






大模型正迅速成为现代人工智能的基石。
然而,目前尚无成熟的最佳实践,开发者们常常没有明确的路线图,需要重新发明轮子或者陷入困境。
过去两年,我帮助各种组织利用大模型构建应用。通过这些经验,我开发出了一种经过实战检验的方法,用于创造创新解决方案,我将在这篇文章中分享这种方法。
本文将为你提供了一个明确的路线图,为你在复杂的大模型原生开发领域少踩坑。
你将学习如何从想法转向实验、评估和产品化,解锁你创造突破性应用的潜力。
先看看一些基本问题
为什么要标准化流程
大模型领域发展如此迅速,我们经常听到突破性创新。这非常令人兴奋,但也让人迷失,不知道该做什么,或者如何将你的想法变成产品。
如果你是一位AI创新者(一位开发者或创业者)想要有效地构建大模型原生应用,这就是为你准备的。
采用标准化流程有助于启动新项目,还有以下好处:
-
- 标准化流程 —— 有助于协调团队成员,并确保新成员顺利入职(尤其在这种混乱中)。
-
2. 划定里程碑 —— 一个直接的方式来跟踪你的工作,衡量它,并确保你在正确的道路上。
-
3. 明确决策点 —— 大模型原生开发充满了未知和"小实验"。明确的决策点能够降低开发分风险,使我们精益求精。
大模型工程师的基本技能
与软件研发中的任何其他成熟角色不同,大模型原生开发绝对需要一个新角色:大模型工程师或AI工程师。
大模型工程师是一种独特的混合体,需要以下技能:
-
1. 软件工程技能 —— 像大多数SWE一样,大部分工作涉及将乐高积木拼凑在一起,并将所有东西粘合在一起。
-
2. 研究技能 —— 正确理解大模型原生实验性质至关重要。虽然构建"酷炫的演示应用"相当容易,但从"酷炫的演示"到实用解决方案,需要实验和敏捷性。
-
3. 商业/产品技能 —— 由于模型的脆弱性,理解商业目标和程序,比坚持我们定义的架构更重要。对大模型工程师来说,能够模拟商业过程是一项黄金技能。
大模型工程师仍然是全新的职业,招聘有经验的人员非常难。寻找具有后端开发/数据工程背景的候选人可能是备选方案。
只要你想转到大模型工程师,你必须拥抱新的软技能,你就在正确的道路上!
大模型原生应用开发关键要素
与传统的后端应用(如CRUD)不同,这里没有逐步的配方。
就像"AI"中的其他所有事物一样,大模型原生应用需要一种研究和实验的心态。
要驾驭大模型,你必须将你的工作划分为更小的实验,尝试其中的一些,并选择最有前景的实验。
我无法过分强调研究心态的重要性。这意味着你可能会投入时间去探索一个方向,然后发现它"不可能"、“不够好"或"不值得”。
