






- 很早之前就想抓一些壁纸,本人喜欢去看游民星空(一个主打游戏类的综合性网站)。然后很早之前就眼馋它的每周壁纸了,所以这次就将该站的每周壁纸集合中的所有壁纸抓了一下(虽然有打包的可以下,但是还是想尝试一下)。废多不讲~
- 首先介绍一下思路
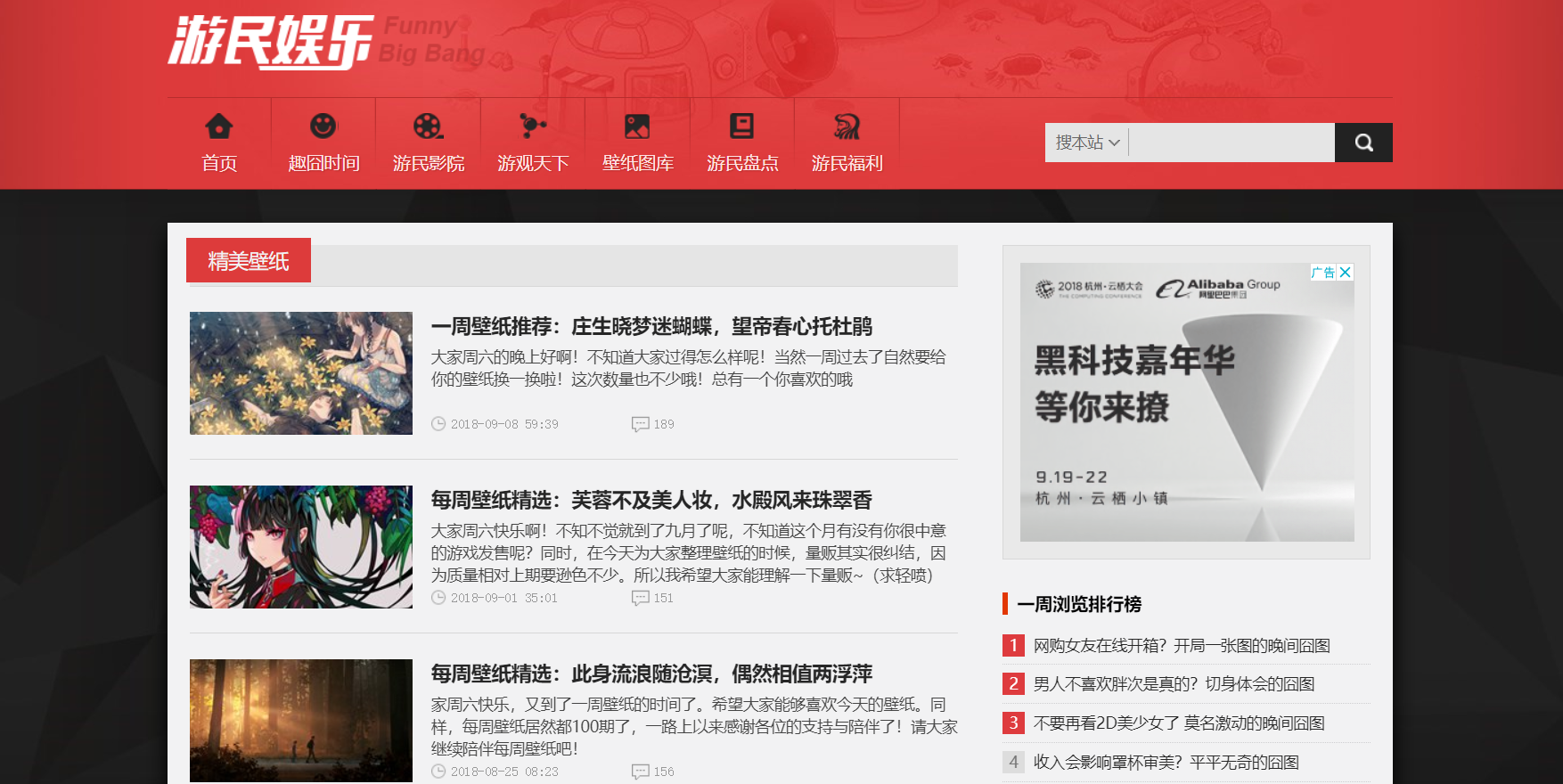
- 一开始我是想从这个页面入手的,但是发现翻页之后url地址是毫无变化的,检查源码之后发现控制跳转的是javascript函数,想了很久也不知道如何解决(无能狂怒),于是想起了该站还有搜索功能。于是乎~
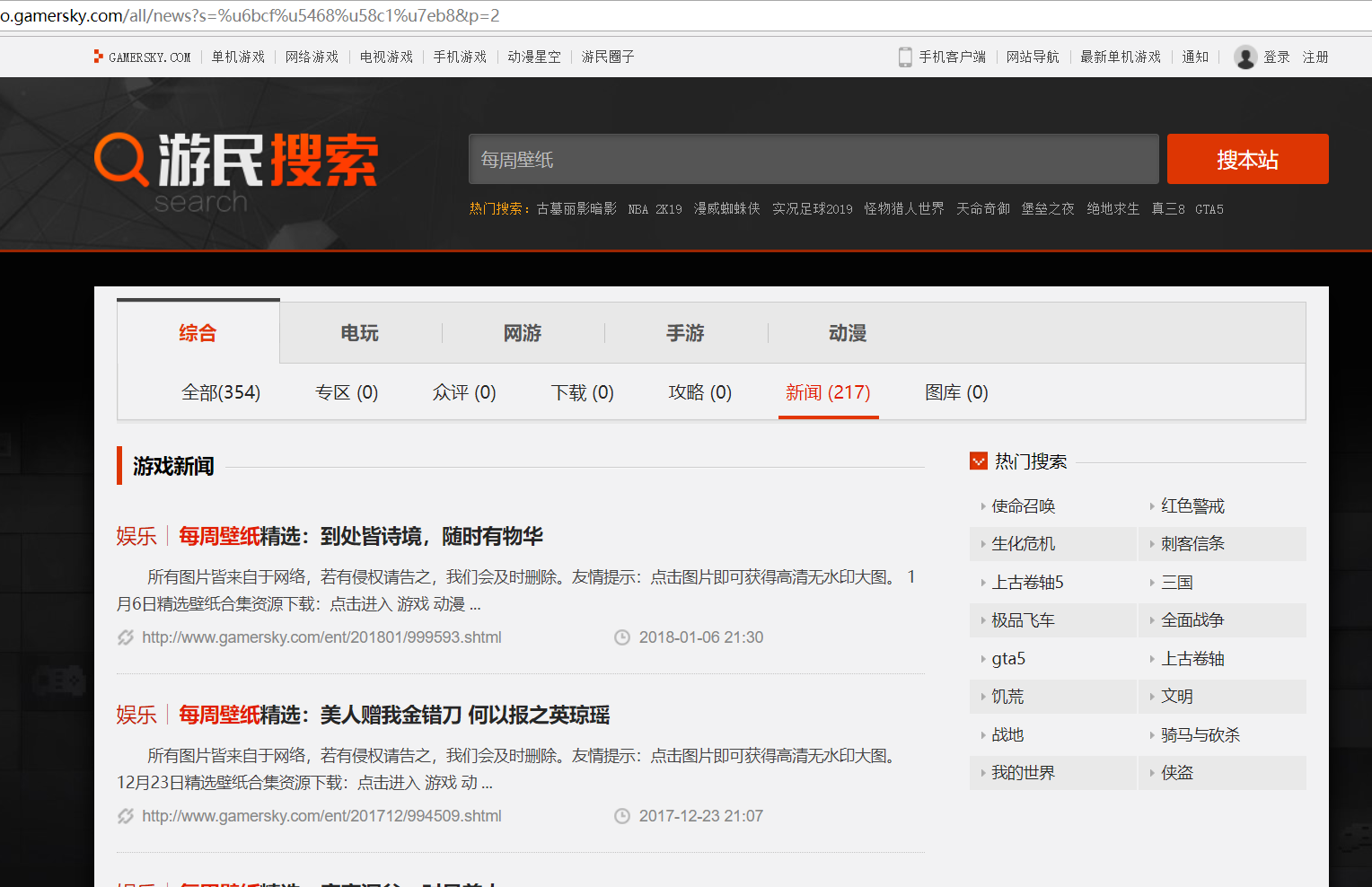
- 发现这样通过修改p的值是可以实现跳页的,于是乎开启了自己的邪恶模式。
- 然后就是下级页面的分析了
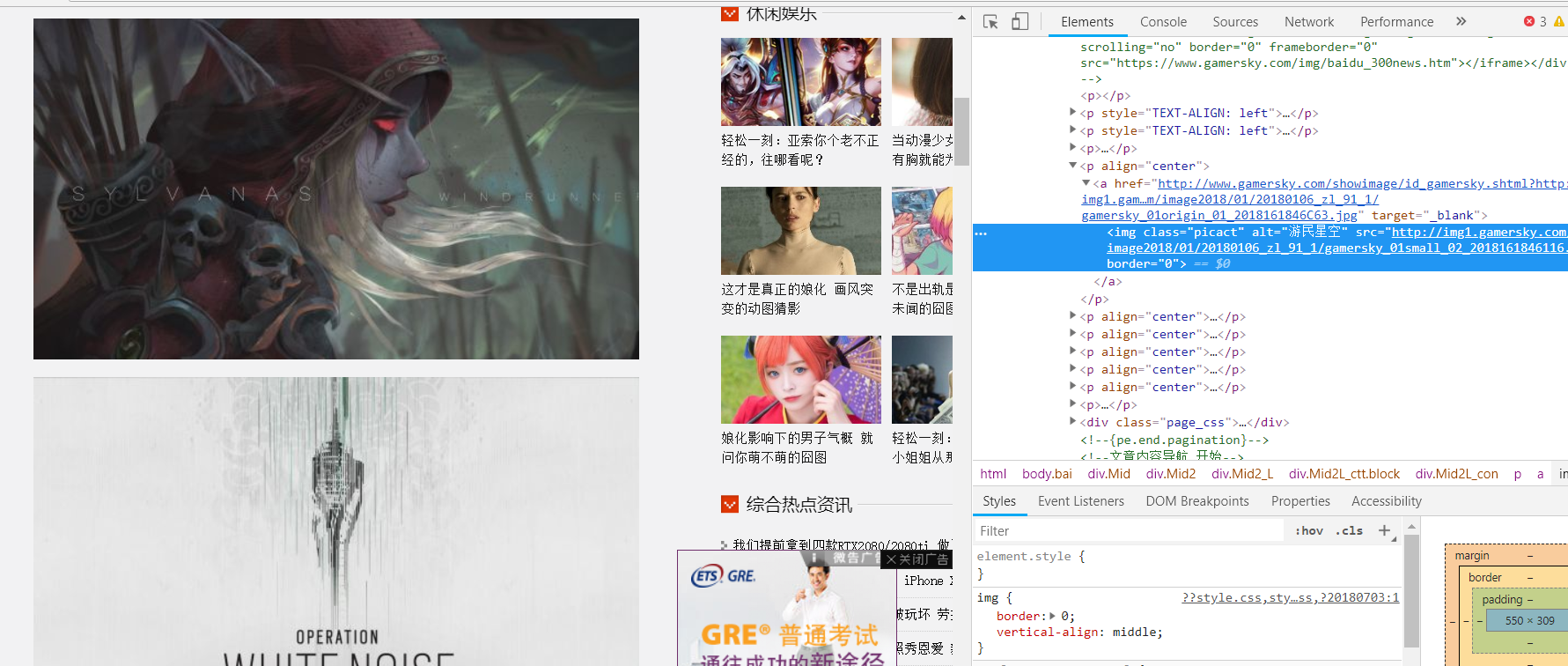
- 该站没有使用ajax异步方式响应,因此容易提取。每张图片的url都有。
- 接下来也是翻页操作。
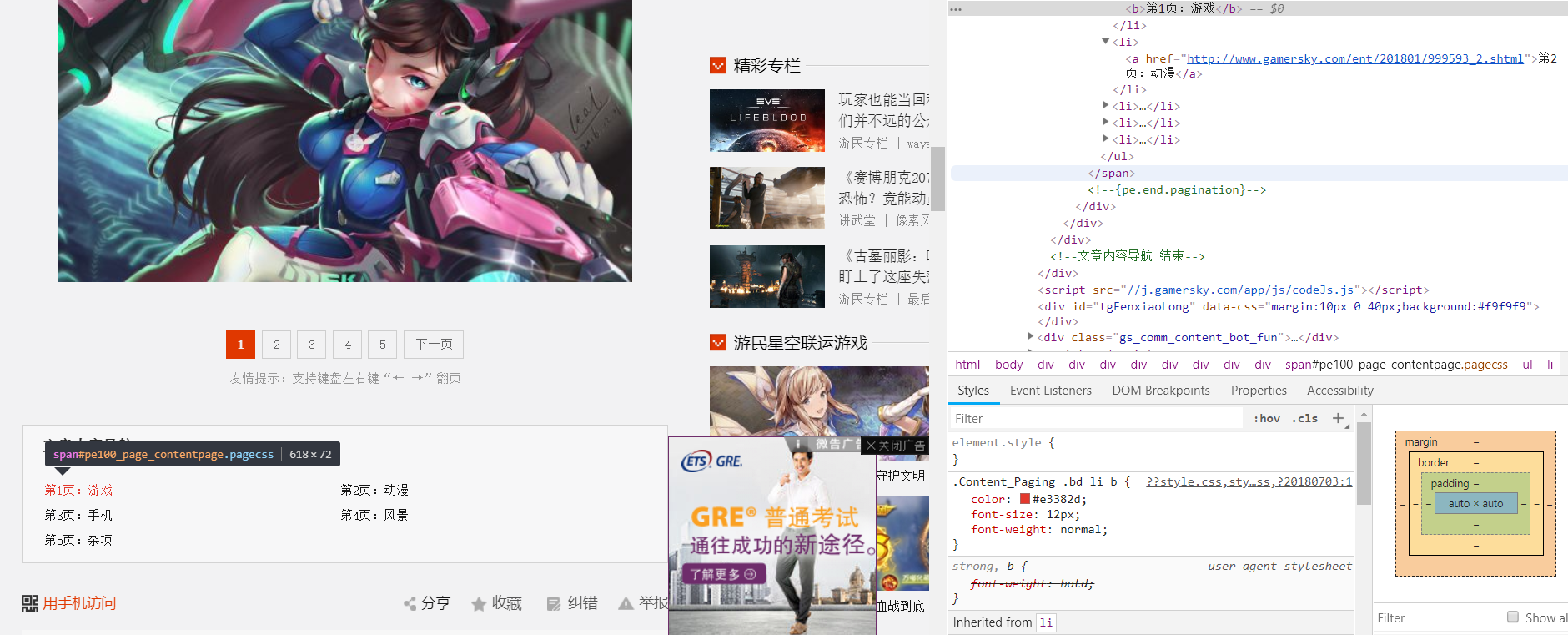
- 因为下面有一个导航,有每一页的链接于是乎,十分的开心,。分页链接也可以拿到~!但是当我拿的时候突然想到,它确实有分页的链接 但是没有本页的,。而且,每一个网页中的总的分页数也不同,于是个人认为,只能将所有的分页的链接拿出来然后再构造Request,没有本页的怎么办,构造一个!于是乎拿出了列表中的第一个元素,然后通过它构造一个起始页的链接,(因为格式一样,只需将url中的某个字符修改了就可以)追加到列表中,然后通过这个列表构造request就可以了(方法很笨,勿喷。。。)
