







 文章介绍了如何使用Pandas的DataFrame方法检测和处理缺失值。`isna()`和`notna()`用于检测缺失值,`dropna()`用于删除含有缺失值的行或列,`fillna()`则用于填充缺失值,支持多种填充策略。文章通过实例详细阐述了这些函数的使用和参数配置。
文章介绍了如何使用Pandas的DataFrame方法检测和处理缺失值。`isna()`和`notna()`用于检测缺失值,`dropna()`用于删除含有缺失值的行或列,`fillna()`则用于填充缺失值,支持多种填充策略。文章通过实例详细阐述了这些函数的使用和参数配置。
1.检测空值
1.1 DataFrame.isna()
df.isna()对缺失值进行检测,返回一个与原始DataFrame大小相同的布尔型DataFrame。检测到None、np.nan、NaT返回True,否则返回False。’ '空字符串不是视为空值。
原始数据如下:
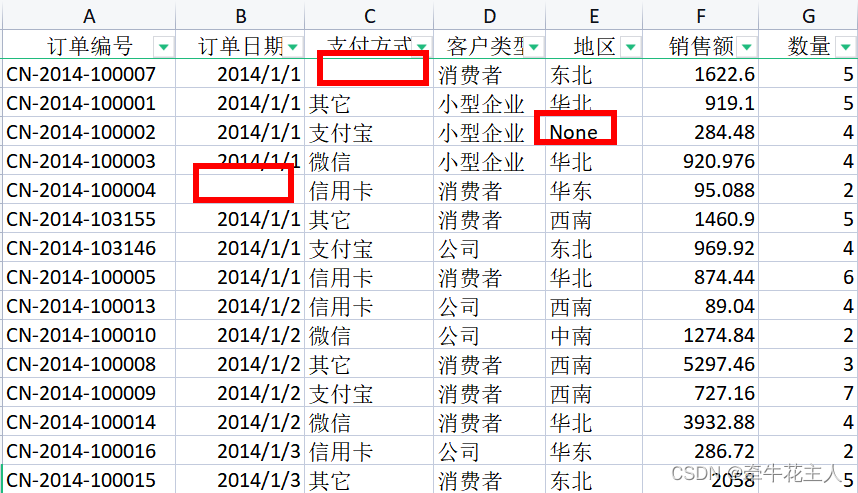
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.shape)
order.loc[2, '客户类型'] = np.nan
order.loc[3, '地区'] = ''
