







 本文详细介绍了CUDA中的流(stream)概念及其在异步并发执行中的作用。通过对比默认串行流、单个异步流和多个异步流的性能,展示了如何利用CUDA流提高GPU计算效率。在支持设备重叠功能的GPU上,通过创建和管理多个stream,可以实现在数据传输和计算之间的重叠,从而减少整体执行时间。文中还给出了具体的代码示例,展示如何使用CUDA流进行数据分块传输和计算,以达到性能提升的目的。
本文详细介绍了CUDA中的流(stream)概念及其在异步并发执行中的作用。通过对比默认串行流、单个异步流和多个异步流的性能,展示了如何利用CUDA流提高GPU计算效率。在支持设备重叠功能的GPU上,通过创建和管理多个stream,可以实现在数据传输和计算之间的重叠,从而减少整体执行时间。文中还给出了具体的代码示例,展示如何使用CUDA流进行数据分块传输和计算,以达到性能提升的目的。
文章目录
概念
本文章实例代码在本人git下
https://github.com/chongbin007/cuda_learning_test/tree/main/4stream
异步并发执行
异步调用:即使GPU没有计算完,也会直接返回给host线程。
比如:
- kernel函数启动
- device中的memory copy
- memory copy从host 到 device,在memory小于64K时
- 带Async后缀的函数
- 内存设置函数的调用
overlap data
支持重叠功能的设备的这一特性很重要,可以在一定程度上提升GPU程序的执行效率。一般情况下,CPU内存远大于GPU内存,对于数据量比较大的情况,不可能把CPU缓冲区中的数据一次性传输给GPU,需要分块传输,如果能够在分块传输的同时,GPU也在执行核函数运算,这样的异步操作,就用到设备的重叠功能,能够提高运算性能。
能够在执行一个CUDA核函数运算的同时,还能在主机和设备之间执行复制数据操作。也就是GPU在计算的时候,同时还可以进行host和device之间的数据传输。
使用CUDA流,首先要选择一个支持设备重叠功能的设备,支持设备重叠功能的GPU。
Streams
https://zhuanlan.zhihu.com/p/51402722
https://blog.csdn.net/dcrmg/article/details/55107518
为何使用stream
如果我们开启多个核函数,操作都是串行执行的。但是如果我们想并发执行,就可以开启多个stream。多个stream是并发执行的。每个stream中是串行执行。
用到CUDA的程序一般需要处理海量的数据,内存带宽经常会成为主要的瓶颈。
默认情况我们只使用一个stream。这个stream是串行执行的,
由于GPU和CPU不能直接读取对方的内存,CUDA程序一般会有一下三个步骤:
1)将数据从CPU内存转移到GPU内存,
2)GPU进行运算并将结果保存在GPU内存,
3)将结果从GPU内存拷贝到CPU内存。
如果不做特别处理,那么CUDA会默认只使用一个Stream(Default Stream)。在这种情况下,刚刚提到的三个步骤,必须串行处理。
如下图的一个示例:
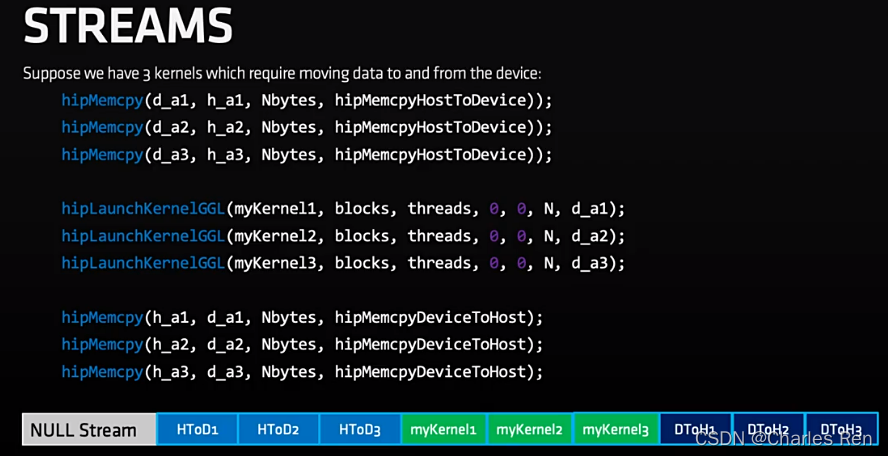
那么我们想将上面几步并行执行,可以开启多个stream来实现:
- 将数据拆分称许多块,每一块交给一个Stream来处理。
- 每一个Stream包含了上面三个步骤:
- 所有的Stream被同时启动,由GPU的scheduler决定如何并行。
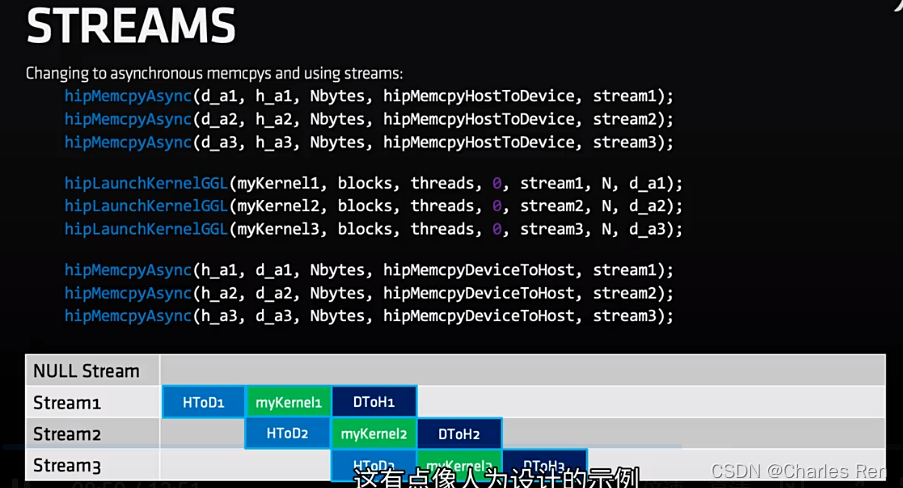
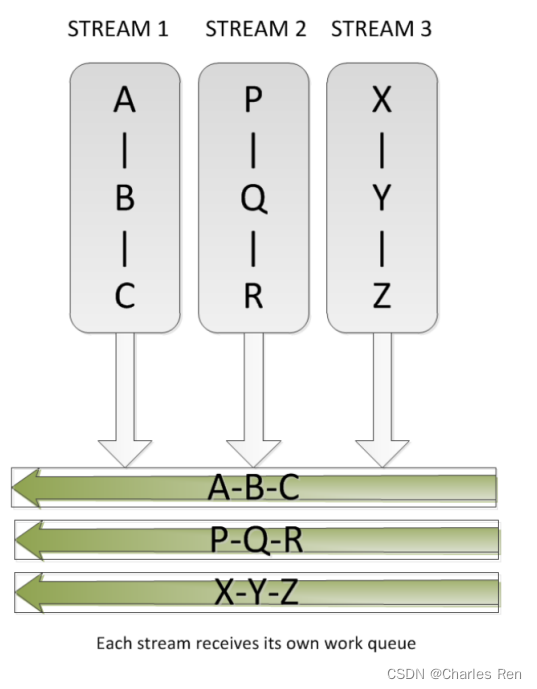
使用CUDA流,首先要选择一个支持设备重叠(Device Overlap)功能的设备,支持设备重叠功能的GPU。
default stream
https://docs.nvidia.com/cuda/cuda-runtime-api/stream-sync-behavior.html#stream-sync-behavior__default-stream
https://www.jianshu.com/p/a39a4742979e
默认stream:
所有的device操作其实都是在stream上的, 如果我们没有指定某个stream,则操作在一个默认stream上叫做null stream。
The default stream, used when 0 is passed as a cudaStream_t or by APIs。
如果一个API需要stream对象,传入参数0,则这个他使用的就是默认stream。
默认stream和其他stream不同,他是一个同步stream。
k_B<<<1, 1>>>();直接调用kernel函数是在创建的默认流上运行,不需要创建
而如果显示指定了运行在某个流上
k_C<<<1, 1, 0, s>>>();则需要在前面创建他。
串行,单流,多流性能对比
下面我先看一个例子:计算两个数组对应元素的和,输出到第三个数组中
默认stream串行执行
#include "cuda_runtime.h"
#include <iostream>
#include <stdio.h>
#include <math.h>
#include <time.h>
#define N (1024*1024) //每次从CPU传输到GPU的数据块大小
#define FULL_DATA_SIZE N*20 //总数据量
