









1.哪吒bert的基本理解
代码的实现连接在https://github.com/chenmingwei00/bert-ner
1.2哪吒主要改进点
哪吒是华为公司针对中文的bert预训练模型,首选感谢华为公司提供了这么好的开源项目,通过对哪吒论文的阅读与理解哪吒的重点主要放在三处改进之处,但是凭自己说这三点都是现成的:
1、Functional Relative Positional Encoding 相对位置编码;
2、Whole Word Masking strategy 全词mask策略,这个和哈工大的差得多,可以看源码;
3、Mixed Precision Training and the LAMB Optimizer 这个操作不作为本文重点。
本文主要是讲解命名实体识别的论文Flat:Chinese ner using flat-lattice transformer怎么结合哪吒bert的结构做命名实体识别。所以主要讲他们的共同之处,其中哪吒的相对位置Functional Relative Positional Encoding与flat是几乎相同的。所以这个作为主要探讨相对位置的命名实体识别的特殊之处。
1.3哪吒的预训练相对位置
在transformer中,每一个头head对序列的操作保持输入与输出的长度,用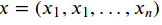 表示输入,用
表示输入,用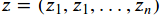 表示输出,每一个head都有三个可训练参数分别用
表示输出,每一个head都有三个可训练参数分别用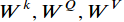 ,后一层i位置的输出如下公式:
,后一层i位置的输出如下公式: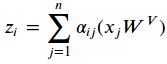 (1)
(1)
也就是当前词汇i的上一层表示是其他词汇的value的加权和, 其中权重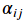 表示的是位置j相对位置i的重要度,用如下公式计算:
表示的是位置j相对位置i的重要度,用如下公式计算:
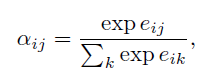 ,(2)
,(2)
此公式可以视为归一化操作,表示所有位置k对位置i的权重为分母,j相对位置i的权重做分子进行权重归一化。其中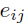 是由其他位置的词向量乘以各自的
是由其他位置的词向量乘以各自的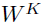 得到各自的关键信息,然后再乘以位置i的
得到各自的关键信息,然后再乘以位置i的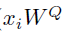 向量作为每一个位置对i位置的重要度。公式如下:
向量作为每一个位置对i位置的重要度。公式如下:
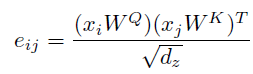 (3)
(3)
由于多头的transformer结构“permutation invariant(排列不变)”针对单词位置顺序不敏感,这句话是非常关键的,也就是说其实针对self-attention,单词的顺序应该并不影响最后attention的结果,但是transformer增加了绝对位置,所以针对这个,也相应缓解了单次顺序的影响。后来提供了参数训练的相对位置的编码,计算相对位置之间的分数视为两个位置之间的距离。那么这种想法基于了公式(1)做了如下更改:
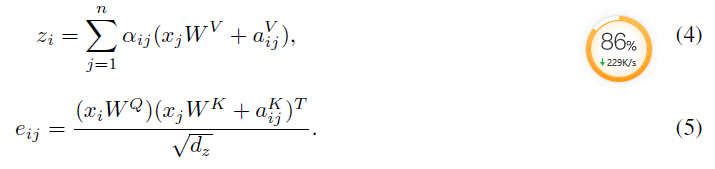
在以上的的两个公式中,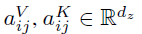 表示位置i和j的相对位置编码信息,表示的是位置差异引起的特征信息,他们在所有head是共享的。Transformer-XL [12] and XLNet [6]对应的位置编码信息的公式不同。哪吒预训练bert就是采用了相对位置编码信息,并且相对位置没有采用可训练方式,而是采用了函数式位置编码策略。公式如下:
表示位置i和j的相对位置编码信息,表示的是位置差异引起的特征信息,他们在所有head是共享的。Transformer-XL [12] and XLNet [6]对应的位置编码信息的公式不同。哪吒预训练bert就是采用了相对位置编码信息,并且相对位置没有采用可训练方式,而是采用了函数式位置编码策略。公式如下:
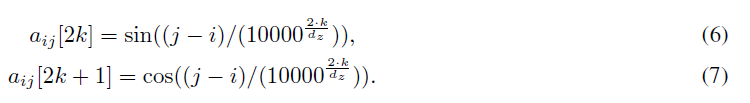
这个就是采用了google的思想,所有从整体上来看,基本没有什么创新,但是结合全词mask,在中文的任务中效果非常不错。
1.4FLAT: Chinese NER Using Flat-Lattice Transformer
本片文章主要讲解的是如何利用中文词汇信息增加到transformer结构中,来解决lattice无法并行batch训练缺陷,按照论文介绍,整个模型结构如下图所示:
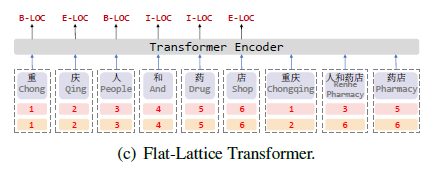
模型结构一目了然,候选中文词汇信息增加到句子最后位置。并且标记每一个词单位的在原始句子中的开始位置head以及结束为止tail,比如图中重庆的开始位置在句子中的位置是1,结束位置是2。针对词汇信息的embedding相对来说比较简单,直接在句子后进行拼接然后参与self-attention即可,但是这样如果预训练的词向量相对语义相对不够明显,词语信息相对于原始句子字符的重要度也就完全没有贡献度,针对以上,作者没有采用绝对位置编码,而是、同样采用了相对位置编码,实质和哪吒采用的方法基本类似,但是在哪吒源码中发现,有一个参数