print(order.head())
print(order.isna().head())
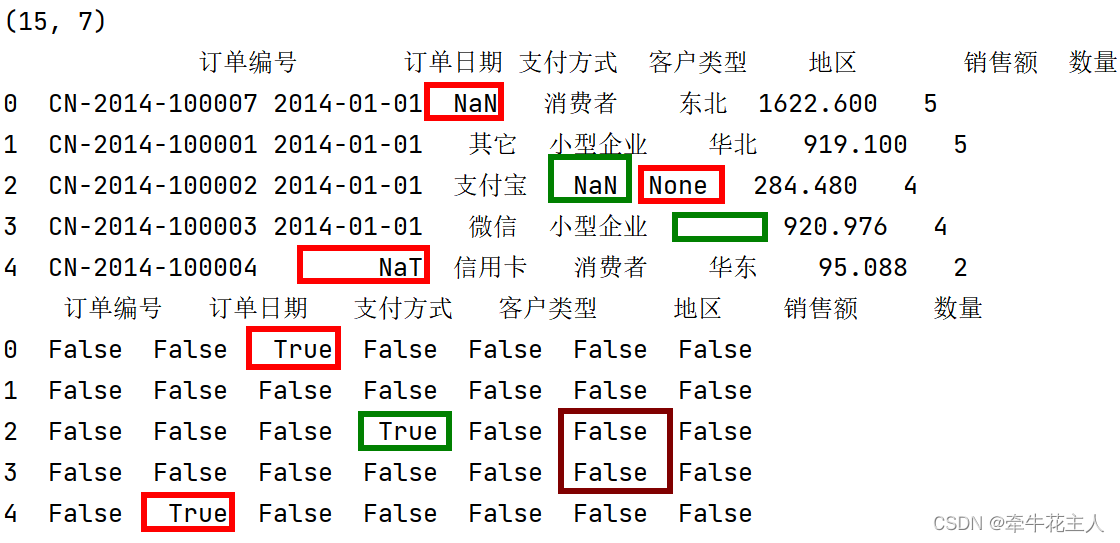
单独对某列数据空值进行检测
print(order['客户类型'].isna().head())

1.2 DataFrame.notna()
与df.isna()相反,函数df.notna()检测非缺失值,返回与原始DataFrame大小相同的DataFrame,非空值返回True,None、NaN、时间空值NaT返回False。
print(order.notna().head())
print(order['客户类型'].notna().head())

2. 删除空值
dropna()方法
2.1 函数功能
移除缺失值,当inplace取值为False时,返回数据类型为DataFrame,当inplace=True,返回数据类型为None
2.2 函数语法
DataFrame.dropna(*, axis=0, how=_NoDefault.no_default, thresh=_NoDefault.no_default, subset=None, inplace=False, ignore_index=False)
2.3 函数参数
| 参数 | 含义 |
|---|---|
