 Pandas缺失数据处理全攻略
Pandas缺失数据处理全攻略





处理 Pandas 中的缺失数据
在 Pandas 中,缺失值用None 或 NaN表示,这可能是由于未收集数据或条目不完整而发生的。让我们探索如何检测、处理和填充 DataFrame 中的缺失值,以确保准确的分析。
目录
- 检查 Pandas DataFrame 中的缺失值
- 填充 Pandas 中的缺失值
- 删除 Pandas 中的缺失值
检查 Pandas DataFrame 中的缺失值
为了识别和处理缺失值,Pandas 提供了两个有用的函数:isnull()和notnull()。这些函数有助于检测某个值是否为NaN,从而更容易清理和预处理 DataFrame 或 Series 中的数据。
1. 使用 isnull() 检查缺失值
isnull()返回布尔值的 DataFrame,其中True表示缺失数据 ( NaN )。当您想要定位和处理数据集中的缺失数据时,这很有用。
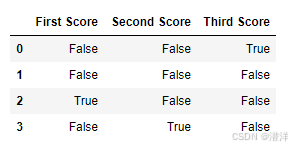
示例 1:检测 DataFrame 中的缺失值
Python
# Importing pandas and numpy
import pandas as pd
import numpy as np
# Sample DataFrame with missing values
data = {'First Score': [100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score': [np.nan, 40, 80, 98]}
df = pd.DataFrame(data)
# Checking for missing values using isnull()
missing_values = df.isnull()
print(missing_values)
输出:
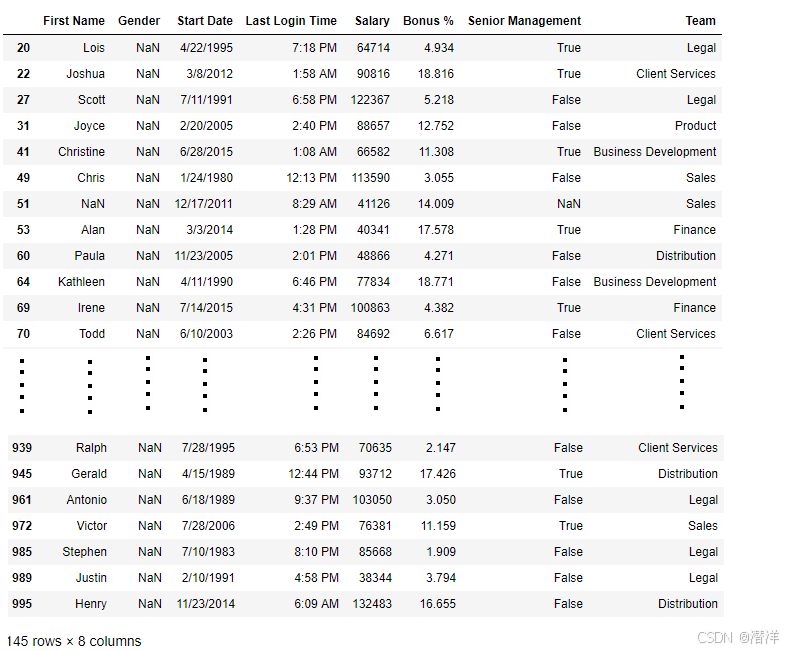
示例 2:根据缺失值过滤数据
在本例中,isnull()函数应用于“性别”列,以筛选和显示缺少性别信息的行。
Python
import pandas as pd
data = pd.read_csv("employees.csv")
bool_series = pd.isnull(data["Gender"])
missing_gender_data = data[bool_series]
print(missing_gender_data)
输出:
使用 notnull() 检查缺失值
notnull()返回布尔值的 DataFrame,其中 True 表示非缺失数据。当您想关注包含有效、非缺失数据的行时,此函数非常有用。
示例 3:检测 DataFrame 中的非缺失值
Python
# Importing pandas and numpy
import pandas as pd
import numpy as np
# Sample DataFrame with missing values
data = {'First Score': [100, 90, np.nan, 95],
&nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