__global__ void kernel(int* a, int *b, int*c)
{
int threadID = blockIdx.x * blockDim.x + threadIdx.x;
//这里线程号应该小于FULL_DATA_SIZE
if (threadID < FULL_DATA_SIZE)
{
c[threadID] = (a[threadID] + b[threadID]) / 2;
}
}
//目的:计算两个数组,数组大小均为FULL_DATA_SIZE,的和
int main()
{
int *host_a, *host_b, *host_c;
int *dev_a, *dev_b, *dev_c;
//在GPU上分配内存
cudaMalloc((void**)&dev_a, FULL_DATA_SIZE * sizeof(int));
cudaMalloc((void**)&dev_b, FULL_DATA_SIZE * sizeof(int));
cudaMalloc((void**)&dev_c, FULL_DATA_SIZE * sizeof(int));
//在CPU上分配:可分页内存
//数组大小FULL_DATA_SIZE
host_a = (int*)malloc(FULL_DATA_SIZE * sizeof(int));
host_b = (int*)malloc(FULL_DATA_SIZE * sizeof(int));
host_c = (int*)malloc(FULL_DATA_SIZE * sizeof(int));
//主机上的两个数组随机赋值
for (int i = 0; i < FULL_DATA_SIZE; i++) {
host_a[i] = i;
host_b[i] = FULL_DATA_SIZE - i;
}
//copy host to device
cudaMemcpy(dev_a, host_a, FULL_DATA_SIZE * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, host_b, FULL_DATA_SIZE * sizeof(int), cudaMemcpyHostToDevice);
std::cout << "启动 "<< std::endl;
cudaDeviceSynchronize();
//启动计时器
cudaEvent_t start, stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
//启动函数,做数值加法
kernel <<<FULL_DATA_SIZE / 1024, 1024 >>> (dev_a, dev_b, dev_c);
//数据拷贝回主机
cudaMemcpy(host_c, dev_c, FULL_DATA_SIZE * sizeof(int), cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
std::cout << "event计时: " << elapsedTime <<"ms"<< std::endl;
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
执行时间event计时: 113.67ms
使用一个stream异步传输
#include "cuda_runtime.h"
#include <iostream>
#include <stdio.h>
#include <math.h>
#define N (1024*1024) //每次从CPU传输到GPU的数据块大小
#define FULL_DATA_SIZE N*20 //总数据量
__global__ void kernel(int* a, int *b, int*c)
{
int threadID = blockIdx.x * blockDim.x + threadIdx.x;
//这里每次计算N个数组
if (threadID < N)
{
c[threadID] = (a[threadID] + b[threadID]) / 2;
}
}
//使用单流:目的:计算两个数组,数组大小均为FULL_DATA_SIZE,的和
int main()
{
//获取设备属性
cudaDeviceProp prop;
int deviceID;
cudaGetDevice(&deviceID);
cudaGetDeviceProperties(&prop, deviceID);
//检查设备是否支持重叠功能,不支持则不能使用多流加速
if (!prop.deviceOverlap)
{
printf("No device will handle overlaps. so no speed up from stream.\n");
return 0;
}
//创建一个CUDA stream
cudaStream_t stream;
cudaStreamCreate(&stream);
int *host_a, *host_b, *host_c;
int *dev_a, *dev_b, *dev_c;
//在GPU上分配内存: GPU上分配的内存大小是N
cudaMalloc((void**)&dev_a, N * sizeof(int));
cudaMalloc((void**)&dev_b, N * sizeof(int));
