







作者博客链接:Matryoshka Representation Learning (MRL) from the Ground Up | Aniket Rege
论文:https://arxiv.org/pdf/2205.13147.pdf
sbert库实现:Losses — Sentence-Transformers documentation
动态层
论文:https://arxiv.org/pdf/2402.14776v1.pdf
sbert库实现:https://www.sbert.net/docs/package_reference/losses.html#adaptivelayerloss
sbert组合实现:Losses — Sentence-Transformers documentation
Matryoshka Representation Learning
openai2024年1月25日更新了向量表示模型,比上一代openai的向量模型更强大。为了平衡计算成本和表示效果,使用了俄罗斯套娃向量表示(MRL)技术,传入维度参数后可以指定输出向量的维度大小。
MRL旨在设计一个灵活的表示可以适应不同下游任务的计算资源。MRL 为表示向量配备了所需的灵活性和多保真度,可以保证接近最优的精度与计算权衡。有了这些优势,MRL 实现了基于准确性和计算约束的自适应部署。
架构:
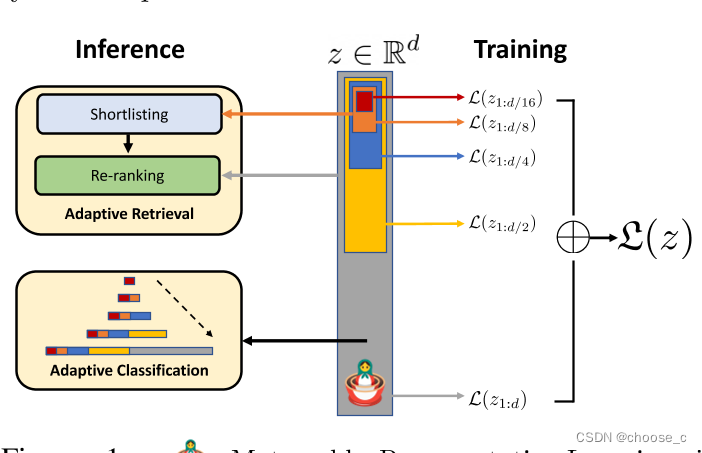
训练代码:MRL/train_mrl.py at main · TTurn/MRL · GitHub
2D Matryoshka Sentence Embeddings
尽管 MRL 的效率有所提高,但在获得嵌入之前仍然需要遍历所有 Transformer 层,这仍然是时间和内存消耗的主要因素。这提示考虑了固定数量的 Transformer 层是否会影响表示质量,以及是否使用中间层进行句子表示是可行的。本文引入一种新的句子嵌入模型,称为二维Matryoshka句子嵌入(2DMSE)。它支持嵌入大小和Transformer层的弹性设置,提供了比MRL更大的灵活性和效率。
架构:
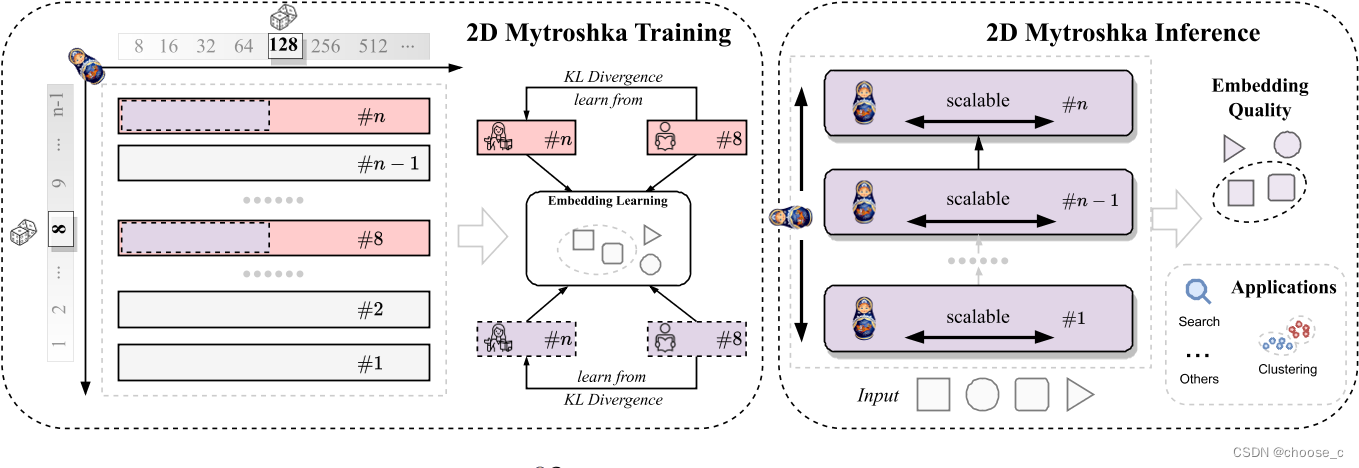
训练代码:















 2703
2703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