- 图片的详情页
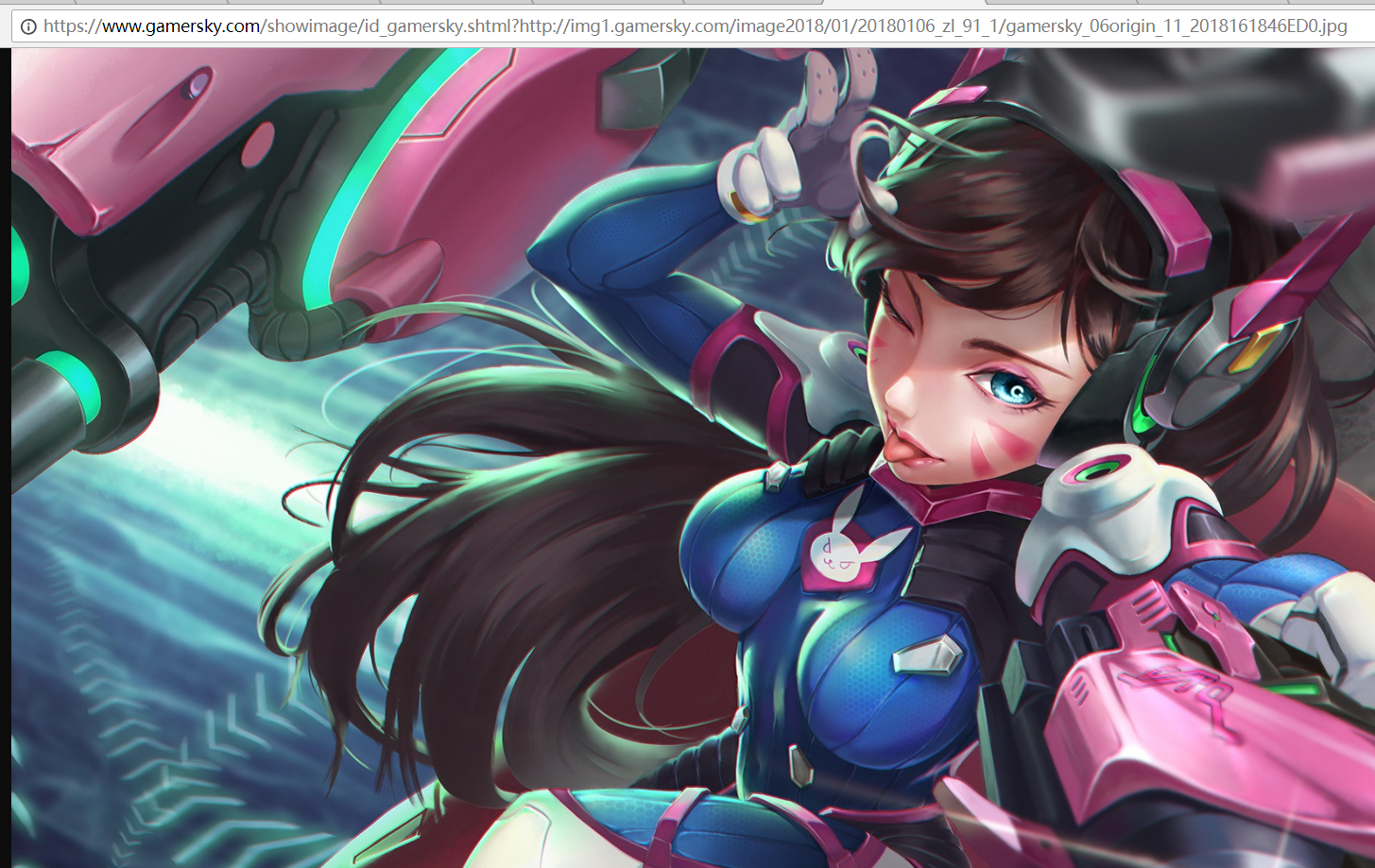
- 我满心欢喜的以为上面列表页中拿到的图片的url就是 真正的url 其实 是错的。。。这样拿到的图片看似是真正的链接了,其实还不是,

- 在这个url中 真正图片的url是?后边那被拼接的一部分
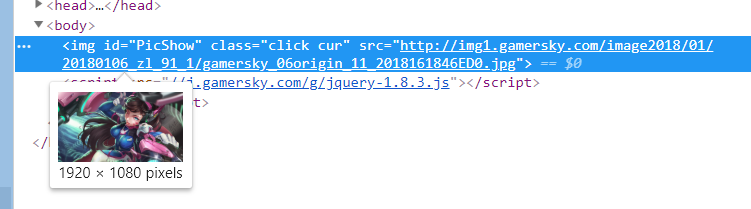
- ok基本就是这样,可能说的比较乱,直接上代码把
-
#爬虫主体 import scrapy from scrapy import Request from GamerSky.items import GamerskyItem class MywallpaperSpider(scrapy.Spider): name = 'MyWallPaper' allowed_domains = ['https://www.gamersky.com/ent/wp/'] start_urls = ['http://so.gamersky.com/all/news?s=%u6bcf%u5468%u58c1%u7eb8%u7cbe%u9009&p=1'] page_list = [] def start_requests(self): #初始请求,其实就是那个输入每周壁纸点击搜索后出来的页面 yield Request(self.start_urls[0],self.parse_wallpaper_list,dont_filter=True) def