







 本文介绍了一种针对电动自行车充电行为的非侵入式识别方法,通过特征选择降低冗余度,利用OCSVM和增量学习提高辨识精度。通过半监督Fisher计分和MIC评估特征,最终实现在线学习与高精度辨识。实验证明了算法的有效性和实用性。
本文介绍了一种针对电动自行车充电行为的非侵入式识别方法,通过特征选择降低冗余度,利用OCSVM和增量学习提高辨识精度。通过半监督Fisher计分和MIC评估特征,最终实现在线学习与高精度辨识。实验证明了算法的有效性和实用性。
目录
1. 前言
本文是对以下论文的解读笔记。注意在下文中“该论文”和“本文”是指向不同的对象。文中着色高亮部分为一些有疑问的地方或者本文作者所加的解读comment。最后一章也给出了本文作者的关于这个问题的一些思考。
施雨松等:基于特征选择与增量学习的非侵入式电动自行车充电辨识方法, 电力系统自动化 Vol.45 No.7 Apr.10.2021
论文摘要:为实现从电网侧监测电动自行车违规停放充电行为,减少电动自行车充电火灾事故,在非侵入式负荷识别的基础上,提出一种基于特征选择与增量学习的电动自行车充电辨识方法。首先,根据电动自行车充电实测电流波形,分析负荷特性并列举15种负荷特征。通过半监督Fisher计分与最大信息系数(MIC: Maximal Information Coefficient)量度特征辨别度与冗余度,采用贪心搜索算法对特征重要性排序并结合排序与辨识结果选择辨识准确性最高的特征子集。然后,基于一类支持向量机增量学习方法,实现电动自行车负荷辨识与分类器在线学习。最后,通过实测数据进行试验,结果表明文中方法可以对电动自行车充电行为准确辨识,验证了算法的有效性。
2. 背景
近年来,电动自行车成为城镇居民短途出行的主要交通工具之一,同时其相关安全问题也日益突出,其中电动自行车引发的火灾呈多发、频发趋势。2018 年,公安部发布《关于规范电动车停放充电加强火灾防范的通告》,明确指出规范电动自行车停放充电行为,严厉查处违规停放充电行为,严禁在建筑内的共用走道、楼梯间、安全出口处等公共区域以及个人房间内为电动自行车充电[1]。严格监管电动自行车充电行为可以有效减少火灾事故,但由于电动自行车充电行为存在随机性、隐蔽性(用另一个专业术语来说叫做“非合作性”),仅依靠人力巡查电动自行车违规停放充电行为,效率低并且漏检率高。随着智能电网技术的快速发展,基于非侵入式负荷监测与分解方法实现电网侧电动自行车充电行为辨识具有良好的发展前景。
到目前为止的NILM的研究主要针对多类电器负荷分解,尚无针对电动自行车或一类异常电器的辨识方法研究。
