









Transformer理解及源码注解
1、哈佛NLP团队实现的Pytorch版代码链接在这里。
2、主要根据这一份文档来理解。
先看这个论文里的结构图。看起来真的有点复杂,比如像我一年之前看到他也是直接略过哈哈哈哈哈。后来跟着实际代码一起看才觉得比较好懂。
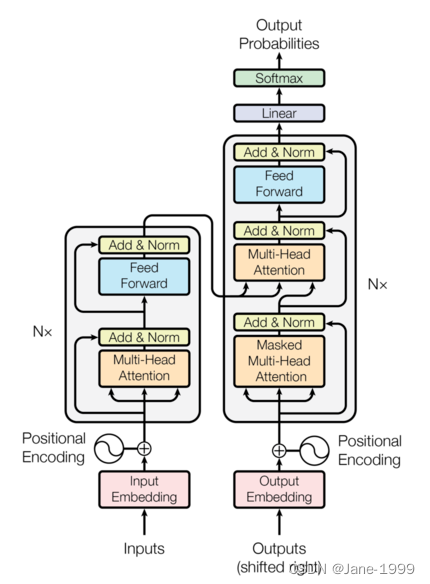
注意:本文所有层的输出维度均为dmodel=512,多头注意力机制的头数h=8!
一、model architecture
class EncoderDecoder(nn.Module):
"""
实现整体的架构,这里要注意,没有把最后的generator加进去,所以在写自己的模型时,输出之后还要再过一个generator。
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
#将encoder的输出作为decoder的memory传入,并计算
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
#构造encoder的输出
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
#构造decoder的输出
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"一个标准的线性+softmax的类"
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return log_softmax(self.proj(x), dim=-1)
二、encoder和decoder
首先,能理解的是,左边是一个encoder,右边是一个decoder。encoder部分的代码是这样实现的。
1、encoder由6个encoderlayer(总图的左边)堆叠起来,输入分别经过6个encoderlayer,最后layernorm输出。
def clones(module, N):
"复制N个module,也就是层"
"nn.ModuleList将模块以列表的方式保存"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):
"encoder就是由六个层堆叠起来,再过layernorm"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"x依次通过N个层,返回layernorm之后的值"
"mask是用来控制attention的"
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class LayerNorm(nn.Module):
"实现layernorm,对层级别归一化"
"a_2初始化一个全1的512维参数张量,即下图中的gamma"
"b_2初始化一个全0的512维参数张量,即下图中的beta"
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
不同于BatchNorm,LayerNorm常用于NLP当中,用处常常是对一个token的embedding向量进行归一化。
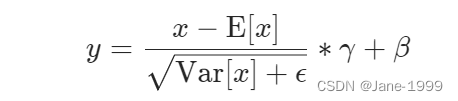
class SublayerConnection(nn.Module):
"""
残差块的实现,x经过sublayer再和x相加
sublayer就是下图中的multi-head attention和feed forward
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
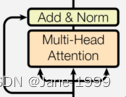
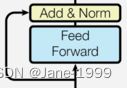
class EncoderLayer(nn.Module):
"一个encoderlayer由两个部分连接构成,如上图"
"clones实现两个残差块"
"第一个残差块的sublayer为自注意,第二个残差块的sublayer为feed forward"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"第一个残差块sublayer[0]的内部层sublayer为自注意"
"第二个残差块sublayer[1]的内部层sublayer为feed forward"
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
2、decoder也是由六个decoderlayer(总图右边)堆叠而成,但是比encoderlayer多了一个sublayer。
class Decoder(nn.Module):
"和decoder差不多,只在forward上多了memory以及一个mask"
"tgt_mask用在自注意层,即第一个attention layer"
"src_mask用在第二个attention layer上,与encoder的输出做交互注意力"
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
""
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"memory是encoder的输出"
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
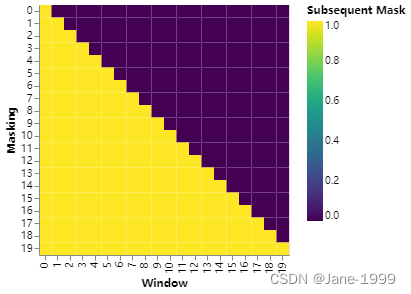
def subsequent_mask(size):
"此函数的作用是生成一个下三角矩阵,只有下半部分是true,上半部分为false"
"目的在与使得自注意时,每个token只能看到之前的信息,不能看到之后的信息"
attn_shape = (1, size, size)
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)
return subsequent_mask == 0 #张量位置为0,返回true
下图就是subsequent_mask的可视化,一个20个token的输入其对应的自注意的mask。一行代表一个token,它关注的位置(列),置0表示能看到,置1表示不能看到。实际在输入transformer时,应该输入一个布尔类型的方阵,为True位置能看到,False位置不能看到。
三、Attention
注意力是核心,目的在于提取出最需要关注的部分。比如对一个句子做情感分析,“我很开心”,“开心”就是我们判断这句话情感的关键词汇,注意力的作用就是给“开心”赋予更高的权重,使其在提出的句子特征中更加显著。
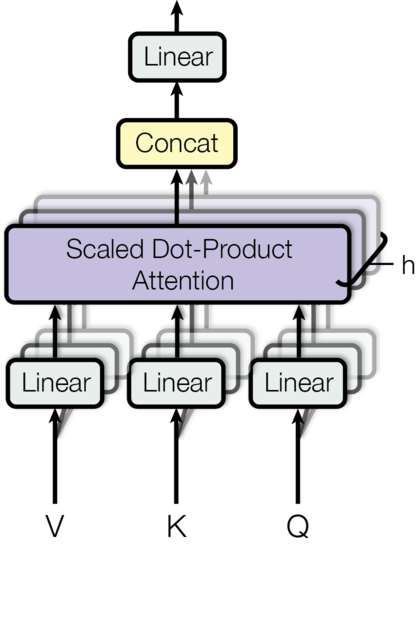
下图左边是单个注意力机制的示意图。右边是多头注意力机制,就是h个左图同时计算,结果再concat过线性。
本文中attention的应用主要在三个方面。1)decoder自注意。2)encoder自注意。3)encoder的输出做K、V,decoder的输出做Q的交叉注意力。
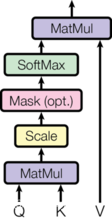
def attention(query, key, value, mask=None, dropout=None):
"用于实现注意力机制,下图为注意力公式"
"通常,attention为自注意力,即q、k、v都由同一个输入过线性层得到"
