









 本文解析了2017年CVPR论文PerceptualGAN,探讨了如何通过GAN提升小目标特征,但存在网络选择、流程设计问题及实验效果有限。作者质疑核心理念和实践设计,并提出改进思路。
本文解析了2017年CVPR论文PerceptualGAN,探讨了如何通过GAN提升小目标特征,但存在网络选择、流程设计问题及实验效果有限。作者质疑核心理念和实践设计,并提出改进思路。
基于GAN的小目标检测算法总结(1)——Perpetual GAN
1.前言
这是一个系列文章,对基于GAN的小目标检测算法进行总结。目前基于GAN的小目标检测算法不多,比较有名的有3篇(好总结嘛),如下:
(1)2017年的CVPR,《Perceptual Generative Adversarial Networks for Small Object Detection》,简称Perceptual GAN;
(2)2018年的ECCV,《SOD-MTGAN:Small Object Detection via Multi-Task Generative Adversarial Network》;简称MTGAN;
(3)2019年的ICCV,《Better to Follow, Follow to Be Better: Towards Precise Supervision of Feature Super-Resolution》,目前没有主流的简称叫法,我这里为了方便,将其简称为TPS。
该系列文章预计总共出4篇,分别对这3篇论文进行介绍,最后一篇对基于GAN的小目标检测算法进行总结,并提一点我自己的看法,受限于个人的局限性,本文内容难免有错误,个人观点也仅作参考,欢迎大家批评指正。
本文是系列文章第1篇,对Perpetual GAN方法进行介绍。
2.Perceptual GAN
Perceptual GAN是基于GAN的小目标检测算法的开篇之作。
2.1算法简介
2.1.1 核心idea
小目标检测难,是因为小目标分辨率低、特征少,可以将小目标表征提升为”super-resolved”表征,使得小目标表征和大目标具有相似的特性,并且使小目标表征具有更强的判别力。
使用Perceptual GAN缩小小目标和大目标之间的表征差异。生成器将小目标的弱表征迁移为和大目标相似的super-resolved表征;而判别器学习区分是生成器生成的表征还是原始大目标特征,并且对生成器做感知要求:生成的小目标表征必须有利于检测。
注意:文中的描述是”super-resolved”表征,但是这里解释为超分辨率特征也不妥,因为看过论文后,发现没有提高分辨率(shape没有变大),本文的核心idea可以简单的理解为使用GAN增强小目标的特征,使其和大目标特征相似,但是不增加分辨率。
2.1.2网络组成
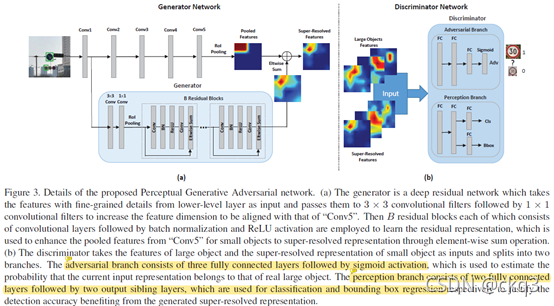
整个网络分为三个部分:目标检测的backbone部分、生成器部分、判别器部分。
2.1.2.1目标检测backbone部分
就是图3的(a)的上半部分,至于网络的具体结构,交通标志牌检测(Tsinghua-Tencent 100K)用VGG-CNN-M-1024,行人检测(Caltech benchmark)用VGG-16。
疑问:很奇怪,不同数据集竟然用不同的网络,并且居然不用ResNet系列?