max_relative_position = 64 ,
也就是针对所有最大位置前后幅度为64,那这样针对本论文的方法就会有限制,如果句子输入过长,就会把词语的相对位置给直接赋值为64,这样位置编码信息也就没有用了,但是整个位置编码的代码基本可以复用,在(二)会详细讲解复现代码。
在图2更加清楚地描述了模型的结构如图:

token就相当于直接拼接,然后针对词语embedding,加入self-attention中,位置信息共形成4个位置信息编码矩阵,分别是head位置信息相对head位置编码相减矩阵、head位置信息相对tail位置编码相减矩阵、tail位置信息相对head位置编码相减矩阵、tail位置信息相对tail位置编码相减矩阵、这四个矩阵就是仿照相对位置矩阵衍生而来,没啥区别。(个人见解,这四个矩阵反而会混淆位置信息),具体的表现形式就是形成了(假设句子长度为max_length)长度为max_length*max_length的方阵,就是两个位置向量按照上面四种方法相减得到,公式如下:
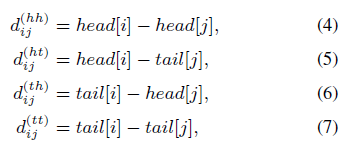
有一部分论文应该解释错误了
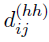 上标写着hh,并且公式(4),也是
上标写着hh,并且公式(4),也是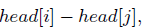 ,所以此处不应该是tail of
,所以此处不应该是tail of 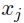 ,所以不知道是怎么审稿的。同理其他的也代表相对位置距离,最后利用
,所以不知道是怎么审稿的。同理其他的也代表相对位置距离,最后利用
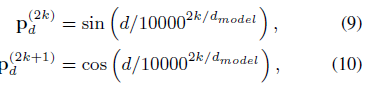
求得每一个相对位置的向量信息,;利用拼接再映射到一个维度得到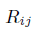 ,剩余的就不在说了。至此整个结合词性的transformer就说明完整了。此想法固然有一定的道理,但是本事复现后,在竞赛https://www.biendata.xyz/competition/ccks_2020_8/,面向试验鉴定的命名实体识别任务,基本不收敛,复现所使用的代码是在哪吒bert的基础上进行的。接下来将详细讲述复现过程,有哪位大牛发现本人与作者复现不同,请指正。当然,其中得到
,剩余的就不在说了。至此整个结合词性的transformer就说明完整了。此想法固然有一定的道理,但是本事复现后,在竞赛https://www.biendata.xyz/competition/ccks_2020_8/,面向试验鉴定的命名实体识别任务,基本不收敛,复现所使用的代码是在哪吒bert的基础上进行的。接下来将详细讲述复现过程,有哪位大牛发现本人与作者复现不同,请指正。当然,其中得到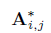 与
与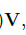 略有不同。接下来就讲解详细过程。
略有不同。接下来就讲解详细过程。
1.5基于哪吒bert的FLAT的复现代码讲解
### 1.5.1 候选词的产生
既然要利用语句中的词汇信息,那么势必要产生训练语句的候选词汇,如果猜错不错的话,本作者使用的代码仍然是lattice lstm作者的代码得到的候选词语。产生候选词语的基本原理是,利用预训练词向量生成词语树,每一个句子从开始位置进行最大匹配的原则,匹配当前字符下的所有词语。
(1) 首先实例化一个Data()类,最主要的代码如下:
self.word_alphabet = Alphabet('word')
self.gaz = Gazetteer(self.gaz_lower)
self.gaz_alphabet = Alphabet('gaz')
主要的这三个初始化,是为了存储总共有多个词汇被匹配到。
Gazetteer类初始化,作用是保存词向量所有词汇,主要初始化了一个Trie,这个就是为了存储词语的树,是为了在训练数据每一个句子中有多少个词语。
class Gazetteer:
def __init__(self, lower):
self.trie = Trie()
self.ent2type = {} ## word list to type
self.ent2id = {"<UNK>":0} ## word list to id
self.lower = lower
self.space = ""
Alphabet是存储匹配训练数据中的所有词汇信息, self.instance2index保存词语对应的下标id,由于训练过程我们使用id映射词向量的。另外一个比较重要的是next_index,初始化为21128,相信用过bert的都知道,原因是bert默认词汇长度为21128,所以匹配对应的词id从21128开始,由于下标从0开始,所以原始的词汇长度最大下标应该是21127,所以我们拼接的id从21128开始。默认增加一个UNKNOWN ,add函数如下
class Alphabet:
def __init__(self, name, label=False, keep_growing=True):
self.__name = name
self.UNKNOWN = "</unk>"
self.label = label
self.instance2index = {}
self.instances = []