"scores.masked_fill(mask,value)表示用value填充scores中与mask中值为1位置对应的元素。"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
其实注意力计算通常有两种计算方法,一种就是dot-product attention,一种是additive attention。后者的实现采用一个隐藏层的feed-forward网络实现。前者与本文采用的attention一致,只是最后没有scale即没有乘以
1
d
k
{1}\over\sqrt{d_k}
dk1。
在dk比较小时,两者表现差不多,dk比较大时,没有scale的dot-product表现比不上additive attention。因此在本文中采用scale的方式来弥补。
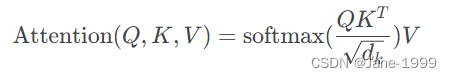
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"h表示有几个单注意力机制,本文取8个"
"d_model表示模型的维度本文统一为512"
"单个注意力机制的维度d_k=d_v=d_model/h=512/8=64"
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# d_v 默认恒等于 d_k
self.d_k = d_model // h
self.h = h
#三个线形层用来生QKV,最后一个线性层在concat之后用于输出
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
#mask的维度[batch_size,seq_len,seq_len]
#qkv的维度[batch_size,seq_len,d_model(512)]
#qkv经过linear之后维度变为[batch_size,h(8),seq_len,d_model/h(64)]
#为了保证在attention时mask的维度与经过linear之后的qkv也一样
#将mask扩展为[batch_size,1,seq_len,seq_len]
#八个头都用一样的mask
mask = mask.unsqueeze(1)
nbatches = query.size(0)
#q、k、v分别过线形层,[batch_size,seq_len,512]->[batch_size,8,seq_len,64]
#torch.transpose(dim1,dim2)表示将张量的dim1,dim2两个维度交换
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
#做attention,所有bacth及head一起做
#x的维度[bacth_size,8,seq_len,64]
#self.attn的维度[bacth_size,8,seq_len,seq_len]
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# concat,将八个attention计算得到的64维矩阵concat,变成512
#先transpose,从[batch_size,8,seq_len,64]->[batch_size,seq_len,8,64]
#view,从[batch_size,seq_len,8,64]->[batch_size,seq_len,512]
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
#最后再过一个全连接层
return self.linears[-1](x)
四、Position-wise Feed-Forward Networks(FFN)
本文中的feed-forward networks由两个线形层及ReLU激活函数构成,对应公式如下图。dmodel=512,dff=2048。
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))

五、Embeddings and Softmax
nn.Embedding(num_embeddings, embedding_dim),其中num_embeddings代表词表vocab的大小,比如bert当中的vocab_size为21130。 embedding_dim代表需要将一个token映射到的向量维度,比如bert当中就是768。但是本文中,为了方便,这个数目为512。
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
六、Positional Encoding
由于这个模型没有recurrence或者convolution结构,但是为了利用句子的序列信息,我们还是需要插入一些关于token的相对及绝对位置信息。
使用cos和sin函数来计算一个token的位置信息,如下图所示。这个式子真的看起来非常奇怪,什么是pos,什么是2i,看得人一头雾水哈。
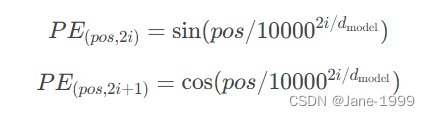
先说pos,他代表一个token在序列中的第几个位置。i,或者说2i及2i+1表示了Positional Encoding的维度。这样说也很不清楚的话,举一个例子。
比如说一个token在序列中的第一个位置。那么它对应的Positional Encoding就可以表示为(一共512维):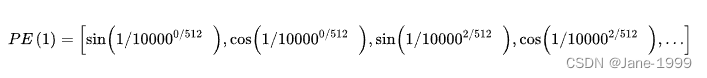
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
#pe维度是[max_len,512]
pe = torch.zeros(max_len, d_model)
#position维度是[max_len,1]
position = torch.arange(0, max_len).unsqueeze(1)
#div_term在计算公式当中的1/10000^(2i/d_model)
#torch.exp(x)对x中的元素计算e^x并返回张量
#torch.arange(0,d_model,2)生成[0,2,4……512]的张量
#math.log(x)计算自然对数lg(x)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
#切片,偶数位置是sin
pe[:, 0::2] = torch.sin(position * div_term)
#切片,奇数位置是cos
pe[:, 1::2] = torch.cos(position * div_term)
#扩展pe维度,[max_len,512]->[1,max_len,512]
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
#self.pe[:, : x.size(1)]对第二维(max_len)切片,得到与x的seq_len长度一致的position encoding
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
七、现在就开始堆积木吧
现在我们已经分步骤把一个transformer的各个部分写出来了,接下来就是组合啦。就像在做三明治,先准备材料,最后组合。
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab),
)
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