并且可以看到backbone后面还有RoI Pooling,但不要以为这是个RPN网络,论文4.2节明确说明,对于Tsinghua-Tencent 100K数据集,采用RPN提取proposals,而对Caltech benchmark数据集,使用ACF行人检测器提取proposals。经查证,ACF是个传统的行人检测算法,也就是说,在Caltech benchmark数据集上,需要先运行一遍ACF行人检测器,再运行一遍Perpetual GAN才完成一张图像的检测,这个计算量肯定会非常大。
2.1.2.2生成器部分
如上图,共3个部分,前面2个卷积层+RoI pooling层+残差块,其输入不是图像,而是backbone的浅层Conv1特征图,RoI pooling后得到各个proposals的特征,然后将这些proposals的特征送入残差块,输出特征直接加到backbone的特征上(由此判断生成器没有提高分辨率)。
总结,这个生成器学习的是小目标和大目标的特征差异,输入小目标的特征,输出小目标和大目标的特征差异,而不是输出大目标特征。
2.1.2.3判别器部分
包括两个分支:对抗分支和感知分支。
(1)对抗分支不用说,就是判别特征来自生成器的小目标的super-resolved特征,还是大目标的特征;
(2)感知分支特别简单,就是目标检测的head,分类+边界框回归。
2.1.3 训练过程
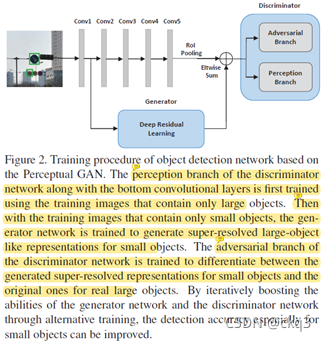
训练分为三个阶段:
(1)使用仅含有大目标的图像,训练bottom卷积层(应该是目检测backbone部分)和判别器的感知分支,使用的是感知损失;
(2)使用仅含有小目标的图像,训练生成器网络,使用是感知损失+对抗损失;
(3)使用大目标和小目标图像,训练判别器的对抗分支,使用的是对抗损失。
上述三阶段不断循环往复。
2.1.4 测试过程
我猜测,测试阶段如下:
(1)目标检测backbone部分:图像输入目标检测backbone,并利用RPN或者ACF行人检测器获得proposals;
(2)生成器:判断proposals是否是小目标,如果是,需要将对应的浅层特征送入生成器,利用RoI pooling获得proposals的特征,并进行后续的传播,把输出的特征差异加到backbone部分经RoI pooling的输出特征上,获得super-resolved特征;如果不是小目标,不经过生成器的前向传播。
(3)判别器的感知分支:获得的super-resolved特征,送入判别器的感知分支,获得目标类别和边界框。
总结:Perpetual GAN相当于在普通的目标检测算法上增加了生成器的前向传播,这个计算量肯定会比较大。
3.一点看法
我个人认为,这篇论文的贡献就是开创了使用GAN做小目标检测的方法,但实验结果、算法设计都不怎么理想。
(1)核心idea和算法设计
本文的核心idea,是小目标的特征少,想用GAN来增强小目标的特征,缩小小目标特征和大目标特征之间的差异。但是,在具体实现时,是把图像分成了只含有小目标的图像和只含有大目标的图像,小目标图像经过backbone和生成器生成super-resolved特征,大目标图像经过backbone生成大目标特征,通过对抗训练让判别器分辨不出super-resolved特征和大目标特征,但super-resolved特征和大目标特征不是同一张图像的特征,也不是同一个目标的特征,甚至不是同一类目标的特征,两种特征最主要的差异我认为是目标类别、目标的姿态、拍摄视角、图像背景等的差异,而不是尺度的差异,怎么能说缩小了小目标和大目标之间的特征差异呢?
我认为应该这样设计,大目标图像缩放成小目标图像,然后大目标图像生成大目标特征,缩放的小目标图像经过生成器获得super-resolved特征,然后通过对抗训练让判别器分辨不出super-resolved特征和大目标特征,这样可以说GAN缩小了小目标和大目标之间的特征差异。(很开心,后文的MTGAN和TPS的设计方法和我认为的一样)
(2)backbone网络的选择、检测流程设计不合常理
1)2017年已经出现了ResNet(2015年),不明白为什么还在用VGG?
2)其次,论文4.1节中说,不同数据集上使用的提取proposals的方法不一样,在Tsinghua-Tencent 100K上使用RPN,而在Caltech benchmark上使用的是2014年的论文《Fast feature pyramidsfor object detection》的ACF行人检测器提取proposals,不明白为啥这么做?先运行一遍ACF检测器获得proposals,再运行一遍自己提出的Perpetual GAN,计算量肯定会非常大。
(3)实验效果不显著
论文对Tsinghua-Tencent 100K数据集进行了删减,删减后,Tsinghua-Tencent 100K的测试集剩下了小目标3270个实例,中目标3829,大目标599,感觉数据量有点少;而且精度提高也不多,相比SOTA(Tsinghua-Tencent 100K的baseline),小目标的P和R指标分别提高了2%和2%,但是不知道目标检测的常用指标mAP提高了多少,Tsinghua-Tencent 100K数据集不使用mAP指标吗?有了解的大佬能否指点一下?
论文4.5节给出了在通用目标检测数据集VOC上的效果,效果不错,但是只在其中几个类上作比较(这几个类的目标比较小),而且是和fast RCNN比,这可是2017年啊,faster RCNN早就出了,而且前面Tsinghua-Tencent 100K数据集上就和faster rcnn比较过了,这里在VOC上却偏偏和fast rcnn比较。

















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









