






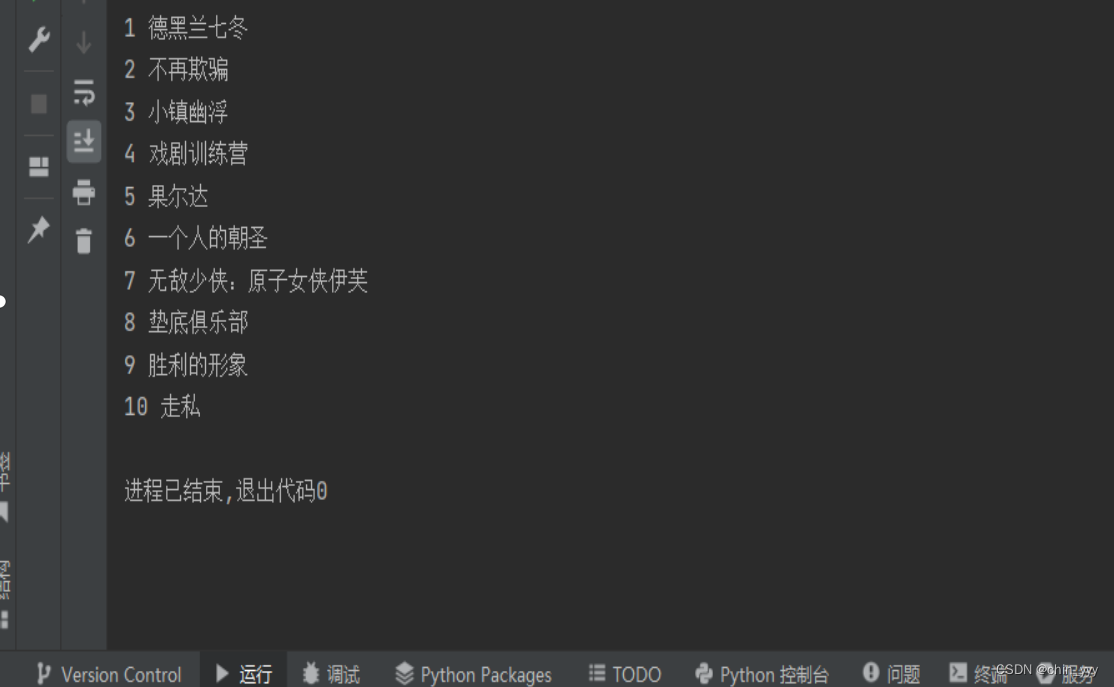
利用requests库访问https://movie.douban.com/网站。检查是否出现乱码问题,如有请解决。利用正则表达式提取其中的“一周口碑榜”中的电影列表信息并打印输出。如下图所示:

部分代码如下:
import re
import requests
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
url='https://movie.douban.com/'
response = requests.get(url,headers=headers)
response.encoding=response.apparent_encoding
#print(response.text)
re_str='<td class="order">(.*?)</td>'
#re_std='<td class="title">(.*?)</td>'
re_std='<td class="title"><a onclick=".*?" href=".*?">(.*?)</a>'
result=re.findall(re_str,response.text)
result2=re.findall(re_std,response.text)
item=zip(result,result2)
for z in item:
variable1, variable2 = z
print(variable1, variable2)运行结果:
















 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