本文以非侵入式负荷监测为背景,针对电动自行车充电一类负荷,采用半监督特征选择方法,分析15 类负荷特征的辨别度与冗余度,基于贪心搜索与一类支持向量机(one-class support vector machine,OCSVM)进行排序并提取分类正确率最高的特征子集。考虑电动自行车品类繁多但每户电动自行车数量较少,结合增量学习与OCSVM 进行识别过程中的在线学习,在保持泛化能力的同时加强针对性。
非侵入式负荷识别的关键步骤为事件检测、特征选择和负荷识别。当然,通常在事件检测之前还有一个数据预处理的步骤。本文主要聚焦于特征选择和负荷识别这两个阶段。事件检测与常规的NILM是共通的。
In short, 本论文的精华就是以下三个要点:
- 特征子集的选择:子集辨别度最大化与子集冗余度最小化之间的折衷
- OCSVM算法
- 增量式学习
3. 电动自行车充电负荷特征
3.1 特征分析
不同的电器拥有不同的负荷特征。居民用电电压较为稳定,负荷特征差异主要体现在电流波形不同,电动自行车充电实测电流波形如图1 所示。
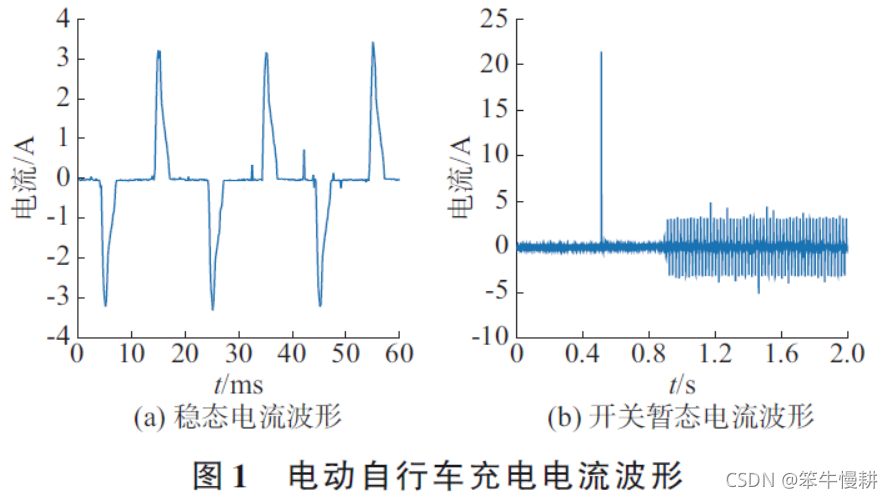
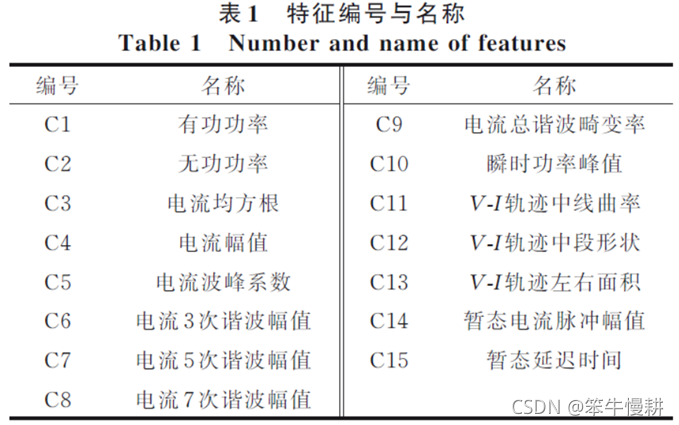
与普通各类家用电器电流波形相比,电动自行车充电电流波形非线性程度较大、畸变严重,瞬时功率峰值较高,启动时有短时的脉冲电流与延迟时间。为了具体反映负荷特性,本文选取了15 个负荷特征作为初始特征集,特征提取方法不再详述,特征编号与名称如表1 所示。
以上特征中C11~C13 为V-I 轨迹的3 个量化参数,V-I 轨迹是以一周期的电压与电流标幺值分别作为横、纵坐标绘制的曲线。V-I 轨迹可以有效反映电力电子型负荷特性,其中C11 表征负荷非线性程度,C12 体现负荷内部元件的导通性,C13 表示负荷电流与电压峰值相位差。电动自行车V-I 轨迹如图A1 所示。
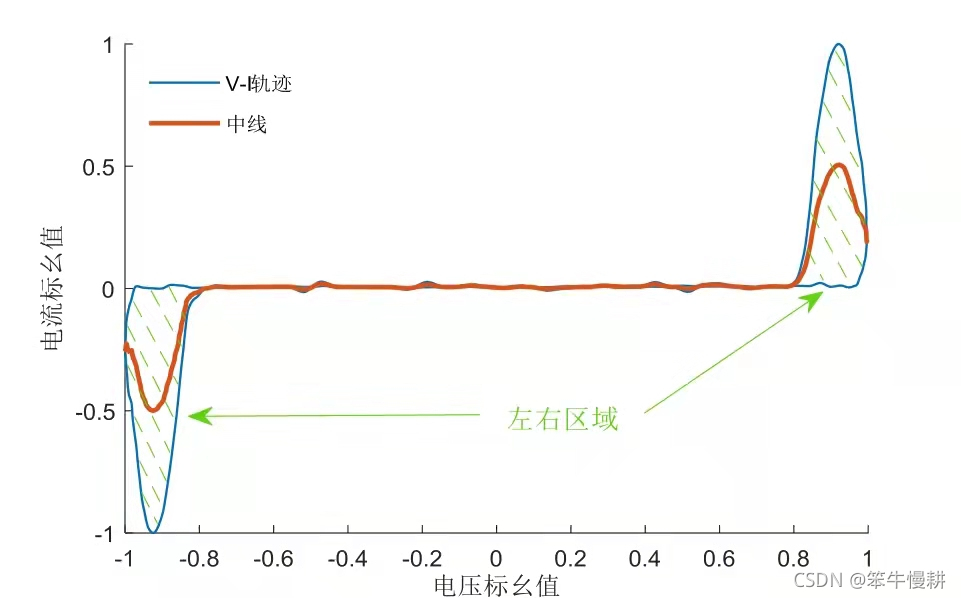
图A1 电动自行车V-I轨迹图
3.2 排序与选择
负荷辨识并非特征类型越多越好,其中辨别度较低的特征会干扰判别,冗余度较高的特征集难以有效提高辨识精确性,同时又增加了计算成本。因此,需要选择辨别度高、冗余度低的特征子集作为辨识依据。
本论文基于半监督Fisher计分和最大信息系数,以辨别度最大、冗余度最小作为目标从上节所示15个候选特征中选取合适的子集,其过程如下所示:
第1个选择的特征F1按如下方式选取:
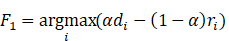
其中di为第i个特征的辨别度,本论文中选用前述半监督Fisher计分来表征特征的辨别度;ri表示第i 个特征与其余所有特征的冗余度均值,本论文中选用最大信息系数(maximal information coefficient,MIC)来衡量两个特征之间的相关性(也即它们之间的冗余度,比如说相关性为1表示由其中一个完全可以推得另一个,那么作为辨识特征来说其中有一个就是完全冗余的)。
