







这是2018CVPR的一篇论文,旨在说明使用深度学习的方法使得暗光条件下的图像更明显。一般来说低光照条件下的图像噪点更多,使用一些方法增强图像或是引入更多的噪点,或是由于曝光时间过长导致抖动产生图像上的模糊。而目前增强暗光图像的方法还不试用于非常暗光和非常短曝光时间的图像,所以文章认为可以充分利用raw类型的数据进行图像增强。如下图所示,一般增强后的图像中噪点非常多:

论文首先是制作数据集,使用长曝光(100-300倍曝光时间于原图像)的方式获得目标图像。并使用方法避免抖动,同时图像数据也包括室内和室外数据,主要通过两种相机获得使得输入图像数据排列有两种形式。
在网络处理数据时,这里是使用看FCN结构。输入数据时,bayer数据被分为四个通道,并进行两倍的下采样(如下图)。对于X-trans类型的图像数据,数据被安排成6x6的块,可以通过交换相邻元素的方法将其分到九个通道里(下图没有显示)。然后减去图像的黑色像素并按照一定尺度对图像像素进行缩放,最后网络输出是12通道只有一半分辨率的图像数据,通过一个sub-pixel层可以恢复到原来的分辨率。
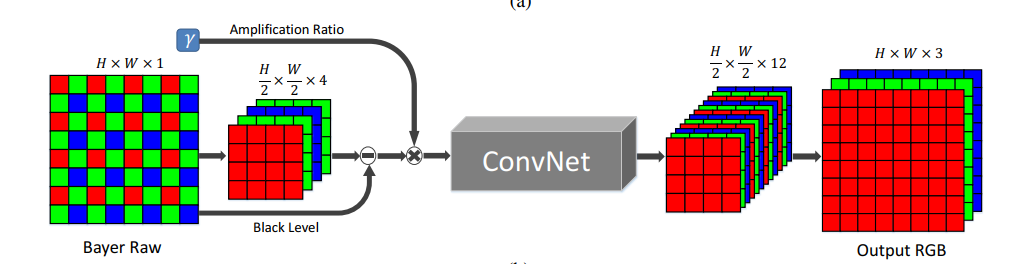
网络使用可快速处理图像的CAN或U-net作为核心架构,由于需要处理全分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2686
2686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