这完全没问题——这意味着你在正确的道路上。
实验是构建大模型原生应用的唯一方式(并避开路上的障碍)。
从实验开始
有时候,你的"实验"会失败,然后你稍微调整你的工作,其他实验就会取得更好的成功。
这就是为什么在设计最终解决方案前,要从简单开始——风险对冲。
确定"预算"或时间周期。
看看我们可以在X周内做什么,然后决定如何或是否继续。通常,理解基本的PoC需要2-4周就足够了。如果看起来有前景,就继续投入资源去改进它。
实验。
无论你选择自下而上还是自上而下的方法进行你的实验,你的目标都是最大化实验成功率。
在第一次实验结束时,你应该有一些PoC(利益相关者可以玩的)和你达到的基线。
总结实验。
在研究阶段结束时,你可以理解构建这样一个应用的可行性、限制和成本。这有助于你决定是否将其产品化,以及如何设计最终产品、用户体验。
产品化。
开发你的项目的生产就绪版本,并通过遵循标准的SWE最佳实践,实施反馈和数据收集机制,将其与你的其他解决方案集成。
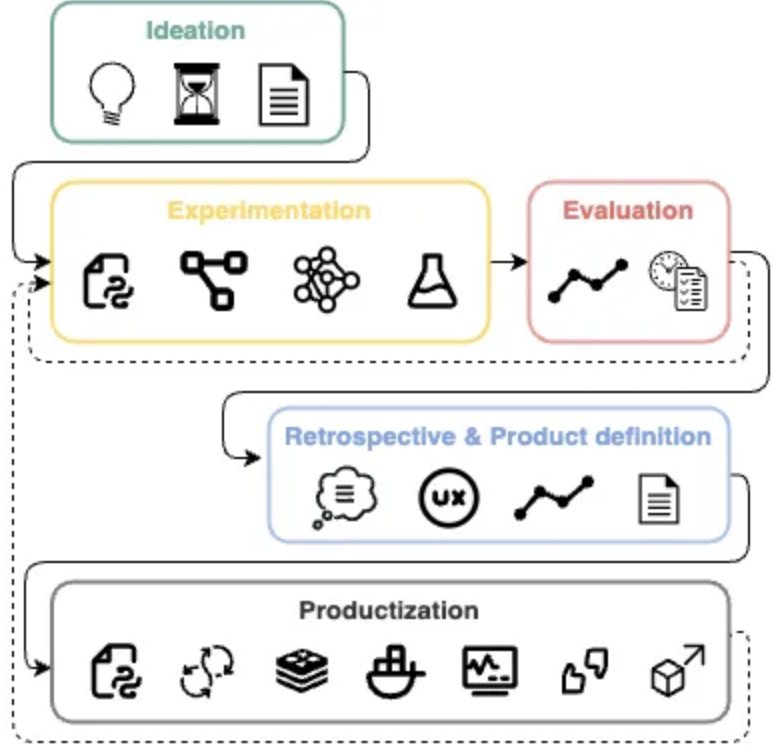
图:大模型原生应用开发生命周期
为了更好地实施以实验为导向的过程,我们要明确如何接近和构建这些实验。
包括自上而下,自下而上两种:
自下而上:以精益化方式开始
虽然许多早期采用者很快就跳入了最先进的多链代理系统,配备了全功能的Langchain或类似的东西,但我发现"自下而上的方法"往往能产生更好的结果。
从精简开始,拥抱"一条提示词统治一切"的哲学。虽然这种策略可能看起来不合常规,一开始可能会产生糟糕的结果,但它为你的系统建立了一个基线。
从那里开始,不断迭代和精炼你的提示词,采用提示工程技术来优化结果。当你发现精简解决方案的弱点时,通过添加分支来划分过程,以解决这些不足。
在我设计大模型工作流,或大模型原生架构的每一个"叶子"时,我遵循魔法三角³来确定在何处和何时切断分支,分割它们,或者加厚根部(通过使用提示工程技术)并榨取更多的果汁。
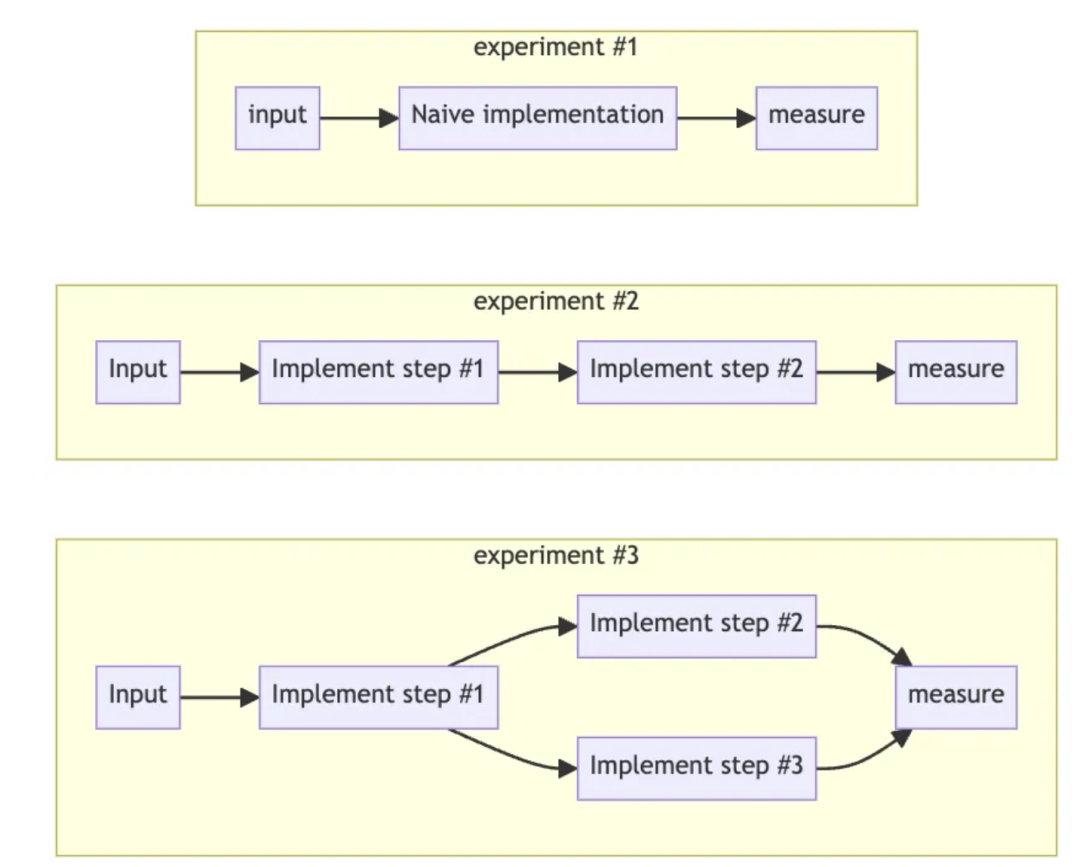
图 自下而上图解(By Almog Baku)
例如,要用自下而上的方法实现"本地语言SQL查询",我们将从直接把提示发送到大模型,并要求它生成一个查询开始。
这并不与"自上而下的方法"相矛盾,而是在它之前的另一步。这使我们能够快速验证想法,并吸引投资。

图 自下而上开发案例(By Almog Baku)
自上而下:一开始就看到全局
