







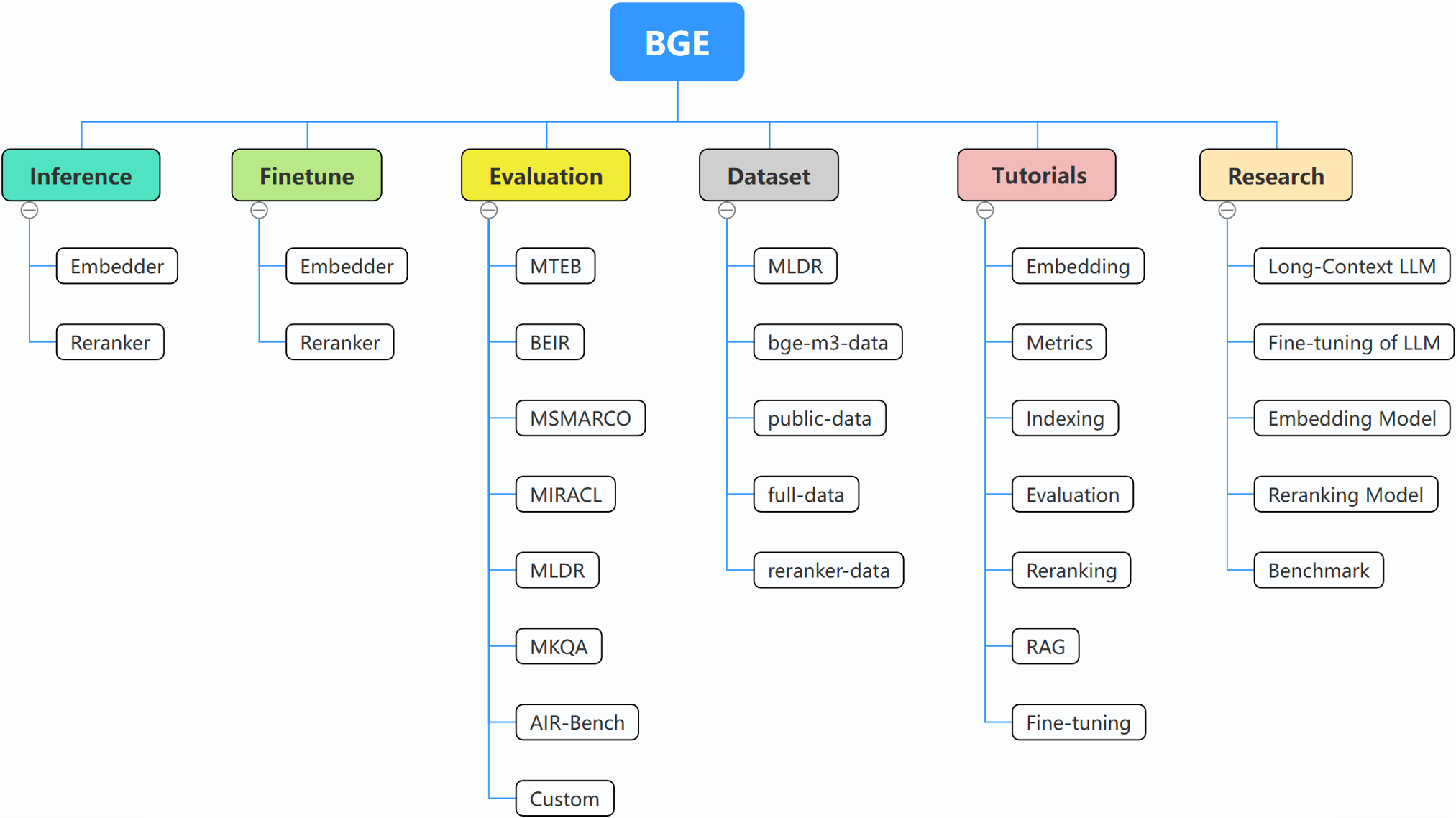
BGE (BAAI General Embedding) 专注于检索增强llm领域,目前包括以下项目:
智源 发布了其开源的中英文语义向量(embedding)模型BGE,此模型在多个重要指标上均超越了其他同类模型。
相关代码开源在FlagEmbedding项目下,这是一个专注于Embedding技术和模型的项目。
为了进一步评估中文语义向量的性能,智源团队还推出了全新的中文评测基准C-MTEB。
embedding模型的应用:
- embedding模型可以将各种数据(语言、图片等)转化为向量,并使用向量之间的距离来衡量数据的相关性。
- 在大模型时代,这种技术有助于解决大模型在回答问题时可能出现的问题,可以帮助大模型获取最新的知识。
- OpenAI、Google、Meta等大厂也都推出了自己的语义向量模型和API服务,催生了大量的应用和工具,如LangChain、Pinecone等。
BGE模型特点:
- BGE模型在语义检索精度和整体表征能力上都表现出色,超过了OpenAI的text embedding 002等模型。
- 虽然性能出色,BGE模型的参数量却很小,这使得它在使用时成本更低。
C-MTEB评测基准: 考虑到中文社区缺乏全面的评测基准,智源团队特意发布了C-MTEB,这是一个全面的中文语义向量评测基准,涵盖了6大类评测任务和31个数据集。所有的测试数据和代码也都已开源。
BGE的技术亮点:
- 高效预训练和大规模文本微调;
- 在两个大规模语料集上采用了RetroMAE预训练算法,进一步增强了模型的语义表征能力;
- 通过负采样和难负样例挖掘,增强了语义向量的判别力;
- 借鉴Instruction Tuning的策略,增强了在多任务场景下的通用能力。
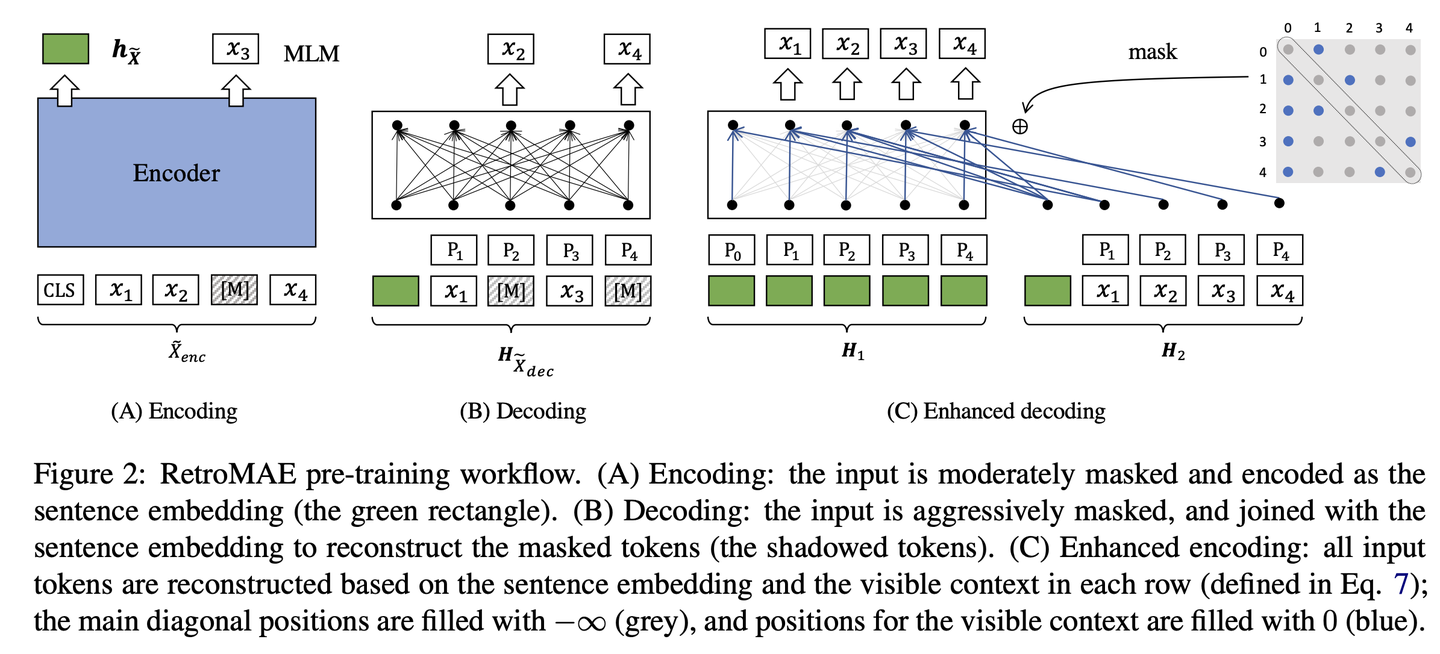
RetroMAE预训练
