







 本文使用R语言基于共现关系,从《雪中悍刀行》小说文本中提取人物关系网络,并用networkD3进行可视化。通过分词、多称谓人物合并,统计人物权重和共现频率,最终生成动态网络图。
本文使用R语言基于共现关系,从《雪中悍刀行》小说文本中提取人物关系网络,并用networkD3进行可视化。通过分词、多称谓人物合并,统计人物权重和共现频率,最终生成动态网络图。
概述
雪中悍刀行作为现象级的网文,电视剧版即将上映,作为曾经的一员“妖孽”书粉,按捺不住想做点啥。最近在研究知识图谱,就以此为契机展开相关研究吧。
本文将基于简单共现关系,编写 R 代码从纯文本中提取出人物关系网络,并用 networkD3 将生成的网络可视化。
- 共现: 顾名思义,就是共同出现,关系紧密的人物往往会在文本中多段内同时出现,可以通过识别文本中已确定的人名,计算不同人物共同出现的次数和比率。当比率大于某一阈值,我们认为两个人物间存在某种联系。
由于共现概率比值的计算方法较为复杂,本文只使用最基础的共现统计,自行设定共现频率的阈值,并使用networkD3绘制交互式网络图.
数据来源
雪中悍刀行小说txt来源地址: https://www.txt80.com/xuanhuan/2017/07/txt1099.html
雪中主要人物表信息整理来源地址: https://baike.baidu.com/item/雪中悍刀行/7328338
数据准备
由于《雪中》人物较多、关系复杂,这次我们只统计其中最主要的一些角色的共现关系,首先通过雪中悍刀行的百度百科获取主要人物的介绍,手动整理为excel。
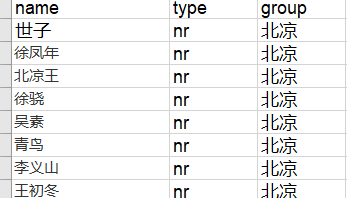
部分人物有多个称谓,所以需要再整理一份多称谓人物表,以便于后期对同一个人物多个称谓的数据进行合并
接下来在R中导入数据,包括上面的两个excel以及小说文本txt,并使用jiebaR对文本各段落进行分词
library(networkD3) # 画网络图
library(readxl) # 读取excel
library(tidyverse) # 分组统计
library(jiebaR) # 分词
# 人物名导入
name_df <- read_excel("人物表.xlsx")
# 多称谓人物表导入
dupName_df <- read_excel("多称谓人物.xlsx")
# 文档导入
texts = readLines("./雪中悍刀行.txt", encoding="gbk")
# 设置分词器
engine1 = worker()
engine1$bylines = TRUE
# 分词
seglist = segment(texts, engine1)
head(seglist)
## [[1]]
## [1] "书香门第" "岁" "梦" "整理"
##
## [[2]]
## [1] "附" "本" "作品" "来自" "互联网" "本人" "不" "做"
## [9] "任何" "负责" "内容" "版权" "归" "作者" "所有"
##
## [[3]]
## character(0)
##
## [[4]]
## character(0)
##
## [[5]]
## [1] "全" "本校" "对" "雪" "中" "悍" "刀" "行"
##
## [[6]]
## [1] "作者" "烽火" "戏" "诸侯"
可以看到分词结束后的结果是一个大的列表,其中每个元素代表一个段落中的分词
共现关系提取
首先提取共现词对,具体方法为提取每个段落中的主要人物,并对每个段落的不同主要人物形成两两的共现词对
共现词对提取
names = c() # 姓名字典
relationships = list() # 关系字典
lineNames = list() # 每段内人物关系
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2682
2682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











