







目录
因果关系的三个层级
因果推断是基于统计学方法刻画变量之间的因果关系。因果关系存在三个层级:
-
第一层级(关联):从数据中观察到哪些相关规律?是对历史数据的总结。
-
第二层级(干预):如果采取某个行动,会产生什么结果?是面向未来的推测。
-
第三层级(反事实):如果当时采取了另外一个行动,结果会是怎样?是面向过去的反思。

目前大部分机器学习模型还处在第一层级,仅仅实现了对历史数据的“曲线拟合”,这就导致:一是解释性差,拟合背后的作用机理处于黑盒状态;二是泛化性差,拟合得到规律只适用于训练数据。而因果推断方法能让我们站上第二、三层级,从而实现更好的解释性和泛化性,这也是因果推断在机器学习领域逐步兴起的一大原因。
因果推断的三个假设
假设1:稳定个体干预值假设(Stable Unit Treatment Value Assumption, SUTVA):即任意个体的潜在结果都不会因其他个体的干预发生改变而改变,且对于每个个体,其所接受的每种干预不存在不同的形式或版本,不会导致不同的潜在结果。
假设2:无混淆假设(Unconfoundedness):即给定特征变量X ,分配哪个Treatment独立于潜在结果,记为(Y0 ,Y1 ) ⊥ T | X,它等价于不存在观测不到的混淆因子。
假设3:正值假设(Positivity):即对于任意值的X ,Treatment的分配都不是确定的,即Treatment各种取值都能有一定量的观察数据。也
因果性的常见谬误
1) 伪关系
伪回归指的是自变量和因变量之间本来没有任何因果关系,但由于某种原因,回归分析却显示出它们之间存在统计意义上的相关性,让人错误地认为两者之间有关联,这种相关性称作伪关系(spurious relationship)。
例如:吸烟导致肺癌;
原因:存在干扰因素/两个变量之间存在局部随机趋势
2) 幸存者偏差/选择偏差
幸存者偏差指的是只看到经过某种筛选之后的结果,忽略关键信息。
例如:二战中,是否要加强飞机弹孔部位
3) 遗漏变量偏差
遗漏某一重要变量,导致人们认为两者存在相关关系(可以理解为伪关系+幸存者偏差)
例如:夏天冰激淋销量上升,意外淹死的人也很多,是冰激淋导致更多人淹死吗?
遗漏了天气的影响,天气变热会导致吃冰激淋的人变多和玩水的人变多
4) 反向因果
反向因果关系是指与常见假设相反的因果方向或循环中的双向因果关系。
例如:犯罪率高的城市警察也多,是否警察多导致犯罪率高,还是犯罪率高导致警察多?
因果推断偏差原因
事实上不存在平行时空,我们不能同时对一个群体既施加干预又不施加干预,而只能观察到其中的一种情况,对于未观察的情况我们称之为反事实的(Counterfactual)。理论上,可以通过随机控制实验(Random Control Trial,RCT)来解决这个问题:将群体随机分成两组,一组施加干预(实验组),另一组不施加干预(控制组/对照组)。这种方法称为实验性研究,广泛应用的AB实验方法其实就是同样的思路。
1)混杂偏差:同时对Treatment和结果有影响的因素叫混杂因子(Confounder),它的存在会导致偏差。消除混杂偏差的方法是将混杂因子控制住,再去度量Treatment和结果的关系。
2)选择偏差:不管是实验性研究还是观察性研究,评估通常都是在一个筛选出来的样本子集上进行,如果样本子集不能代表总体,则会导致选择偏差(或称样本偏差)。
因果推断的两种流派
(1) 结构因果模型(SCM, Structural causal model)
大概思路是说通过一个有向无环图 表达因果关系,每个节点的值(准确说是内生节点)都可以通过一个关于其父节点的函数计算获得,从而得知干预某个节点(treatment)对目标节点(outcome)的影响(treatment effect)。
(2) 潜在结果框架(Potential outcomes framework)
- 大概思路是认为每个观测到的样本在平行世界里都存在着另一个事实对应着另一个可能,称为潜在结果(Potential outcome)。只要把潜在的结果计算出来,跟观测到的结果进行对比(相减),就知道两种选择(做干预、不做干预)的区别了。
因果推断前提假设
假设1:稳定个体干预值假设(Stable Unit Treatment Value Assumption, SUTVA)
假设2:无混淆假设(Unconfoundedness)
假设3:正值假设(Positivity)
因果推断的流程
① 数据类型:观测数据、随机实验数据、观测数据+随机实验数据
② 去偏差
混淆偏差:PSM/IPW、DML(双重机器学习)、DRL(双重稳健学习)、SCM(因果图模型)
1 因变量为是否被干预Treatment,自变量为用户特征变量。套用LR或者其他更复杂的模型,如LR + LightGBM等模型估算倾向性得分。
2 倾向性得分
a. 匹配用的得分:可选原始倾向性得分 e(x) 或者得分的 logit,ln(e(x)/(1−e(x)))。
b. 修剪(trimming):先筛选掉倾向性得分比较 “极端” 的用户。常见的做法是保留得分在 [a,b]这个区间的用户,关于区间选择,实验组和对照组用户得分区间的交集,只保留区间中部 90% 或者 95%,如取原始得分在 [0.05,0.95]的用户。
c. 匹配(matching):实验组对对照组根据得分进行匹配的时候,比较常见的有以下两种方法。nearest neighbors: 进行 1 对 K 有放回或无放回匹配。
radius: 对每个实验组用户,匹配上所有得分差异小于指定 radius 的用户。
d. 得分差异上限:当我们匹配用户的时候,我们要求每一对用户的得分差异不超过指定的上限。
选择偏差:Reweighting、去除混淆因子
③ 先验信息:可选
因果效应估计:
④ 模型选择
ITE:Meta learner(S-learner/T-learner/X-learner)、Tree based
ATE:
⑤弹性保序
⑥评估方法
去偏评估:SMD
平稳性检查:SMD 的一种计算方式为:(实验组均值 - 对照组均值)/ 实验组标准差。一般如果一个变量的 SMD 不超过 0.2,一般就可以认为这个变量的配平质量可以接受。当一个变量的 SMD 超过 0.2 的时候,需要凭经验确认一下那个变量是不是没有那么重要。
模型评估:Qini Curve、AUUC
准确程度指标:Bias、MAE、RMSE
因果敏感度分析:安慰实验、添加未观察常识原因
因果推断常用方法
re-weighting methods(IPW)
stratification methods(分层)
matching methods(匹配)
tree based methods
Casual Forest
因果推断最小化分裂点内部的uplift 差值,最大化各分裂点内部的 uplift 差值。同时引入诚实树主要是为了解决传统决策树或随机森林(Casual Forest)模型中可能存在的过拟合问题,并增强模型的泛化能力和可信度。
连续因果森林
有如下假设:
- 单调性:价格越高,需求越低 ;
- 局部线性:在局部价格区间内,价格与需求呈线性关系。
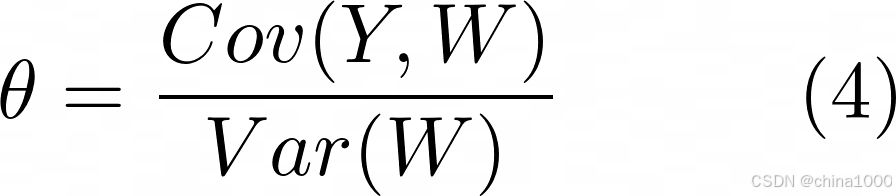
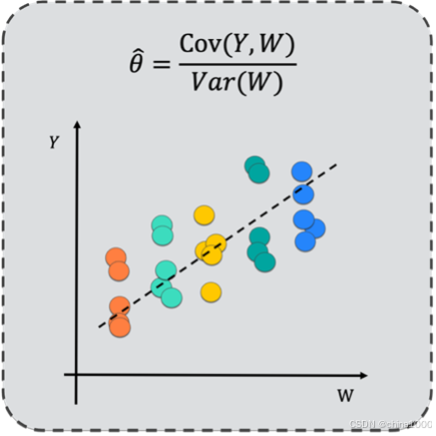
可以证明(https://z.didi.cn/CAPE),上述公式等价于Y对W和做简单线性回归后得到的斜率系数。
通过将CAPE代替CATE作为节点统计值用作树分裂,我们就实现了通过单一模型估计多元/连续处理效应。
representation based methods
通过学习一种新的表示来减少协变量不平衡的影响。
multi-task methods
meta-learning methods
1. S-learner
直接把treatment作为特征放进模型来预测。
2. T-learner
先对于 T=0 的control组和 T=1 的treatment组分别学习一个有监督的模型。
3. X-learner
类似上一个,先对于 T=0 的control组和 T=1 的treatment组分别学习一个有监督的模型。然后基于反事实结果计算。