“我们知道大模型工作流并不容易,为了实现我们的目标,我们可能最终会得到一些工作流或大模型原生架构。”
自上而下的方法认识上面这点,并从一开始设计原生架构时,实施其不同的步骤/链。
这样,你可以整体测试你的工作流架,并不断优化方案,而不是分别精炼每一片叶子。
自上而下的方法过程:想法、一次设计你的架构、实施关键步骤、测试。
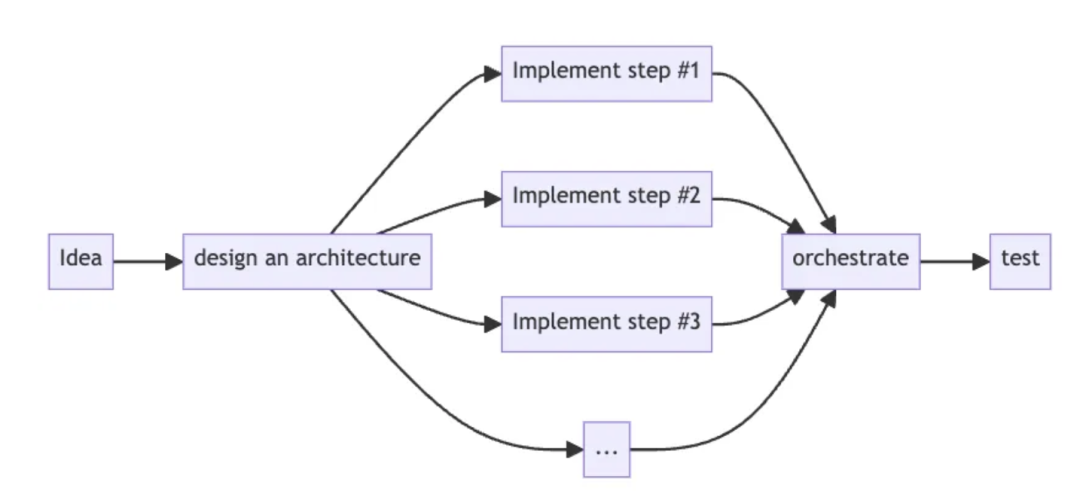
图 自上而下开发流程(By Almog Baku)
例如,要用自上而下的方法实现"本地语言SQL查询",我们将在开始编码之前就设计架构,然后跳到完全实施。
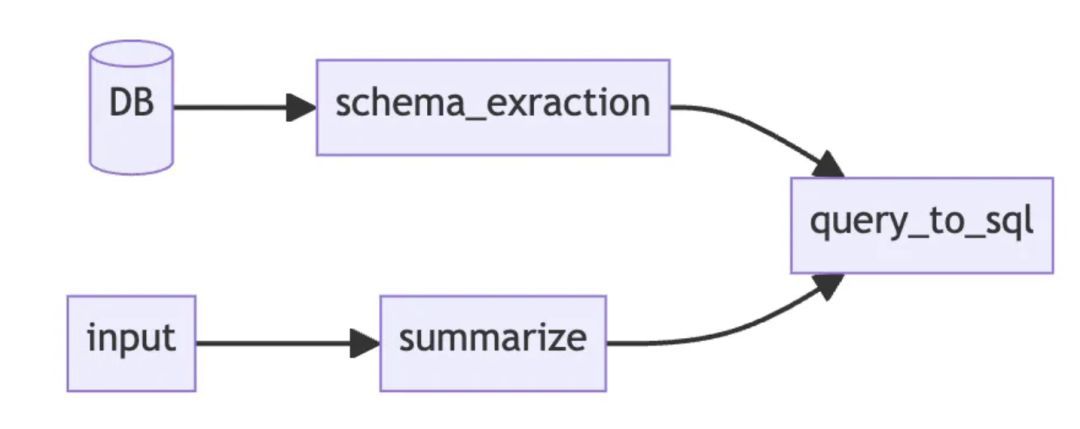
图 自上而下开发的例子(By Almog Baku)
找到平衡
当你开始用大模型进行实验时,你可能会从两个极端中的一个开始(过于复杂的自上而下或超级简单的一次性)。
实际上,没有一种完全解决方法。
理想情况下——你会定义一个标准化程序,并在编码和实验模型之前建模。实际上,建模非常困难;有时,你可能无法接触到这样的专家。
我发现在第一次尝试时很难找到一个好的架构/标注化流程,所以轻微的实验是值得的。
然而,这并不意味着所有的东西都必须过于精简。如果你已经有一个先验理解,某件事必须被分解成更小的部分——那就这么做。
无论如何,你应该利用魔法三角³的范例,在设计你的解决方案时正确地模拟手动过程。
不断优化解决方案
在实验阶段,我们不断地优化解决方案,添加更多的"复杂性层次":
-
• 提示工程技术:如少样本提示,角色分配,甚至动态少数提示
-
• 扩大上下文窗口:从简单的变量信息到复杂的RAG流程,可以帮助改善结果。
-
• 尝试不同的模型:不同的模型在不同的任务上表现不同。此外,大型大模型通常并不非常具有成本效益,值得尝试更多的任务特定模型。
-
• 压缩流程:缩减流程(如提示和请求的输出)"缩减"通常可以改善延迟。通过减少提示的大小和模型需要经历的步骤,我们可以减少模型需要生成的输入和输出数量。缩减提示节食甚至可以提高质量!请注意,缩减也可能导致质量下降,所以在这样做之前,设置一个健全的测试。
-
• 将过程分解为更小的步骤:使优化你的SOP的子过程更容易和可行。请注意,这可能会增加解决方案的复杂性或损害性能(例如,增加处理的令牌数量)。为了减轻这种影响,应该寻求简洁的提示和更小的模型。
按照经验,当系统提示戏剧性变化为SOP¹流程的这一部分带来了更好的结果时,通常是分割的好时机。