parse_wallpaper_list(self,response): #对出来的一页一页的列表分页解析 self.page_list = response.css('.txtlist.contentpaging a::attr(href)').extract() for url in self.page_list: yield Request(url,self.parse_detial,dont_filter=True) next_page = response.css('.pagecss a::attr(href)').extract()[-1] #如果下一页的链接成了一个javascript()函数,那证明是最后一页了。可以再最后一页查看该判断标志 #没有到最后一页的话 就递归调用自己,依旧解析每一页中的各项 if str(next_page) != 'javascript:void(0)': url = 'http://so.gamersky.com/all/news' + str(next_page) yield Request(url,self.parse_wallpaper_list,dont_filter=True) def parse_detial(self, response): #详情页,将导航中的链接拿出来做成一个列表一次请求 picture_list = response.css('.Content_Paging .pagecss a::attr(href)').extract() #因为第一页的链接再导航中没有,所以构造一个添加到列表中 s = picture_list[0][-6:-8] picture_list.append(picture_list[0].replace(s,"")) for href in picture_list: yield Request(href,self.get_picture,dont_filter=True) def get_picture(self,response): #解析图片中的详情页,拿出链接之后将以?拼接的链接的后半部分拿出来就是图片地址了 item = GamerskyItem() images = response.css('.Mid2L_con p a[target*=_blank]::attr(href)').extract() for image in images: real_url = image.split('?') item['url'] = real_url[1] print("我们的到的图片链接为:" + real_url[1]) yield item#Item #因为要抓取的只是图片的链接,因此就设置了一个Field() from scrapy import Field,Item class GamerskyItem(Item): # define the fields for your item here like: # name = scrapy.Field() url = Field()#PipeLine #利用继承ImagePipeLine实现图片的下载 from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline from scrapy import Request