第n(n>1)个选择的特征Fn为:
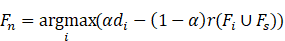
式中:Fs 为已入选特征子集;r(Fi∪Fs)为第i个特征与已入选特征的冗余度均值.
以上选择过程得到了一个按照辨别度从高到低的有序的特征子集。然后分别基于特征子集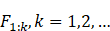 进行训练并测试,得到在识别性能与子集大小之间取得最佳trade-off的最优特征子集。
进行训练并测试,得到在识别性能与子集大小之间取得最佳trade-off的最优特征子集。
以上描述中“半监督Fisher计分”和“最大信息系数”。。。呃。。。一知半解所以暂时略过,等补完课搞明白了再来报告^-^.
4. OCSVM
本论文把电动自动车充电识别看作是一分类问题,即判断“是”还是“不是”。把没有电动自行车充电时的日常家用电器工作的状态定义为“negative”状态,而电动自行车充电叠加在日常家用电器工作的状态定义为“positive”状态(当然,反过来定义也可以)。OCSVM算法的目标就是要在发生电器投入事件(注意,在本问题中其实不太需要关心切出事件。毕竟检测的目的在于及时提出警告并中止充电行为)时,识别出当前投入的电器“是电动自行车”还是“非电动自行车”。
关于OCSVM的介绍有很多参考文献和网络资源(比如说,我之前写的以下两篇博客(Ref1, Ref2),其实就是为了解读本论文而做的准备工作^-^),本文重点不在这里,所以这里就不再赘述了。
5. 增量式学习
笼统地说,增量学习是指算法在保留已有知识的同时不断从新样本中学习新的知识。
OCSVM本身并不具备增量学习能力,基于协同训练思想,结合OCSVM和增量学习的电动自行车充电辨识的学习过程如下:
假设电动自行车初始训练样本集为L,x 为此刻从用户总线提取到的未知标签的负荷样本。
从训练样本集L 中可重复取样得到3 个训练样本集L1、L2 和L3,分别通过核函数不同的OCSVM1、OCSVM2 和OCSVM3 训练得到3 个不同的分类器Model1、Model2 和Model3。
3 个分类器对样本x 进行辨识分类,采用集成学习中的多数投票(任意2 个分类器分类结果相同)判断是否为电动自行车负荷样本。
若样本x 被确认为电动自行车负荷样本,则只保留3 个训练样本集的支持向量,并增加样本x 构成新的训练样本集L′1 、L′2 和L′3,然后利用更新后的训练样本集重新训练,从而更新3 个分类器。
若样本x 被确认为不是电动自行车负荷样本,则等待下一样本。
如此每次获得新的负荷样本时重复迭代更新3 个分类器,实现增量学习。更新训练样本集时,只保留支持向量,可避免新增样本积累导致训练计算量剧增,同时保留泛化能力。
【问】为什么要采取增量学习过程呢?