| axis | 指定去除包含缺失值的行还是列:取值为0或’index’:去除包含空值的行;1或‘colum’:去除包含空值的列。默认值为0 |
| how | 取值为any(默认):删除存在空值的行/列,取值为all:删除所有元素均为空值的行/列 |
| thresh | 整数n,可选参数,指定行/列元素至少n个非空值才会被保留 |
| subset | 可选参数,列标签或者列标签组成的列表,指定查找缺失值的范围,若要删除行9axis=0),则指定在哪几列进行查找,若要删除列(axis=1),则指定在哪几行存在缺失值 |
| inplace | 布尔型,默认取值为False:创建新DataFrame,取值为True时:改变原有DataFrame |
| ignore_index | 布尔型,默认为False:不改变索引标签 |
2.3.1 参数取默认值
此时存在缺失值的行均会被删除,结果会新建DataFrame,原有DataFrame不会被改变,行索引没有自动补齐。
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.shape)
order.loc[2, '客户类型'] = np.nan
order.loc[3, '地区'] = ''
print(order.head())
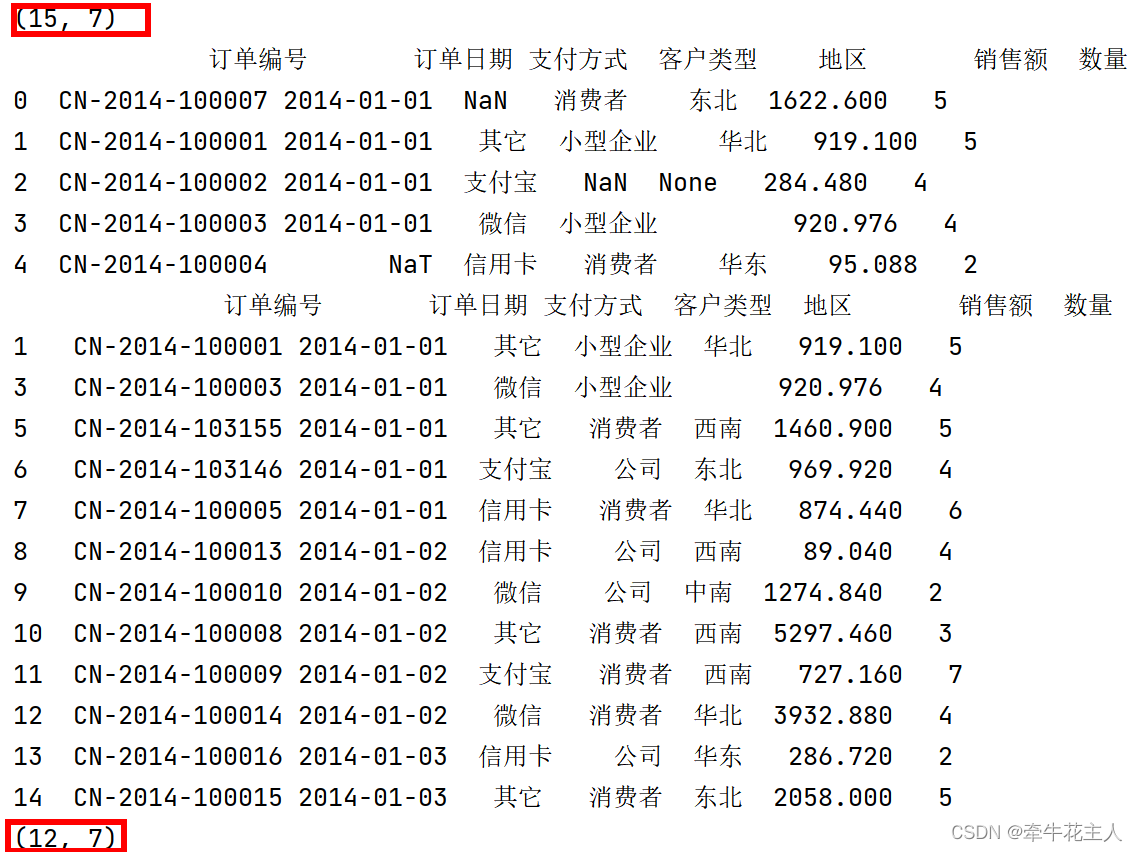
# 1. 删除存在缺失值的行
print(order.dropna())
print(order.dropna().shape)
2.3.2 参数thresh
行/列至少有多少个非空值才会被保留下来,不进行删除
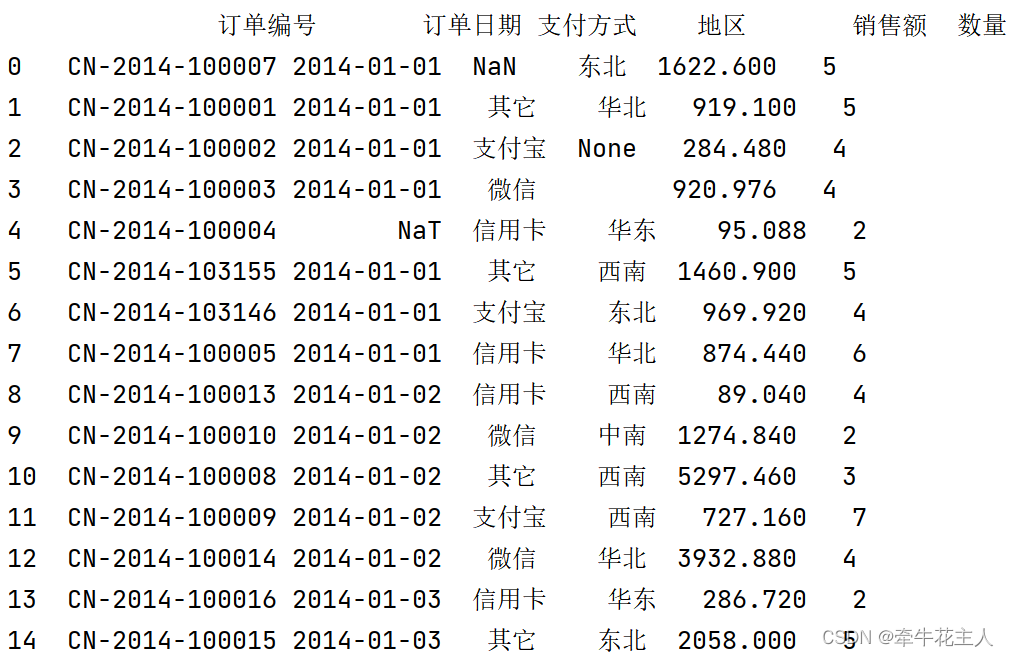
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
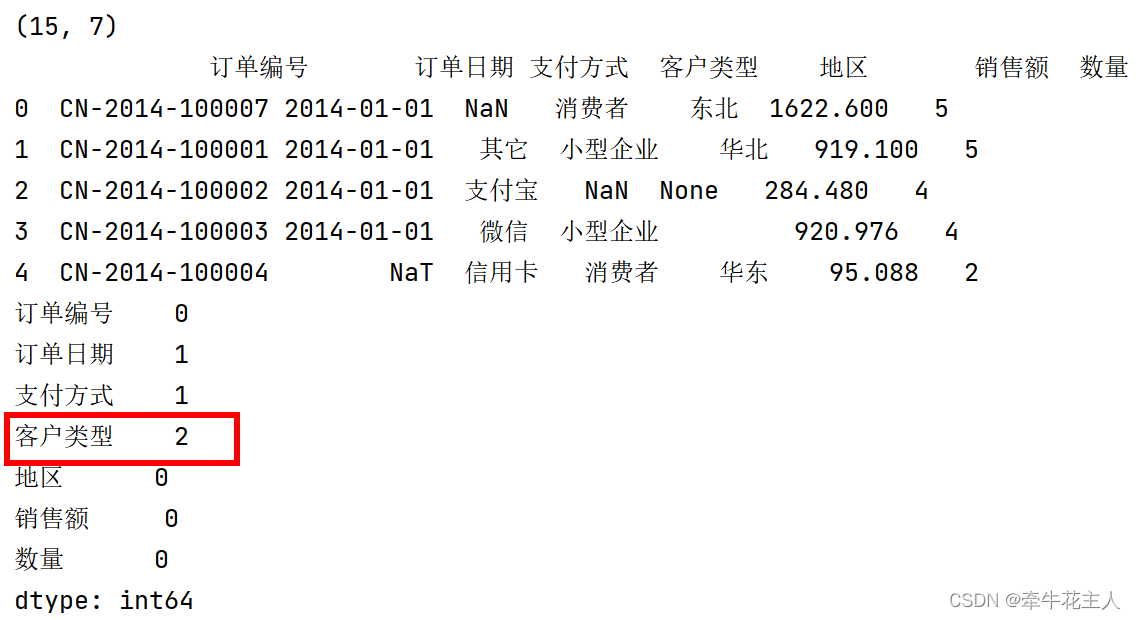
print(order.shape)
order.loc[[2,10], '客户类型'] = np.nan
order.loc[3, '地区'] = ''
print(order.head())
print(order.isna().sum(axis=0))
print(order.dropna(axis=1, thresh=14))
2.3.3 参数subset
指定查找缺失值的范围
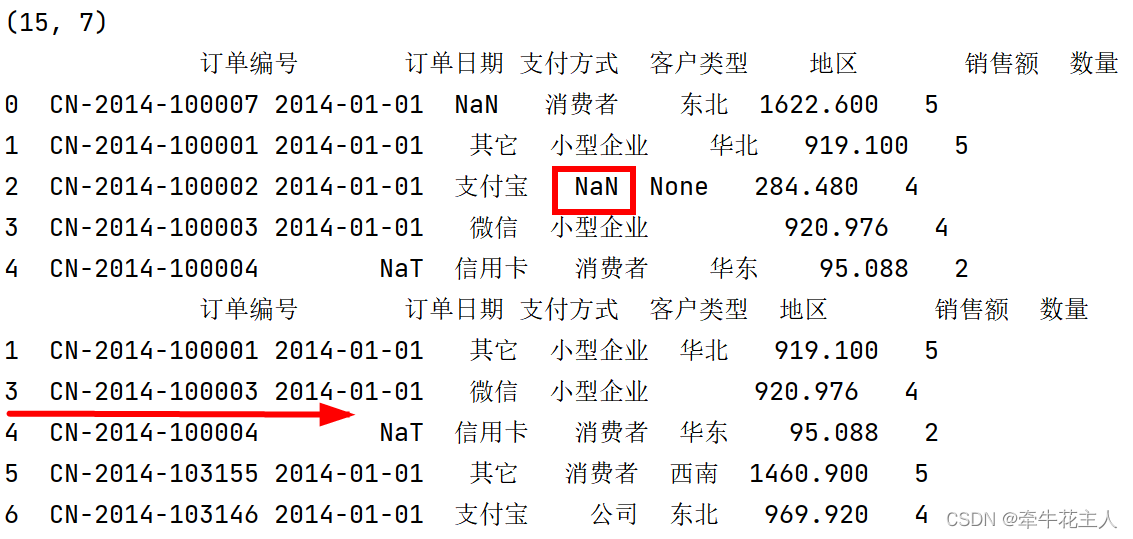
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.shape)
order.loc[[2, 10], '客户类型'] = np.nan