import logging class GamerskyPipeline(ImagesPipeline): logger = logging.getLogger("GamerSkyPipeLine") def get_media_requests(self, item, info): yield Request(url=item['url']) def item_completed(self, results, item, info): if not results[0][0]: raise DropItem('下载失败') self.logger.debug("下载图片成功") return item def file_path(self, request, response=None, info=None): return request.url.split('/')[-1]#Settings BOT_NAME = 'GamerSky' SPIDER_MODULES = ['GamerSky.spiders'] NEWSPIDER_MODULE = 'GamerSky.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'GamerSky (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) CONCURRENT_REQUESTS = 16 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 0.25 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # 随机延迟,设定随机延迟,使爬虫更像浏览器的行为 RANDOMIZE_DOWNLOAD_DELAY = True # Disable cookies (enabled by default) #COOKIES_ENABLED = False # 日志 LOG_LEVEL = 'DEBUG' # 配置图片保存地址,会自动创建文件夹 IMAGES_STORE = "D:/WallPapers/" # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Language': 'en', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36' } # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'GamerSky.middlewares.GamerskySpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { 'GamerSky.middlewares.GamerskyDownloaderMiddleware': 543, } # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'GamerSky.pipelines.GamerskyPipeline': 300, }没有很好的技术,所以做的很粗糙,壁纸也不太多,运行一会就都抓下来了,反正路还很长,加油吧!