初始训练是离线式训练,训练集只包含有限种类的电动自行车的有限样本数据,而实际上各家各户的电动自行车(如果有的话)型号可能千差万别。所以不太可能基于初始样本集训练出来的模型能够取得较好的识别效果。利用增量学习可以在监测终端安装以后根据新的数据样本再对当前家庭进行针对性的在线学习。
6. 实验验证
6.1 样本采集和事件监测
为验证本文方法的有效性,在实际家庭入户总线处同步采集电压、电流数据(采样率是多少?只采集电流和电压的话,功率类信息就根据瞬时电流、电压进行计算?)。测试过程中记录电动自行车负荷接入时间(有标记)。其他家用电器在测试过程中随机开关且不记录接入时间(无标记)。同时,本文算法是对电动自行车充电负荷接入事件的监测,只需要用到其开启1 s 内的电压、电流数据。实验时经观察发现,同一电池在其电量不足和满电状态下充电,开启瞬间的电流波形是相近的,经过几秒后才进入稳定状态,因此可以不用考虑电池在充电过程的不同阶段充电电流均存在不同的问题。
本文通过滑动窗双边累积和算法(参见Ref)进行事件检测,采用有功功率作为检测信号(如上所述,有功功率应该是根据所采的电流、电压数据进行计算而得)。某次实验中,用户入户线处测得的有功功率信号,即事件检测算法的检测信号如附录B 图B2 所示,可见居民用户有功功率波动较小,电动自行车充电负荷接入时功率有明显的阶跃(但是,从下图怎么能看出这点来呢?存疑)。根据实际调试情况设置相关参数如下:平均值计算窗口长度Nm=6,暂态过程检测窗口长度Nd=4,噪音β=10,阈值h=120,可有效减少其他负荷噪音干扰。本文仅关注电动自行车负荷接入事件检测的准确性,根据检测统计结果,事件检测算法的电动自行车负荷接入事件漏检率低于0.5%,且得到的事件发生时刻准确,时间偏差不大于0.1s(所以,推测采样率应该至少为数十Hz吧)。利用事件发生时刻前后采样数据提取负荷特征并形成负荷样本,分为有标记样本(电动自行车)与无标记样本(其他家电)。
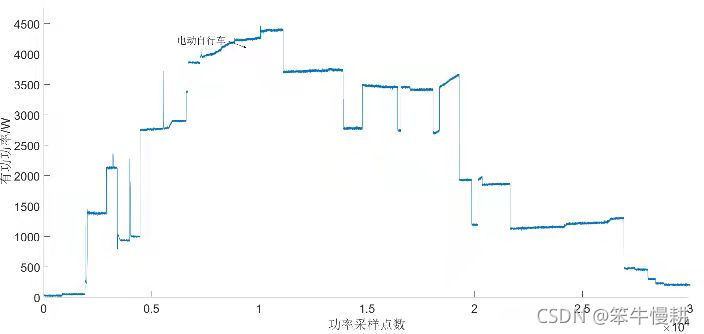
图B2-有功功率信号
6.2 特征选择
基于前面第三章所述方法进行特征排序和特征子集选择。样本数量100,包括30个有标签样本(对应电动自行车充电投入事件)和70个无标签样本(对应其它事件),划分为训练集和测试集(其中有标签样本比例均与原样本集相同),测试集中各类型号的电动自行车和家电样本所占比例与原始采样样本集分布基本一致。标准Fisher 计分与半监督Fisher 计分的15 个特征的辨别度计算结果对比如图2 所示。
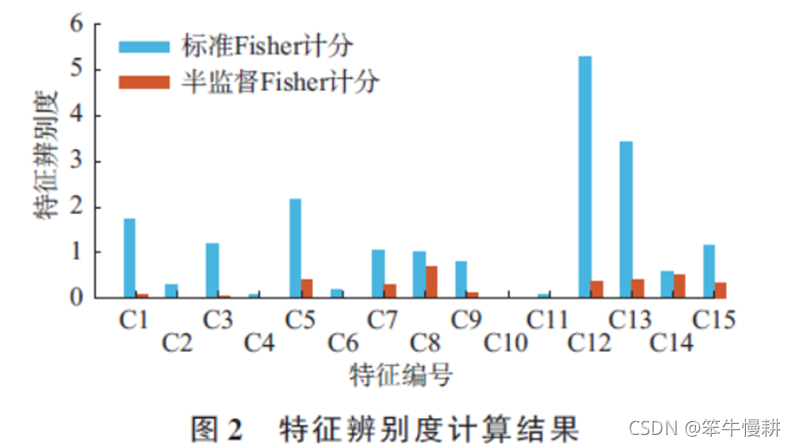
由上图可知,半监督Fisher积分的分辨度远远好于标准Fisher计分,其中C12的辨识度最高(疑上图颜色标识错误,是不是恰好相反啊?从图中来看难道不是标准Fisher计分的特征辨识度要远远好于半监督Fisher积分嘛?)