self.keep_growing = keep_growing
# Index 0 is occupied by default, all else following.
self.default_index = 0
self.next_index = 21128
if not self.label:`在这里插入代码片`
self.add(self.UNKNOWN)
由于self.instance2index为空,UNKNOWN不在其中,所以UNKNOWN的下标为21128。并且next_index自增1
def add(self, instance):
if instance not in self.instance2index:
self.instances.append(instance)
self.instance2index[instance] = self.next_index
self.next_index += 1
(2)利用本训练数据以及对应的词向量(本次使用的词向量是搜狗预训练词向量) data_initialization(data, gaz_file, train_files, dev_file, test_file)
此函数具体如下
def data_initialization(data, gaz_file, train_file, dev_file, test_file):
data.build_alphabet(train_file)
data.build_alphabet(dev_file)
data.build_alphabet(test_file)
data.build_gaz_file(gaz_file) #加载词向量的全部词汇,转化为id,构建成树tree
data.build_gaz_alphabet(train_file) #利用字符串的拼接在词向量中的个数
data.build_gaz_alphabet(dev_file)
data.build_gaz_alphabet(test_file)
我们能够用到的主要是
data.build_gaz_file(gaz_file) #加载词向量的全部词汇,转化为id,构建成树tree
data.build_gaz_alphabet(train_file) #利用字符串的拼接在词向量中的个数
data.build_gaz_alphabet(dev_file)
data.build_gaz_alphabet(test_file)
由于我们只需要看每一个训练语句中有多少个词汇即可。其中build_gaz_file函数是构建所有word2vec向量的词语树的核心代码。此处不讲解构建树的详细过程,感兴趣的同学可以自行学习。
fin = fin.strip().split()[0]
if fin:
self.gaz.insert(fin, "one_source")
build_gaz_alphabet函数是匹配一个训练语句中能够匹配多少个词汇信息。
data.build_gaz_alphabet(train_file)
详细过程如下:
for line in in_lines:
line=line.strip()
if line!='---':
word = line.split("\t")[0]
if self.number_normalized:
word = normalize_word(word)
word_list.append(word)
#以上过程是生成一个句子list,由于我生成的一个训练语句用'---'隔开
else:
#以下匹配一个句子中有多少个单词并且加入到self.gaz_alphabet中,可以说此变量是
#个字典,包含了所有训练数据预测数据匹配词语的个数
w_length = len(word_list)
for idx in range(w_length):
matched_entity = self.gaz.enumerateMatchList(word_list[idx:])
for entity in matched_entity:
# print entity, self.gaz.searchId(entity),self.gaz.searchType(entity)
self.gaz_alphabet.add(entity)
word_list = []
接下来就是利用生成的词汇对应到词向量中:
data.build_gaz_pretrain_emb(gaz_file) #相当于把对应的预训练词向量对应到训练词汇中,形成训练词汇的词向量embed
其中主要包含两个步骤:
1、加载预训练的词向量,返回词语对应:
embedd_dict, embedd_dim = load_pretrain_emb(embedding_path) # 加载预训练词向量
具体的就是形成字典对应词向量这个目的,具体代码写完博客会公布。接下来就是根据得到的训练数据匹配的词语得到对应的词向量以及对应的ids,这里说明,我们的词向量是拼接到bert词汇之后的,所以开始的下标id=21128,由于bert共有21128个词汇,所以ids范围是[0,21127].
pretrain_emb = np.random.uniform(-0.01,0.01,[word_alphabet.size(), embedd_dim]) # 所有词汇对应的预训练embedding初始化
for word, index in word_alphabet.instance2index.items(): # 此下标从最小21128开始对应此矩阵的0下标所以-21128
index -= 21128 #由于此时初始化并没有增加到bert词汇中,所以应该从0开始表示相对位置
if word in embedd_dict:
if norm:
pretrain_emb[index, :] = norm2one(embedd_dict[word])
else:
if np.max( embedd_dict[word]) > 1 or np.min(embedd_dict[word]) < -1:
embedd_dict[word] = MaxMinNormalization(embedd_dict[word], np.max(embedd_dict[word]), np.min(embedd_dict[word]))
big_value += 1
pretrain_emb[index, :] = embedd_dict[word]
perfect_match += 1
elif word.lower() in embedd_dict:
if norm:
pretrain_emb[index, :] = norm2one(embedd_dict[word.lower()])
else:
pretrain_emb[index, :] = embedd_dict[word.lower()]
case_match += 1
else:
pretrain_emb[index, :] = np.random.uniform(-scale, scale, [1, embedd_dim])
not_match += 1
pretrained_size = len(embedd_dict)
print(("Embedding:\n pretrain word:%s, prefect match:%s, case_match:%s, oov:%s, oov%%:%s" % (
pretrained_size, perfect_match, case_match, not_match, big_value)))
return pretrain_emb, embedd_dim
这样就得到最后匹配的词汇的预训练词汇对应的词向量。















 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