order.loc[3, '地区'] = ''
print(order.head())
print(order.dropna(axis=0, subset=['支付方式','客户类型']).head())
2.3.4 参数inplace
默认情况下,删除缺失值后会创建新的DataFrame ,但是通过指定Inplace=True,可以实现对原DataFrame的替换
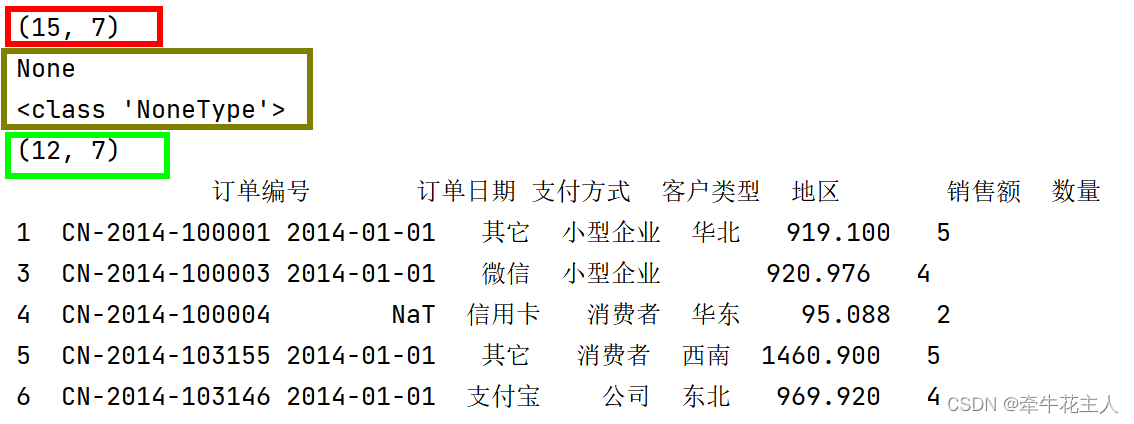
print(order.dropna(axis=0, subset=['支付方式','客户类型']).head())
print(order.shape) #可以发现删除缺失值后数据order的大小并未发生变化
print(order.dropna(axis=0, subset=['支付方式','客户类型'], inplace=True))
# inplace=True:返回None,直接修改原始数据
print(type(order.dropna(axis=0, subset=['支付方式','客户类型'], inplace=True)))
print(order.shape)
print(order.head())
3.填充空值
3.1 函数功能