主要思想是encoder用小一点的mask rate得到sentence embedding,然后decoder用大一点的mask rate结合encoder得到的sentence embedding进行重构
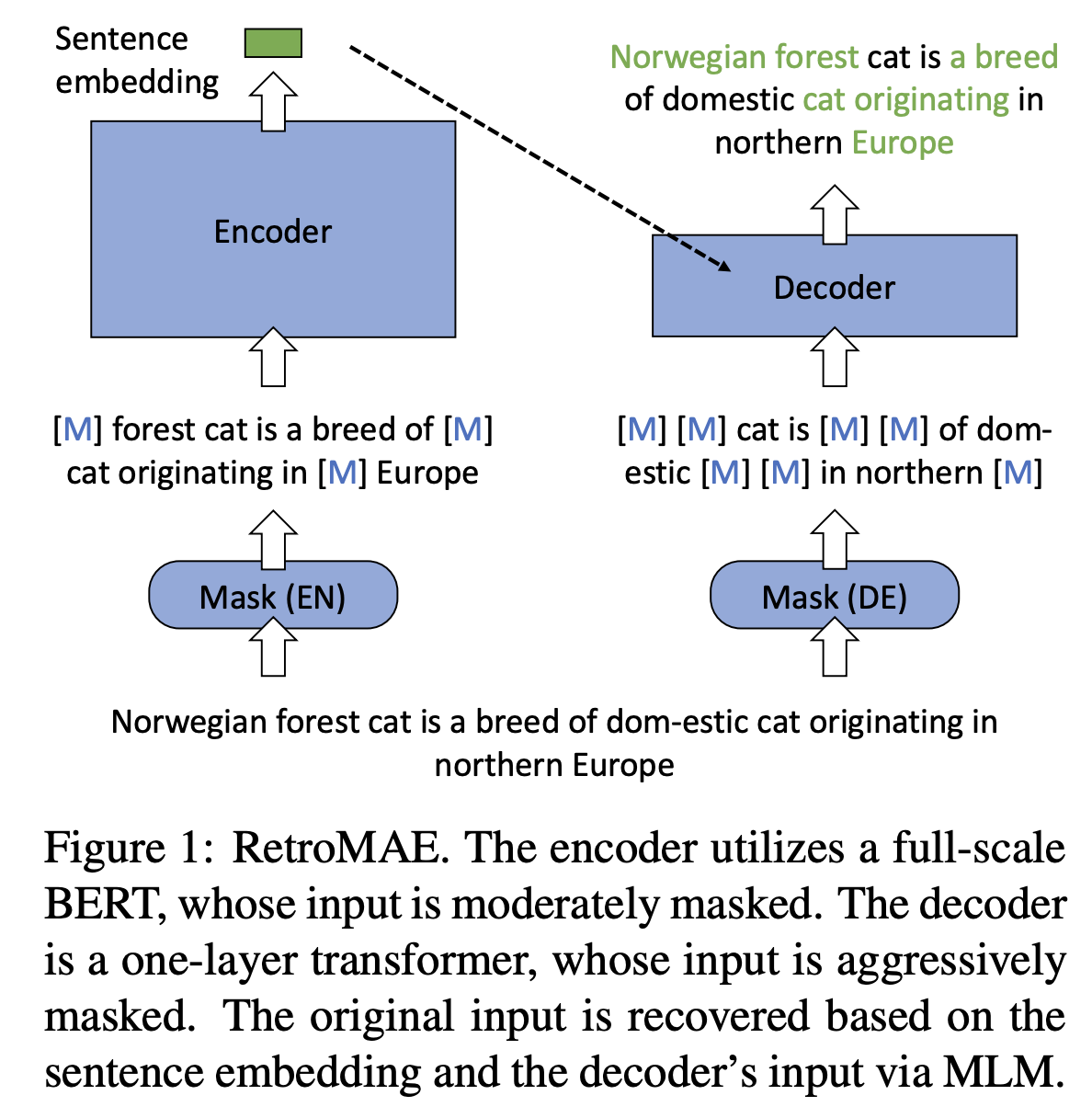
此外,为了使得每个token使用的context信息不同,RetroMAE还使用了增强解码的方法
微调
主要通过对比学习和Instruction Tuning的思想
对比学习是一种训练模型的方法,通过比较正例和反例来学习数据的表示。
- 输入数据的格式:模型接受三元组格式的数据作为输入,包括一个查询(query),一个正例(positive),和一个反例(negative)。
- in-batch negatives 策略:除了上述三元组中的反例外,他们还采用了“in-batch negatives”策略,意思是在同一个批次的数据中,使用其他数据作为额外的反例。
- cross-device negatives sharing method:这是一种在不同的GPU之间共享反例的方法,目的是大大增加反例的数量。
- 训练硬件和参数:使用了48个A100(40G)的GPU进行训练。批次大小为32,768,因此每个查询在批次中有65,535个反例。使用了AdamW优化器,学习率为1e-5。对比损失的温度为0.01。
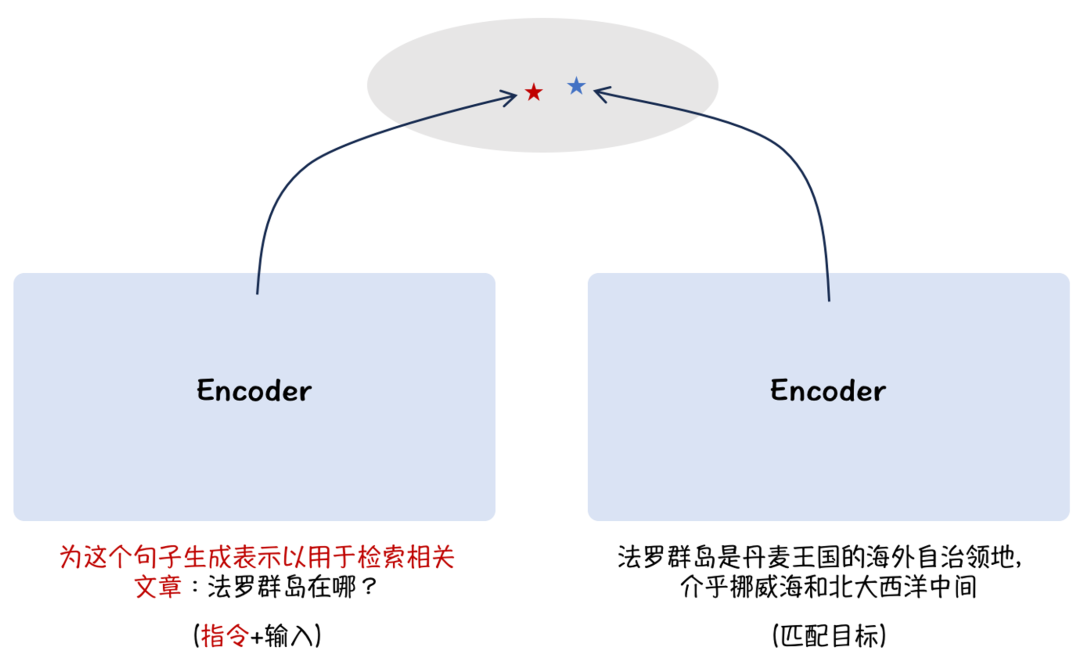
在训练中为检索任务的查询添加了instruction。 对于英语,指令是Represent this sentence for searching relevant passages: ; 对于中文,指令是为这个句子生成表示以用于检索相关文章:. 在评测中,针对段落检索任务的任务需要在查询中添加指令,但不需要为段落文档添加指令。
什么是FlagEmbedding?
FlagEmbedding 能将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。
论文:https://arxiv.org/pdf/2309.07597.pdf