cudaMalloc((void**)&dev_c, N * sizeof(int));
//在CPU上分配:页锁定内存,使用流的时候,要使用页锁定内存
cudaMallocHost((void**)&host_a, FULL_DATA_SIZE * sizeof(int));
cudaMallocHost((void**)&host_b, FULL_DATA_SIZE * sizeof(int));
cudaMallocHost((void**)&host_c, FULL_DATA_SIZE * sizeof(int));
//主机上的内存赋值
for (int i = 0; i < FULL_DATA_SIZE; i++) {
host_a[i] = i;
host_b[i] = FULL_DATA_SIZE - i;
}
//启动计时器
cudaEvent_t start, stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
// 内存数据能够在分块传输的同时,GPU也在执行核函数运算,这样的异步操作,可以提升性能
// 将输入缓冲区划分为更小的块,每次向GPU copy N块数据,在stream上执行。并在每个块上执行“数据传输到GPU”,“计算”,“数据传输回CPU”三个步骤
for (int i = 0; i < FULL_DATA_SIZE; i += N) {
//异步将host数据copy到device并执行kernel函数
//因为这个操作是异步的,所以在copy数据的时候,kernel函数就可以开始执行。也就是边copy边执行计算
//比如第一个N块数据拷贝完了,kernel函数就计算,这时第二个N块数据同时进行拷贝。但是如果是没有stream,
//就必须要等到所有数据全部拷贝完再执行计算,这么做可以提高性能
cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
//注意这里开启线程数是N, 第三个参数是shared_memory大小,第四个参数是指定运行kernel的stream
//如果不指定stream则运行在默认stream上
kernel <<<N / 1024, 1024, 0, stream >>> (dev_a, dev_b, dev_c);
cudaMemcpyAsync(host_c + i, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
std::cout << "消耗时间GPU: " << elapsedTime <<"ms"<< std::endl;
cudaStreamDestroy(stream);
// free stream and mem
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
消耗时间GPU: 84.6797ms
对比发现有了stream,我们可以把数据分块,拷贝和计算同步进行从而提升运行效率。
使用20个stream异步执行
#include <stdio.h>
#include <iostream>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#define N_STREAM 20
#define N (1024*1024)
#define FULL_DATA_SIZE (N * N_STREAM)
__global__ void MyKernel(int *a, int *b, int *c){
int threadID = threadIdx.x + blockIdx.x * blockDim.x;
if (threadID < FULL_DATA_SIZE){
c[threadID] = (a[threadID] + b[threadID]) / 2;
}
}
int main(void){
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice(&whichDevice);
cudaGetDeviceProperties(&prop, whichDevice);
if (!prop.deviceOverlap){
printf("Device will not handle overlaps, so no speed up from streams\n");
return 0;
}
cudaEvent_t start, stop;
float elapsedTime;
//启动计时器
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0); //在stream0中插入start事件
//初始化N_STREAM个流
cudaStream_t stream[N_STREAM];
for (int i = 0; i < N_STREAM; ++i)
cudaStreamCreate(&stream[i]);
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0;
//在GPU上分配内存: GPU上分配的内存大小是N
cudaMalloc((void **)&dev_a0, FULL_DATA_SIZE * sizeof(int));
cudaMalloc((void **)&dev_b0, FULL_DATA_SIZE * sizeof(int));