用指定的方法填充空值,Inplace=False,返回DataFrame,inplace=True,返回None。
3.2 函数语法
DataFrame.fillna(value=None, *, method=None, axis=None, inplace=False, limit=None, downcast=None)
3.3 函数参数
| 参数 | 含义 |
|---|---|
| value | 填充缺失值的值,取值可以是标量,字典,Series或者DataFrame |
| mentod | 填充空值的方法:ffill:使用缺失值前的值进行填充;backfill/bfill:使用缺失值后面的值进行填充 |
| axis | 沿着行/列填充缺失值,0或“index”(默认):按行填充;1或“columns”:按列填充 |
| inplace | 布尔型,默认取值为False,不修改原DataFrame |
| limit | 整数,填充的缺失值数量的最大值,默认为None:填充所有的缺失值 |
| downcast | 字典,默认为None,不理解 |
3.3.1 默认参数填充
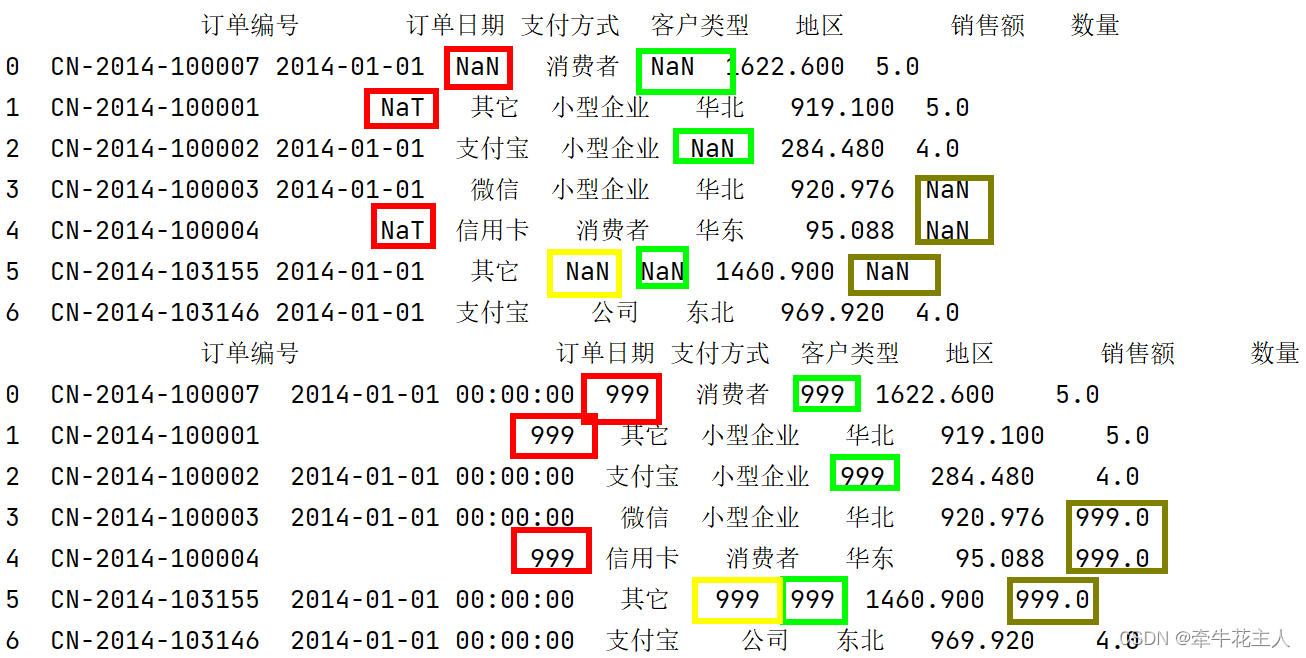
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order)