基于MIC 进行特征集冗余度量度,测试样本集与上文相同,计算结果为15 阶矩阵,表示15 类特征之间的相关程度。根据特征辨别度与冗余度计算结果,基于贪心搜索算法进行特征排序,其中参数α 为0.5。然后基于OCSVM训练结果可以得到如下图所示结果:
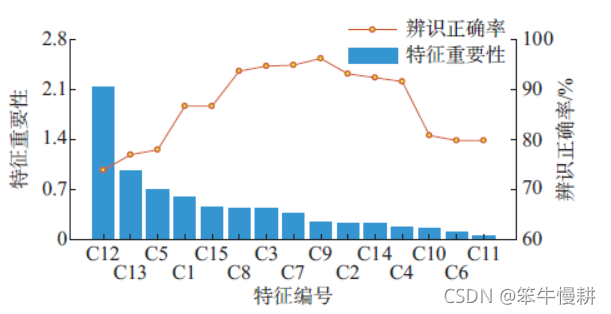
图3 特征排序及辨识结果
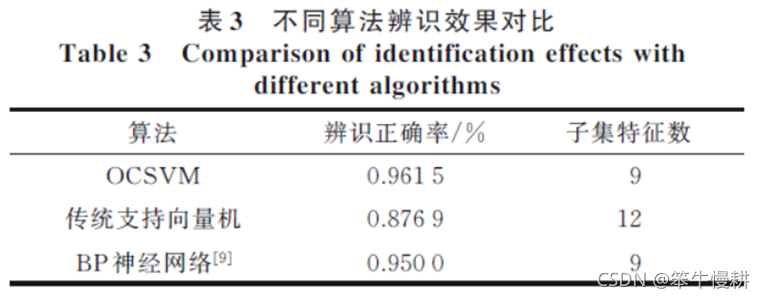
由上图可知,最优特征子集的大小为9,即取特征辨识度从高到底的9个特征作为特征子集时的辨识性能最好,此时辨识正确率达到96.15%。作为对比,论文还将以上方法与传统的SVM模型以及BP神经网络模型进行了对比,结果表明本论文所推荐的方法综合表现最优(虽然仅比BP神经网络模型只是稍好一丢丢^-^,所以是否适合于实际工程应用还要看实现复杂度等其它方面的因素)。
6.3 增量学习及负荷辨识验证
根据第5章所述方法实施实际环境下的实验。
初始训练样本集包括70 个有标签样本(是前文提到的训练样本集吗?前面说的只有30个有标签样本,从下文来看应该不是),通过可重复采样得到的3 个训练样本集样本数为30。增量学习样本集(其实就是对应以下的三十轮的学习,每得到一个新的样本数据且判定为电动自行车充电事件就学习一次。因此30次学习就对应着30个有标签样本)包括30个有标签样本,测试样本集包括30 个有标签样本和100 个无标签样本。模拟某户家庭仅拥有一辆电动自行车的情况,增量学习样本集与测试样本集中的有标签样本为同一辆电动自行车多次采集所得样本。为验证本文方法的有效性,分类器每学习一次就对测试样本集进行一次辨识,测试结果如图4 所示。
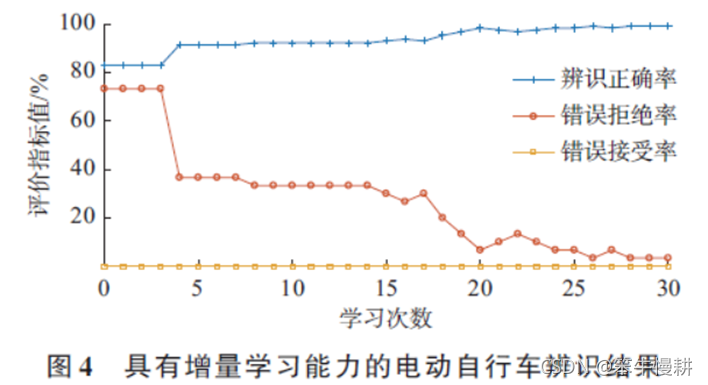
由上图可知,
- 错误接受率(即虚警,False Alarm,FP)一直为0,即不会把非电动自行车充电事件误报为电动自行车充电事件。
- 刚开始时错误拒绝率比较高(即漏检,Miss Detection,FN),这个可能是因为初始训练样本中不包含测试中实际出现的电动自行车型号所致。但是随着新样本不断到来,经过30次学习后,错误拒绝率迅速下降,最后稳定在3.33%
- 辨识正确率(TP+TN)最后稳定在99.23%,可以说是一个相当令人满意的结果
7. 总结和思考