实验工具
我更喜欢使用Python、Pydantic和Jinja2在一个简单的Jupyter Notebook中开始精简的实验:
-
1. 使用Pydantic来定义我的模型输出的模式。
-
2. 使用Jinja2编写提示模板。
-
3. 定义一个结构化的输出格式(在YAML中)。这将确保模型遵循"思考步骤"并由我的SOP指导。
-
4. 通过你的Pydantic验证确保这个输出;如果需要——重试。
-
5. 稳定你的工作——将你的代码结构化为Python文件和包。
在更广泛的范围内,你可以使用不同的工具,如openai-streaming轻松利用流式处理(和工具),Lite大模型拥有跨不同提供商的标准化大模型SDK,或者使用开源大模型。
通过测试和评估确保质量
理智测试评估你的项目质量,并确保你没有降低你定义的某个成功率基线。
将你的解决方案/提示想象成一条短毯子——如果你拉得太紧,它可能突然无法覆盖它曾经覆盖的一些用例。
为此,定义一组你已经成功覆盖的案例,并确保你保持这种状态(或者至少它是值得的)。将其视为表驱动测试可能会有所帮助。
评估一个"生成性"解决方案(例如,写作文本)的成功比使用大模型进行其他任务(如分类、实体提取等)要复杂得多。
对于这类任务,你可能需要引入一个更智能的模型(如GPT4、Claude Opus或LLAMA3–70B)来充当"裁判"。
在"生成性"输出之前尝试并使输出包含"确定性部分"也可能是个好主意,因为这类输出更容易测试:
cities:` `- New York` `- Tel Aviv``vibes:` `- vibrant` `- energetic` `- youthful``target_audience:` `age_min: 18` `age_max: 30` `gender: both` `attributes:` `- adventurous` `- outgoing` `- culturally curious```# ignore the above, only show the user the `text` attr.```text: Both New York and Tel Aviv buzz with energy, offering endless activities, nightlife, and cultural experiences perfect for young, adventurous tourists.