cudaMalloc((void **)&dev_c0, FULL_DATA_SIZE * sizeof(int));
//在CPU上分配:页锁定内存,使用流的时候,要使用页锁定内存
cudaHostAlloc((void **)&host_a, FULL_DATA_SIZE * sizeof(int),
cudaHostAllocDefault);
cudaHostAlloc((void **)&host_b, FULL_DATA_SIZE * sizeof(int),
cudaHostAllocDefault);
cudaHostAlloc((void **)&host_c, FULL_DATA_SIZE * sizeof(int),
cudaHostAllocDefault);
//主机上的内存赋值
for (int i = 0; i < FULL_DATA_SIZE; i++){
host_a[i] = i;
host_b[i] = FULL_DATA_SIZE - i;
}
//每个流计算N个数据:比如stream0计算数据0~(N-1), stream1计算数据N~(2N-1)
for (int i = 0; i < N_STREAM; i++) {
//host copy to device
cudaMemcpyAsync(dev_a0 + i * N, host_a + i * N, N, cudaMemcpyHostToDevice, stream[i]);
cudaMemcpyAsync(dev_b0 + i * N, host_b + i * N, N, cudaMemcpyHostToDevice, stream[i]);
MyKernel <<<N / 1024, 1024, 0, stream[i]>>>(dev_a0 + i * N, dev_b0 + i * N, dev_c0 + i * N);
cudaMemcpyAsync(host_c + i * N, dev_c0 + i * N, N, cudaMemcpyDeviceToHost, stream[i]);
}
//在停止应用程序的计时器之前,首先将进行同步
for (int i = 0; i < N_STREAM; ++i)
cudaStreamSynchronize(stream[i]);
cudaEventRecord(stop, 0);//在stream0中插入stop事件
//等待event会阻塞调用host线程,同步操作,等待stop事件.
//该函数类似于cudaStreamSynchronize,只不过是等待一个event而不是整个stream执行完毕
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
std::cout << "消耗时间: " << elapsedTime <<"ms" << std::endl;
//销毁流
for (int i = 0; i < N_STREAM; ++i)
cudaStreamDestroy(stream[i]);
//释放流和内存
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaFree(dev_a0);
cudaFree(dev_b0);
cudaFree(dev_c0);
return 0;
}
消耗时间: 15.9396ms
可以看到,当使用20个stream来计算相同大小的数组,性能有了显著提升。
stream相关函数
//基本函数
cudaStream_t stream//定义流
cudaStreamCreate(cudaStream_t * s)//创建流
cudaStreamDestroy(cudaStream_t s)//销毁流
//显性同步
cudaStreamSynchronize()//同步单个流:等待该流上的命令都完成
cudaDeviceSynchronize()//同步所有流同步:等待整个设备上流都完成
cudaStreamWaitEvent()//通过某个事件:等待某个事件结束后执行该流上的命令
cudaStreamQuery()//查询一个流任务是否完成
//回调
cudaStreamAddCallback()//在任何点插入回调函数
//优先级
cudaStreamCreateWithPriority()
cudaDeviceGetStreamPriorityRange()
创建三个stream
cudaStream_t stream[3];
for (int i = 0; i < 3; ++i)
cudaStreamCreate(&stream[i]);
参考资料
https://blog.csdn.net/mounty_fsc/article/details/51092933
https://blog.csdn.net/huikougai2799/article/details/106135203
https://www.cnblogs.com/1024incn/p/5891051.html
https://blog.csdn.net/haima1998/article/details/80279427
https://blog.csdn.net/dcrmg/article/details/55107518
https://zhuanlan.zhihu.com/p/51402722



















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











