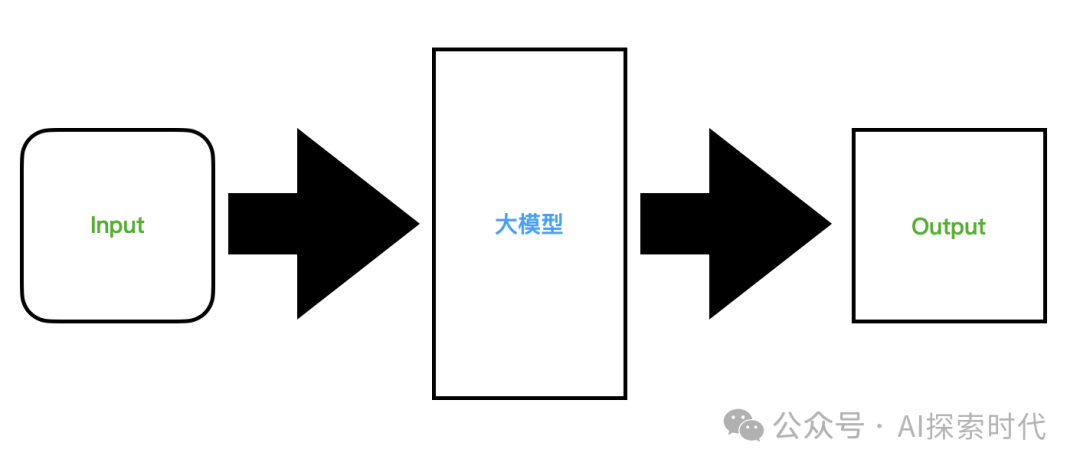
而从我们使用上来看,基本上就是一个聊天框,然后我们输入文字/图片/视频等,然后大模型给我们一个输出。
而这种模式和我们去饭店吃饭一样,我们到饭店之后点菜,然后厨师就会把我们的菜做好,而厨房对我们来说也是一个黑盒。
大模型那么多参数是干什么的呢?厨师又是怎么做菜的呢?
如果把没有训练过的大模型比作一个新东方烹饪学校的学生;那么刚开始这个学生并不会做菜,如果你让他做菜,那么他只能根据自己的感觉乱七八糟的一通操作。
这个就是初始化的大模型,它虽然可以输出结果,但它输出的结果乱七八糟。
所以学生需要去学习怎么做菜;不论会不会做饭的人应该都知道,炒菜需要控制火候与调料,不同的菜需要不同的火候和调料。
火候有大火小火中火,调料有必须的葱姜蒜,还有盐,辣椒,鸡精,麻辣虾,油等等。

做菜的时候,不同的菜需要不同的搭配,而且需要不同的火候和调料;比如,西红柿炒蛋需要有西红柿和鸡蛋,然后调料需要有盐,也可以放葱姜蒜;
而如果做辣椒炒肉,那么就需要有肉和辣椒,然后口味重的人就可以多放一点辣椒和盐,口味清淡的人就可以少放一点。
对比到大模型也是如此,厨师做菜的材料,调料与火候是厨师的参数;而大模型也有自己的参数,比如权重,偏置,卷机网络的卷积核,嵌入矩阵,损失函数参数,激活值,参数梯度,训练轮次等。
从技术等角度来说,大模型的参数就是大模型的一些变量,之所以是变量是因为这些参数的值并不是固定的,而是可以变化的;
就像做菜一样,盐可以多放一点,也可以少放一点;并不是每次必须放多少盐。
02.做菜与大模型的训练
专业的厨师学习做菜时,会测试不同的菜品放不同含量的调料会有什么样的效果,比如放一克盐和放十克盐,放葱姜蒜和不放葱姜蒜在口味上的区别。
然后经过很多次的测试之后,厨师就知道做什么菜需要放多少盐,放多少辣椒,然后口味会是什么样。
而大模型的训练也是如此,大模型是基于神经网络的架构而开发的;而一个大模型有很多神经网络层,每一层又有很多的神经元节点;
那么,不同的神经元节点的权重和偏置,会对其它神经元以及神经层会产生什么样的影响及效果?