复盘里程碑/实验
在每一个主要的/时间框架的实验或里程碑之后,我们应该停下来做出明智的决定关于如何以及是否继续这种方法。
在这一点上,你的实验将有一个明确的成功率基线,你将知道需要改进什么。
这也是开始讨论这个解决方案的产品化影响并开始"产品工作"的好时机:
-
1. 这将在产品中看起来像什么?
-
2. 有什么限制/挑战?你将如何缓解它们?
-
3. 你当前的延迟是多少?这足够好吗?
-
4. UX应该是什么?你可以使用哪些UI技巧?流式处理能帮助吗?
-
5. 对代币的预计支出是多少?我们能否使用更小的模型来减少支出?
-
6. 优先级是什么?挑战中的任何一项是否是绊脚石?
假设我们达到的基线是"足够好的",并且我们相信我们可以缓解我们提出的问题。那么,我们将继续投资并改进项目,同时确保它永不退化并使用理智测试。
最后,产品化和商业化
最后但并不是最不重要的,我们必须将我们的工作产品化。
像任何其他生产级别的解决方案一样,我们必须实现生产工程概念,如日志记录、监控、依赖管理、容器化、缓存等。
这是一个复杂的过程,但幸运的是,我们可以借用许多来自传统生产工程的机制,甚至采用许多现有的工具。
话虽如此,对于涉及大模型原生应用的细微差别,我们需要特别小心:
反馈循环
我们如何衡量成功?它只是一个"点赞/点踩"机制,还是一个更复杂的机制,考虑到我们解决方案的采用?
收集这些数据也很重要;未来,这可以帮助我们重新定义我们的理智"基线",或者使用dynamic-few shots或微调模型来微调我们的结果。
缓存
与传统的SWE不同,当我们在解决方案中涉及生成性方面时,缓存可能会非常具有挑战性。
为了缓解这个问题,探索缓存类似的结果(例如,使用RAG)和/或减少生成性输出(通过有一个严格的输出模式)。
跟踪成本
许多公司发现使用一个"强大的模型"(如GPT-4o)开始是非常诱人的,
然而,在生产中,成本可以迅速上升。避免在最后的账单上被惊讶,并确保测量输入/输出代币并跟踪你的工作流影响(没有这些实践——祝你好运在以后对它进行分析)
可调试性和跟踪
确保你已经使用工具来跟踪一个"有问题的"输入,并在整个过程中跟踪它。
这通常涉及保留用户输入以供后续调查,并设置一个跟踪系统。
记住:“与过渡软件不同,AI会默默失败!”
结 语
大模型原生应用开发是一个不断迭代的过程,它覆盖了更多的用例、挑战和特性,并不断改进我们的大模型原生产品。
在你继续你的AI开发之旅时,保持敏捷,无畏地实验,并始终将最终用户放在心中。在社区分享你的经验和见解,我们一起推动大模型原生应用的可能性边界。
我希望这篇指南在你的大模型原生开发旅程中是一个有价值的伙伴!
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









