






 主题模型是一种用于文本挖掘的统计模型,能揭示文档集中的潜在主题结构。本文解释了主题的概念、主题模型的工作原理,介绍了PLSA和LDA两种求解方法,并讨论了其在衡量文档相似性和语义关系中的应用。
主题模型是一种用于文本挖掘的统计模型,能揭示文档集中的潜在主题结构。本文解释了主题的概念、主题模型的工作原理,介绍了PLSA和LDA两种求解方法,并讨论了其在衡量文档相似性和语义关系中的应用。
1、什么是主题?
主题是一个概念,一个方面,表现为一些列相关的词语,即主题就是词汇表上词语的条件概率分布,与主题关系密切的词语,它的条件概率越大,反之则越小。
2、主题模型的工作原理?
主题模型是从生成模型的角度来观测文档和主题,即“一篇文章的每个词都是通过一定概率选择某个主题,并从这个主题中以一定概率选择某个词语得到”。因此要生成一篇文档,其中每个词语的概率为:
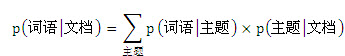
用线性代数表示:
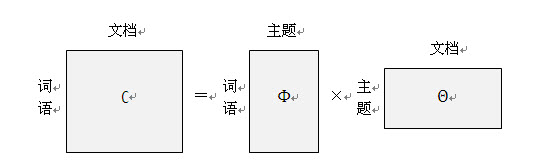
左边的矩阵C表示每篇文章中每次词语出现的概率;中间的Φ矩阵表示的是每个主题中每个词语出现的概率 ,最后的θ矩阵表示每个文档中每个主题出现的概率。
主题模型就是已知“词语-文档”矩阵C,求“词语-主题”矩阵Φ和“主题-文档”矩阵θ。
3、主题模型的求解方法?
4、主题模型的作用?
假设有两个句子,我们想知道它们之间是否相关联:
第一个是:“乔布斯离我们而去了。”
第二个是:“苹果价格会不会降?”
如果由人来判断,我们一看就知道,这两个句子之间虽然没有任何公共词语,但仍然是很相关的。这是因为,虽然第二句中的“苹果”可能是指吃的苹果,但是由于第一句里面有了“乔布斯”,我们会很自然的把“苹果”理解为苹果公司的产品。事实上,这种文字语句之间的相关性、相似性问题,在搜索引擎算法中经常遇到。例如,一个用户输入了一个query,我们要从海量的网页库中找出和它最相关的结果。这里就涉及到如何衡量query和网页之间相似度的问题。对于这类问题,人是可以通过上下文语境来判断的。但是,机器可以么?
在传统信息检索领域里,实际上已经有了很多衡量文档相似性的方法,比如经典的VSM模型。然而这些方法往往基于一个基本假设:文档之间重复的词语越多越可能相似。这一点在实际中并不尽然。很多时候相关程度取决于背后的语义联系,而非表面的词语重复。
那么,这种语义关系应该怎样度量呢?事实上在自然语言处理领域里已经有了很多从词、词组、句子、篇章角度进行衡量的方法。本文要介绍的是其中一个语义挖掘的利器:主题模型。

















 6451
6451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