本文以非侵入式负荷监测为基础,提出了一种基于特征选择与OCSVM 增量学习的电动自行车充电辨识方法。低辨识度特征与高冗余度特征集会干扰算法辨识,通过半监督特征选择方法量度辨识度与冗余度,充分挖掘无标签样本信息,采用贪心搜索算法对特征重要性排序,并选择辨识效果最佳的特征子集。另外,赋予OCSVM 算法增量学习能力,解决初始分类器对于陌生型号电动自行车负荷样本辨识正确率较低的问题。通过实测数据,验证了本文所提方法的有效性。半监督特征选择方法不仅降低了算法的计算成本,而且提高了辨识正确率。增量学习OCSVM 算法有效降低了电动自行车错误拒绝率,提高了算法整体性能。下一步,将针对算法辨识与学习速度进行研究,进一步提高算法实用性。同时,本文方法也可推广应用于其他特殊或异常负荷监测中。
My comment:
基于非侵入式负荷监测与分解方法实现电网侧电动自行车充电行为辨识有两种路线,第一是基于传统的NILM的思路,把电动自行车当作另外一种“家用”电器进行识别;第二是把电动自行车充电当作是一种异常事件来处理。两种思路导致的具体策略迥然不同。本论文讨论的是第二种路线。
按照第一种路线的话,因为仅仅是家用电器的种类增加了一种而已,因此对传统的NILM算法处理管道不需要做什么改变,仅仅是用于识别的特征库等追加对应于电动自行车的识别特征即可。这种路线的好处在于是不需要重新进行算法开发,只要对原有的NILM系统进行适当升级即可。甚至升级后的系统将来可以直接移植到专用电动自行车集中充电站的监测管理。
按照第二种路线,只需要区分“是”还是“否”,不需要识别出具有什么时候有哪些电器在使用,可以与传统的NILM相对独立地进行处理。但是需要重新开发算法,只有事件检测这一部分是可以和原NILM系统共用。
电动自行车充电检测与常规的NILM在实时性的要求方面有所区别(需要在路线选择和算法设计中考虑)。电动自行车违规充电是非法事件,检测的目的是及时制止以防患于未然,所以对于实时性要求比较高。而常规的NILM只是要确切地辨识出在什么时候有什么电器有多大功耗,对于实时性的要求相对较低(取决于具体的业务要求)。
当前的研究的重点在于违规充电检测,以后如果基础设施建设跟上了,违规充电可能自然而然地就消失了,重点可能需要转向正常的集中充电站的充电监测。。。
 https://blog.csdn.net/chenxy_bwave/article/details/120906276
https://blog.csdn.net/chenxy_bwave/article/details/120906276


















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