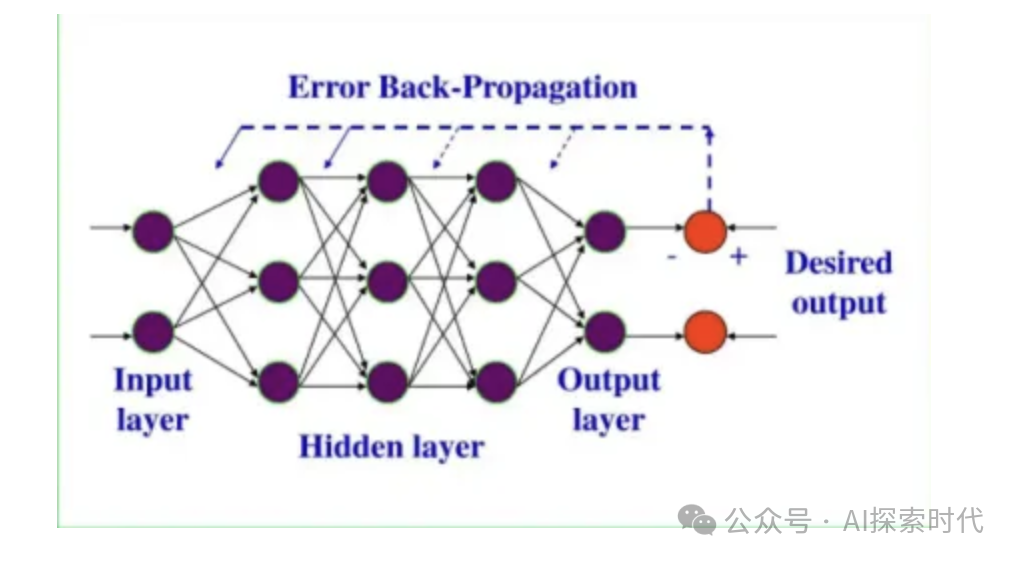
不同神经网络的架构的参数又会有什么样的影响?比如卷积神经网络的卷积层的个数,多一层和少一层的区别?如果是循环神经网络呢?
而这些问题都是需要经过大量的数据训练,然后给大模型找到一个最优的参数值。
而具体怎么训练呢?
比如第一次训练,所有神经元的权重都是1,然后生成了一个结果;这就类似于第一次做菜,所有的调料都放1克,然后做出之后尝尝好不好吃。
而因为神经网络是有层的,这样数据在一层一层神经网络之间的传递就叫做正向传播。
当用1克调料把“菜”做出来之后,尝了一下发现盐放少了;这时第二次做菜的时候,就可以把盐多放一点,比如放四克或五克。

而大模型毕竟不是人,所以需要有一个方法来测试它做的“菜”是否合格,而这个东西就是损失差,损失差越大,说明输出效果越差,“菜”做的越差。
而具体的损失差怎么计算,不同的大模型和架构有不同的方法,比如交叉熵损失。
而这时,就需要告诉大模型做的“菜”不好吃,这个告诉的过程就叫做反向传播。
厨师知道菜做的不好吃的时候,就可以直接调整下次放调料的数量和种类;而大模型也有这种类似的功能,这个功能就是优化器,优化器的功能就是去调整大模型的参数,下次把“盐”放多一点,“辣椒”放少一点。
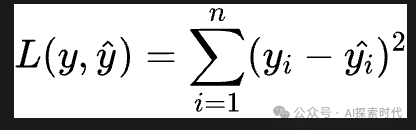
最小二乘法损失函数
而这个盐和辣椒就是大模型中的权重,偏置,损失函数参数等参数。
而训练次数就是厨师锻炼做菜的次数,可能是十次,也可能是一百次,一千次。
所以说,厨师训练是不断的调整其调料的数量和含量;大模型的训练本质上也是在不断的去调整它的参数。
等厨师全部学会之后,还会找一个专业的老师去评价他做的菜;而在大模型里面,这个就是大模型的评估函数,去测试其效果。
当然,大模型并不是参数和训练次数越多越好,最重要的是合适。
这就是大模型的参数以及训练的过程及原理。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1412
1412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









