







引言
如果关注Kaggle 机器学习项目的同学,一定很熟悉人脸关键点检测这个任务,在2013 年的时候,ICML举办一个的challgene,现在放在kaggle 上作为 一种最常规kaggle入门任务而存在。
本文的主要目的在于验证深度学习模型在人脸点检测效果,踩踩里面的坑。
任务介绍
人脸关键点检测,也称之为人脸点检测,是在一张已经被人脸检测器检测到的人脸图像中,再进一步检测出五官等关键点的二维坐标信息,以便于后期的人脸对齐(face alignment)任务。
根据不同的任务,需要检测的关键点数目有多有少,有些仅要求检测2只眼睛的坐标位置,有些要求检测眼睛、嘴巴、鼻子的5个坐标位置,还有更多的,68个位置,它包含了五官的轮廓信息。
如图所示:
根据任务,可以把要学习的模型函数表示为:
其中, X 是输入的人脸图像,
这是一个典型的回归问题,可以采用最简单的平方误差损失函数,然后用机器学习方法学习这个模型。
其中 (xi,yi) 为预测的位置, (xi′,yi′) 为标注的关键点位置。
很显然,也很容易的就将该任务放到caffe中进行学习。
实验过程:
数据准备
由于港中文[1]他们有公开了训练集,所以我们就可以直接使用他们提供的图像库就好了。
数据是需要转化的:
1、框出人脸图像部分,从新计算关键点的坐标
2、缩放人脸框大小,同时更新计算的关键点坐标
3、一些数据增强处理:我只采样了左右对称的增强方法(还可以采用的数据增强方法有旋转图像,图像平移部分)
转换脚本如下:
略数据转化
跟以往的图像分类采用LMDB或者LevelDB 作为数据处理不同,这里我们的标签是一个向量,而不是一个值,所以不能直接用LMDB来作为存储,还好,caffe提供了另外一种数据存储方法来处理这种需求,那就是HDF5, 直观的差别就在于LMDB的标签是一个数,而HDF5 的标签可以是任意(blob),也就是说对于分类任务,我们也可以采样HDF5作为存储的数据模式,但是HDF5直接读取文件,相比LMDB 速度上有所损失。
脚本如下:
略网络结构
数据处理好之后,就可以开始设计网络结构了。
网络结构采样的是参照[1]的网络结构,相比于其它的大型的网络的特点在于:
1,输入图像小。
2,权值非共享。
这样的网络相比ImageNet 上的那些模型的优点很明显,参数比较少,学习相对快一些,
图片1:是论文中描绘的网络结构:
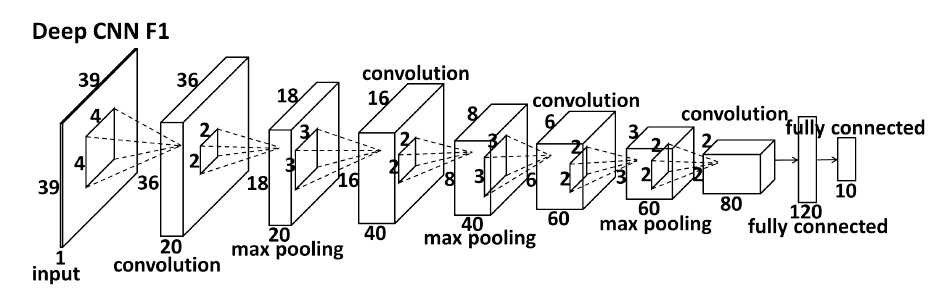
图片2:是caffe实现的网络结构:
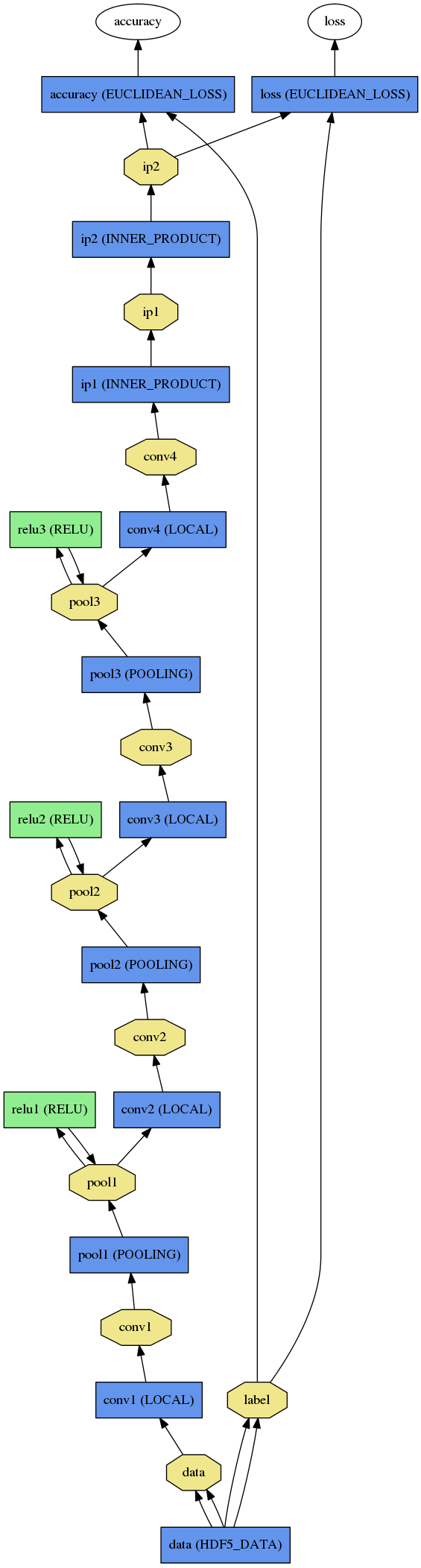
需要注意的是,caffe 的master分支是没有local 层的,这个local 层去年(Caffe Local)就已经请求合并,然而由于各种原因却一直未能合入正式的版本。大家可以从上面那个链接里面clone 版本进行实验。
实验结果
正确的结果

失败的结果
//update 2015.11.19://由于之前实验人脸镜面对称的时候,没有将左右眼睛和嘴巴的坐标也对换,导致嘴巴和眼睛都不准的情况出现。感谢 @cyq0122 指出
实验分析
用深度学习来做回归任务,很容易出现回归到均值的问题,在人脸关键点检测的任务中,就是检测到的人脸点是所有值的平均值。在上面失败的例子中,两只眼睛和嘴巴预测的都比较靠近。//修正bug 过后就不会出现这个问题了。
这篇文章中,我只是尝试复现人脸关键点检测文章[1]的第一步,后面有时间的话,也会考虑用caffe 复现所有的结果。
要想完全的复现文章的结果,还需要:
1,级联,从粗到细的检测
2,训练多个网络取平均值(各个网络的输入图像块不一样)
代码托管
DeepFace GitHub 托管 欢迎提改进建议~
//update 2015.11.18:添加了数据处理的python文件。
引用
[1] Y. Sun, X. Wang, and X. Tang. Deep Convolutional Network Cascade for Facial Point Detection. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013.















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