-
结果
-
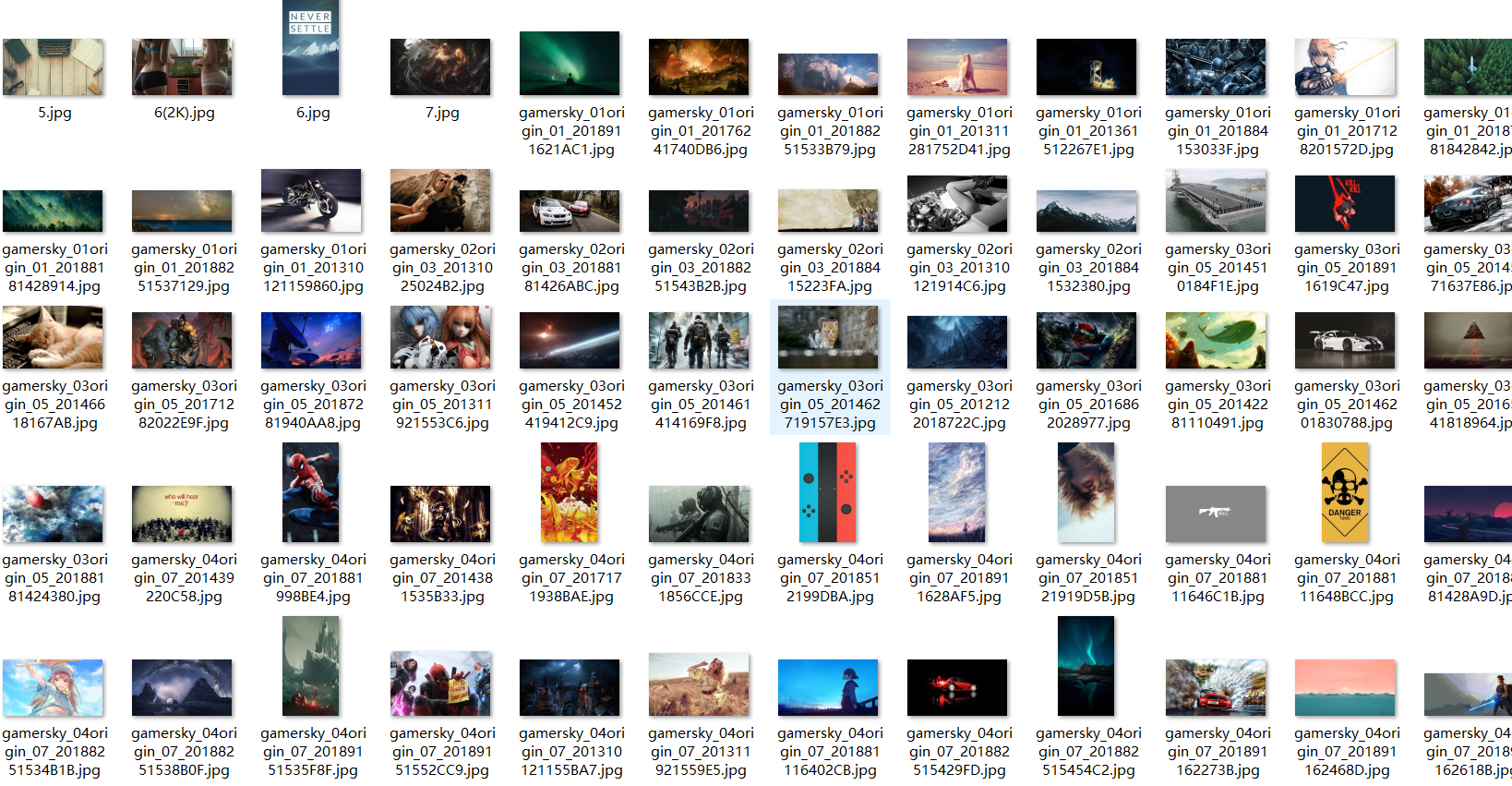
转载于:https://my.oschina.net/u/3900854/blog/2053107















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