# 1. 默认参数填充
print(order.fillna(999))
3.3.2 传入字典,不同列指定不同填充值
# 2.不同列指定不同的缺失值
print(order.fillna({'订单日期':'2022-07-07','支付方式':'未知'}))
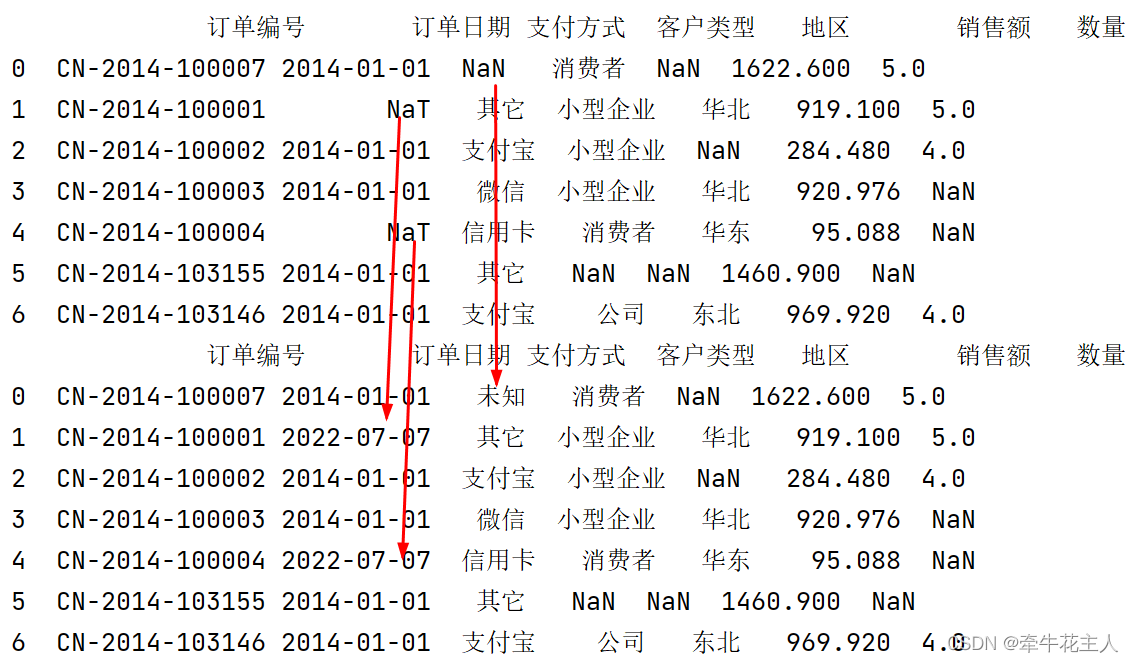
3.3.3 指定填充方法method
# 3. 用缺失值前面的值填充
print(order.fillna(method='ffill'))
# 4.用缺失值后面的值填充
print(order.fillna(method='bfill'))
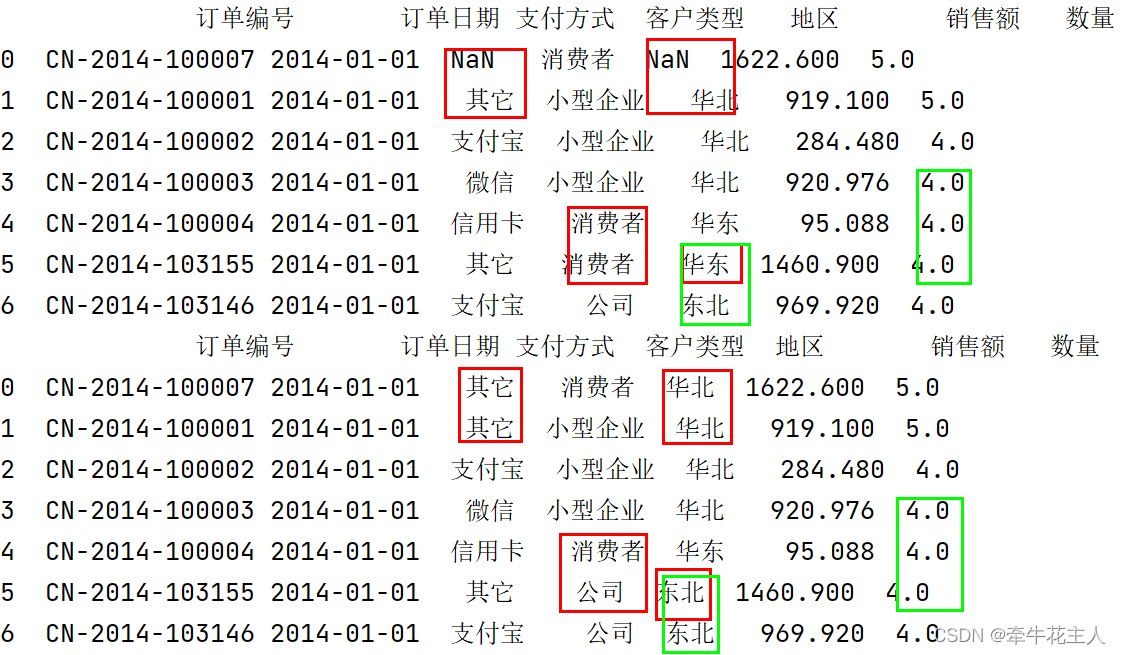
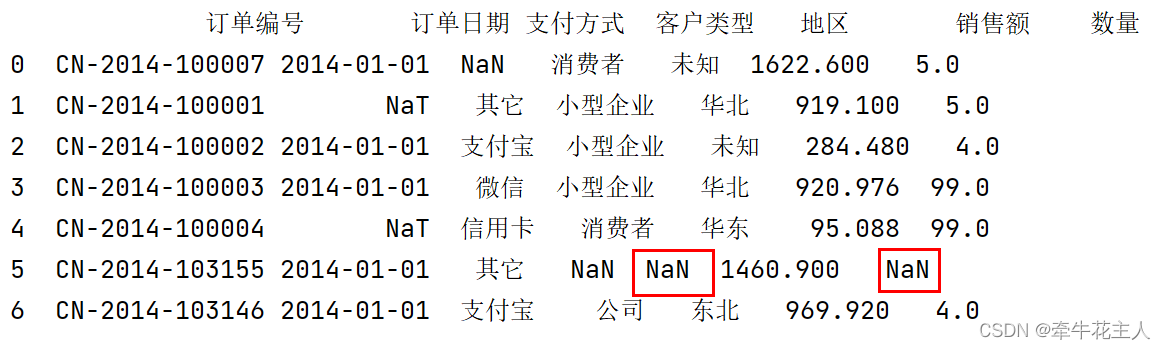
3.3.4 设置最大填充数量
当行/列中的缺失值个数大于指定的limit值时,剩下的缺失值将不被填充
# 5.指定填充缺失值次数最大值
print(order.fillna({'地区':'未知','数量':99},limit=2))

















 1790
1790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