代码:https://github.com/FlagOpen/FlagEmbedding
参考资料
【transformers二次开发——(定义自己的数据加载器 模型 训练器)bge模型微调流程】 https://www.bilibili.com/video/BV1eu4y1x7ix/?share_source=copy_web&vd_source=97da61a87d5a14ca15b351252ae0f105
代码结构
从https://github.com/FlagOpen/FlagEmbedding拉取代码,代码结构如下(在linux中查看结构的命令:tree -d):

我大致跑了两个部分的代码:baai_general_embedding和reranker。
环境安装
按照readme的说明,首先创建一个conda虚拟环境,然后拉取源码后,通过pip install -e .来安装BGE包。这种方法的好处是可以方便地修改源代码,更好地用于调试、开发。
baai_general_embedding
我们先跑一遍baai_general_embedding中finetune的流程。
关于baai_general_embedding中finetune的readme文档,位于路径examples/finetune下。
config.json配置
如果是在命令行运行代码来执行微调,则运行命令是(在FlagEmbedding路径下执行)
torchrun --nproc_per_node {number of gpus} \
-m FlagEmbedding.baai_general_embedding.finetune.run \
--output_dir {path to save model} \
--model_name_or_path BAAI/bge-large-zh-v1.5 \
--train_data ./toy_finetune_data.jsonl \
--learning_rate 1e-5 \
--fp16 \
--num_train_epochs 5 \
--per_device_train_batch_size {large batch size; set 1 for toy data} \
--dataloader_drop_last True \
--normlized True \
--temperature 0.02 \
--query_max_len 64 \
--passage_max_len 256 \
--train_group_size 2 \
--negatives_cross_device \
--logging_steps 10 \
--query_instruction_for_retrieval "" 如果我想要在vscode调试这行代码,应该在config.json中如下设置:
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "/opt/conda/envs/bge/lib/python3.9/site-packages/torch/distributed/launch.py",
// "program": "run.py",
"console": "integratedTerminal",
"cwd": "/home/notebook/code/personal/aigc/bge/FlagEmbedding",
"args": [
"--nproc_per_node=2",
"-m","FlagEmbedding.baai_general_embedding.finetune.run",
"--output_dir","/home/notebook/code/personal/aigc/bge/FlagEmbedding/myresult",
"-- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3822
3822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