DML


因果图建模的
微软的: dowhy
开源项目: CasualLM
因果推断评估方法
AUUC就是Uplift Curve下的面积,Qini coefficient 就是 Qini Curve下的面积,面积越大越好。
AUUC
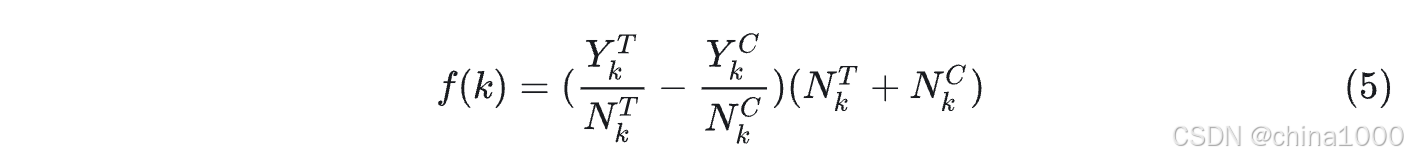
qini指数
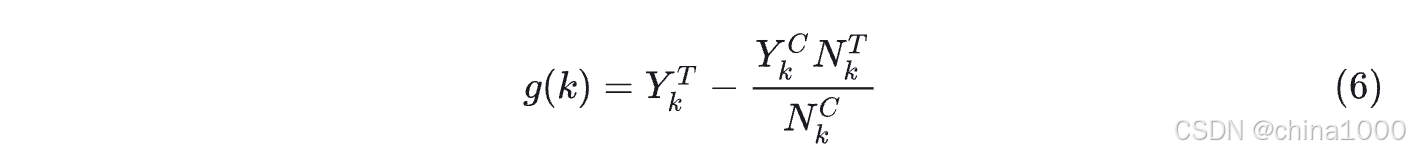
Qini Curve在实际情况中通常会比Uplift Curve更好。 qini指数对实验组对照组干预样本数目做了缩放。
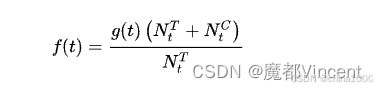
ATE
参考文献:

















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









