







 AlexNet在ImageNet LSVRC-2010竞赛中取得显著成绩,通过5个卷积层、ReLU激活函数、LRN层、Overlapping Pooling等创新,降低错误率。使用数据增广和dropout防止过拟合,模型包含60M参数,训练使用GPU加速。
AlexNet在ImageNet LSVRC-2010竞赛中取得显著成绩,通过5个卷积层、ReLU激活函数、LRN层、Overlapping Pooling等创新,降低错误率。使用数据增广和dropout防止过拟合,模型包含60M参数,训练使用GPU加速。
AlexNet论文学习笔记
摘要
1、数据:ImageNet LSVRC-2010竞赛的120万张高精度训练图片,1000个类别
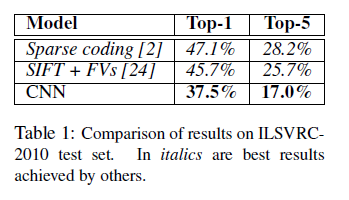
2、结果:top-1 and top-5 error rates of 37.5% and 17.0% which is considerably better than the previous state-of-the-art
3、模型参数:60 million parameters and 650,000 neurons,包括5个卷积层(部分后接max-pooling层),三个全连接层,1000节点的softmax层
4、训练:使用非饱和神经元(非全连接,即局部连接)和GPU加速
5、overfitting:使用dropout减少全连接层的过拟合现象,进行数据增广
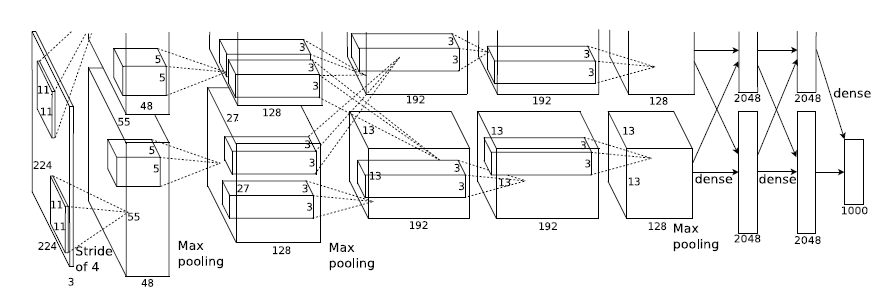
模型结构
使用ReLU替代tanh和sigmoid激活函数
ReLU计算公式: f(x)=max(0,x) ,在训练过程中比tanh快了好几倍。局部响应归一化(Local Response Normalization)
LRN计算公式: bix,y=aix,y(k+α∑min(N−1,i+n2)j=max(0,i−n2)(aix,y)2)β ,帮助提高模型泛化能力。
其中: aix,y 和 bix,y 分别表示LRN前后第i个feature map在位置(x,y)处的值,N为总的feature map数(通道数),n为归一化邻近的feature map数,n、 α 、 β 、 k 为根据验证集确定的超参数,论文中使用k=2,n=5,α=10−4 , and β=0.75 。Overlapping Pooling
传统的Pooling是not overlap的,使用overlapping Pooling(kernel size = 3, stride size = 2)比not overlapping Pooling(kernel size = 2, stride size = 2)top1错误率减少0.4%,top5错误率减少0.3%。总体结构
这里将网络结构分成了上下两层,是为了更好地利用2块GPU进行训练,相当于模型并行的形式,不过现在这种分group的方式已经淘汰。
输入层:3*224*224
conv1+Relu1+LRN1: kernel size 11*11, feature maps 96, stride 4
pooling1: kernel size 3, stride 2
conv2+Relu2+LRN2: kernel size 5*5, feature maps 256, padding 2, stride 1
pooling2: kernel size 3, stride 2
conv3+Relu3: kernel size 3*3, feature maps 384, padding 1, stride 1
conv4+Relu4: kernel size 3*3, feature maps 384, padding 1, stride 1
conv5+Relu5: kernel size 3*3, feature maps 256, padding 1, stride 1
pooling5: kernel size 3, stride 2
fc6+Relu6+Dropout6: output 4096
fc7+Relu7+Dropout7: output 4096
fc8+softmax: output 1000
数据增广
训练时在256*256大小的原始图片及其水平翻转得到的图片基础上随机截取224*224大小的patches,这样相当于使得训练数据量增加到原来的2*(256-224)(256-224)=2048倍。测试时在256*256大小的测试集图片及其水平翻转得到的图片基础上截取四周及中间的patches(总共2(4+1)=10个patches), 10个patches的softmax结果平均后预测最终的结果。
改变RGB通道的强度,文中使用的方法为对通道进行主成分分析(PCA),减少top1错误率达到1%。
学习过程
- batch size 128
- momentum 0.9
- weight decay 0.0005
- SGD更新公式:
- 参数初始化:每层的权重都用均值为0,方差为0.01的高斯分布进行随机初始化,第2、4、5conv层和全连接层的bias初始化为1,其他层的bias初始化为0。
- 学习率初始化为0.01,当cv稳定时学习率除以10,论文中将120万张图片训练了90遍,学习率调整过三次,在两张GTX580上花了5-6天时间。
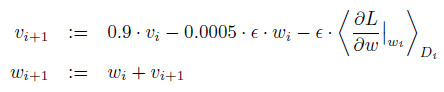















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









